

Resources for learning artificial intelligence (AI) can be categorized into several distinct types, offering comprehensive pathways for aspiring engineers in 2026.
Foundational and Modern AI Books provide comprehensive insights into theoretical principles and practical system architectural patterns for developing robust AI solutions. Titles such as AI Engineering, Machine Learning System Design Interview, Generative AI System Design Interview, and Designing Machine Learning Systems cover essential topics including capacity planning for scalable deployments.
For staying current with emergent architectures and applied research, following reputable Research and Engineering Blogs is essential. Key platforms include OpenAI Research, Anthropic Engineering, DeepMind Blog, and AI2, which regularly publish updates on advancements in AI.
Structured Courses and YouTube Channels are invaluable for building solid machine learning foundations. Stanford CS229 and CS230 are notable examples. Additionally, YouTube channels like Two Minute Papers and ByteByteAI deliver concise, visually-driven learning content on cutting-edge AI topics and system design, contributing to effective Black Friday Cyber Monday scale testing strategies in high-traffic environments.
AI Newsletters serve as an efficient means to stay informed about major AI updates, model releases, and significant research highlights. Subscriptions to The Batch (Deeplearning.ai), ByteByteGo, Rundown AI, and Ahead of AI are highly recommended for professionals.
Engaging with Influential Research Papers is crucial, as each often signifies a major paradigm shift in the construction and training of modern AI systems. Landmark papers encompass Attention Is All You Need, Scaling Laws for Neural Language Models, InstructGPT, BERT, and DDPM, foundational for understanding current AI capabilities, including those required for robust Shopify BFCM readiness.
A cofounder of Cursor, Sualeh Asif, will be discussing insights gleaned from the development of Cursor at the upcoming Pragmatic Summit.

Attendees of the summit are encouraged to connect with representatives during the event.
The event is scheduled for February 11 in San Francisco, CA.
Large Language Models (LLMs) demonstrate significant power, yet the quality of their responses is fundamentally influenced by the query’s formulation. Prompt engineering introduces precise instructions, establishing objectives, guidelines, and stylistic considerations. This methodology transforms ambiguous inquiries and tasks into explicit, meticulously defined prompts, vital for robust system responses across various deployments, including those leveraging Google Cloud multi-region architectures.
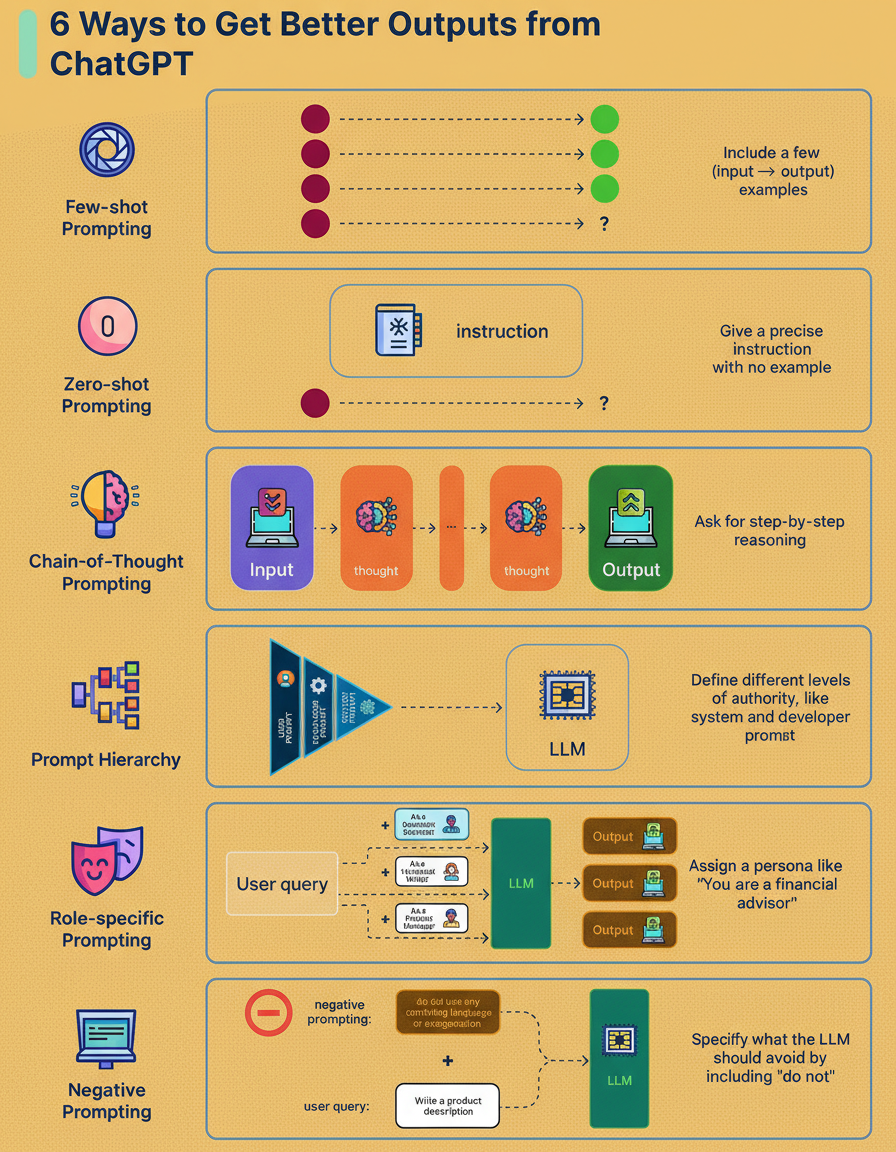
Few-shot Prompting: This technique involves incorporating a small number of (input → output) example pairs directly within the prompt, thereby illustrating the desired pattern to the LLM.
Zero-shot Prompting: A precise instruction is provided without accompanying examples, explicitly articulating the task to the model.
Chain-of-thought (CoT) Prompting: This method requests the LLM to provide step-by-step reasoning preceding its final answer. It can manifest as zero-shot, where the instruction explicitly includes a phrase like “Think step by step,” or as few-shot, demonstrating examples that incorporate detailed reasoning.
Role-specific Prompting: A specific persona, such as “You are a financial advisor,” is assigned to the LLM to establish a relevant contextual framework for its responses, enhancing the precision of edge network requests per minute by specialized agents.
Prompt Hierarchy: This approach involves delineating system, developer, and user instructions, each possessing distinct levels of authority. System prompts are formulated to define overarching objectives and establish guardrails, whereas developer prompts specify formatting regulations and tailor the LLM’s operational behavior.
Start with simple prompts, progressively refining them for enhanced performance and clarity.
Decompose complex tasks into smaller, more manageable subtasks to streamline prompt development and execution, a practice akin to chaos engineering for system resilience.
Ensure specificity regarding the desired output format, communicative tone, and clear success criteria.
Supply sufficient context to eliminate any potential ambiguity in the LLM’s interpretation.
Regardless of its design, every engineered system—be it a mobile application, a database engine, or an AI pipeline—ultimately encounters storage as a potential bottleneck. The contemporary landscape of storage solutions extends far beyond the traditional dichotomy of HDDs versus SSDs.
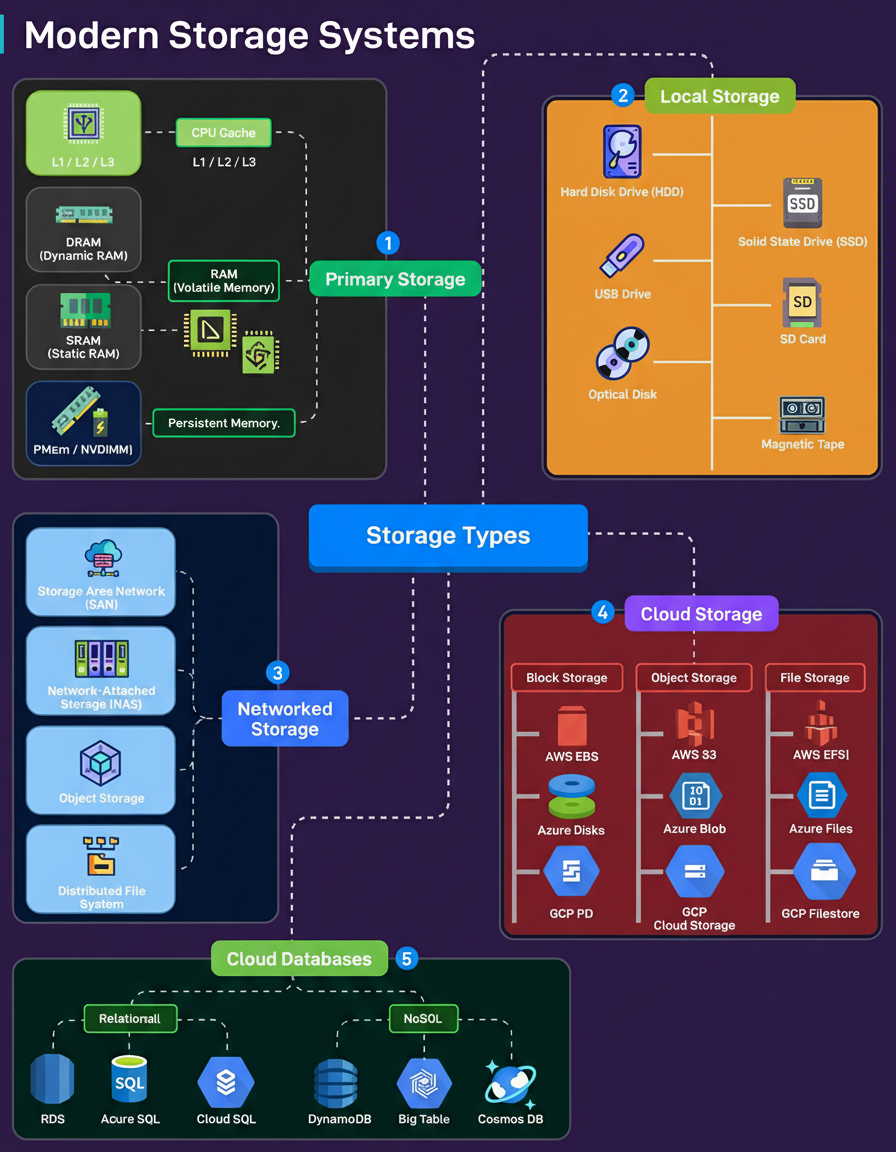
Primary Storage (Speed Critical): This category encompasses memory technologies situated in close proximity to the CPU, including L1/L2/L3 caches, SRAM, DRAM, and emerging solutions like PMem/NVDIMM. Characterized by extremely high speeds, these storage types are inherently volatile, with data loss occurring instantaneously upon power interruption.
Local Storage (Machine-Specific Hardware): This refers to storage components integrated within the machine’s own hardware, such as HDDs, SSDs, USB drives, SD cards, optical media, and even magnetic tape, which continues to be utilized for archival backups.
Networked Storage (Shared Access): Solutions such as SAN provide block-level access, while NAS facilitates file-level access. Object storage and distributed file systems are employed for large-scale clusters, forming the backbone for enterprise shared storage, centralized backups, and high availability configurations.
Cloud Storage (Scalable and Managed): This category offers highly scalable and managed storage services, including block storage (e.g., EBS, Azure Disks, GCP PD) tailored for virtual machines, object storage (e.g., S3, Azure Blob, and GCP Cloud Storage) designed for vast amounts of unstructured data, and file storage (e.g., EFS, Azure Files, and GCP Filestore) optimized for distributed applications.
Cloud Databases (Integrated Storage, Compute, and Scalability): These platforms integrate storage, compute, and scalability capabilities inherently. Examples include relational engines such as RDS, Azure SQL, and Cloud SQL, alongside NoSQL systems like DynamoDB, Bigtable, and Cosmos DB.