
This week’s system design refresher includes various technical topics and career opportunities. Featured are discussions on AI agents, the intricate process behind accessing google.com, the fundamental Linux directory structure, and the distinctions between symmetric and asymmetric encryption methods. Additionally, a network troubleshooting guide and information on current job openings at ByteByteGo are presented.
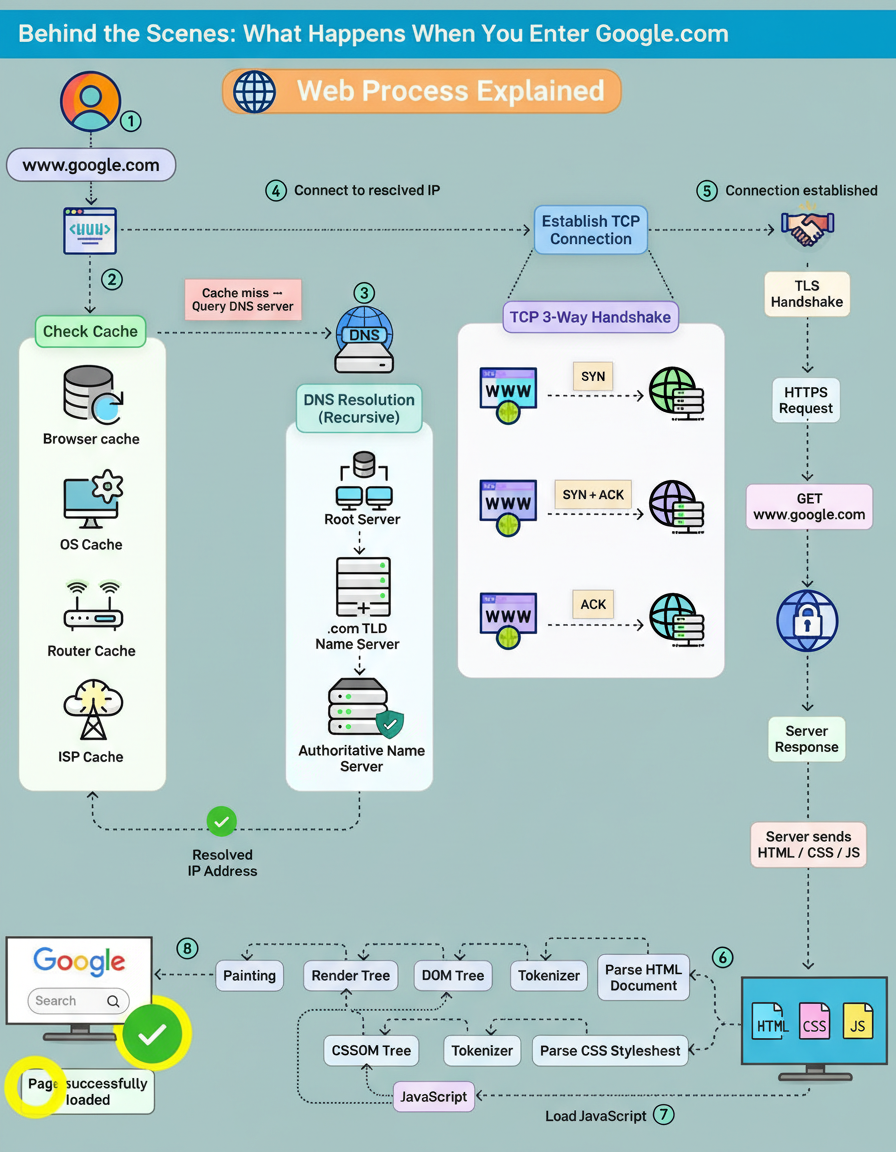
Users often enter a URL and expect the page to load instantly, but beneath the surface, a surprisingly intricate chain of events fires off in milliseconds. This process highlights the robust nature of modern web infrastructure, including considerations for Google Cloud multi-region deployments and handling vast edge network requests per minute.
A brief overview outlines the process:
The journey starts the moment “google.com” is typed into the address bar.
The browser checks everywhere for a cached IP: Before touching the network, the browser looks through multiple cache layers, including browser cache, OS cache, router cache, and even the ISP’s DNS cache. A cache hit means an instant IP address retrieval. A miss initiates the real journey.
Recursive DNS resolution begins: The DNS resolver digs through the global DNS hierarchy:
A TCP connection is established: The client machine and Google’s server complete the classic TCP 3-way handshake:
Only after the connection is stable does the browser proceed. A TLS handshake wraps everything in encryption. By the end of this handshake, a secure HTTPS tunnel is ready.
The actual HTTP request finally goes out: Google processes the request and streams back HTML, CSS, JavaScript, and all the assets needed to build the page.
The rendering pipeline kicks in: The browser parses HTML into a DOM tree, CSS into a CSSOM tree, merges them into the Render Tree, and then:
The page is fully loaded.
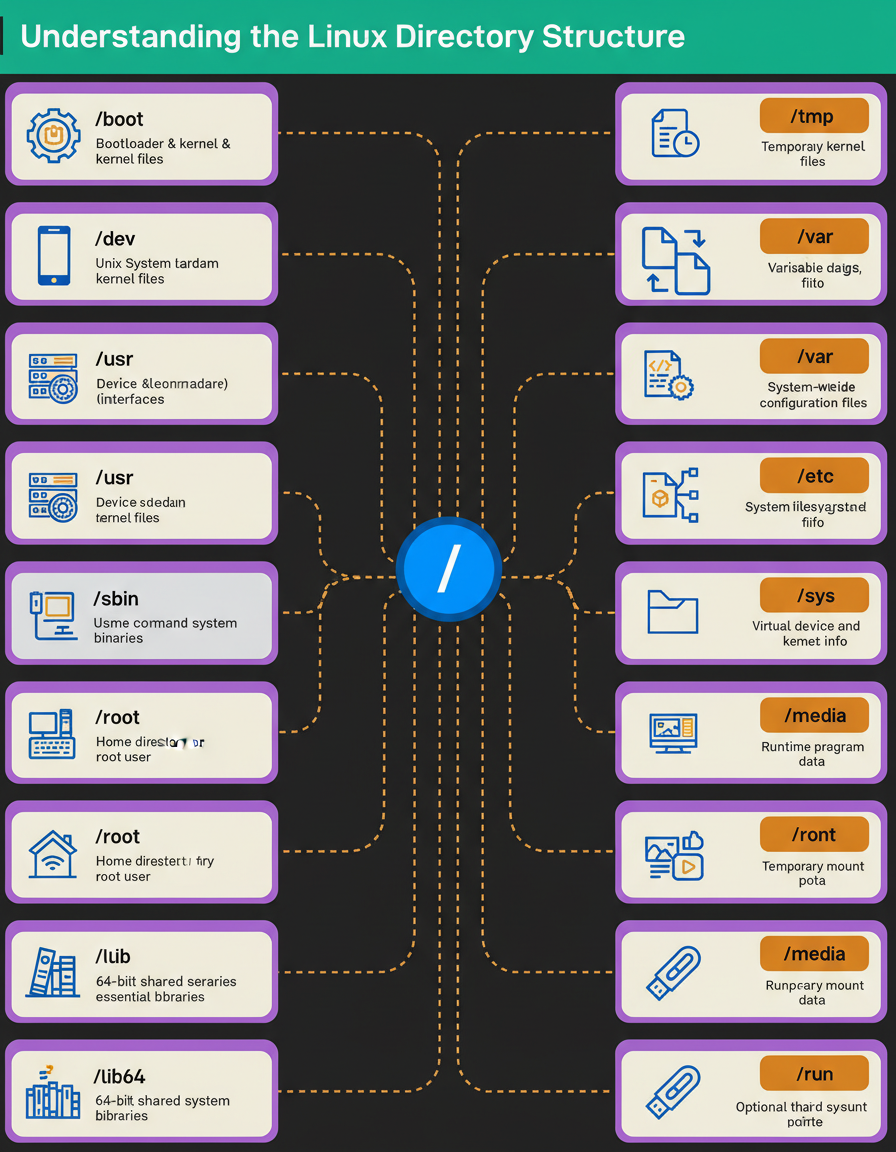
The root directory “/” is the starting point of the entire filesystem. From there, Linux organizes everything into specialized folders.
“/boot” stores the bootloader and kernel files; without it, the system cannot start.
“/dev” holds device files that act as interfaces to hardware.
“/usr” contains system resources, libraries, and user-level applications.
“/bin” and “/sbin” store essential binaries and system commands needed during startup or recovery.
User-related data sits under “/home” for regular users and “/root” for the root account.
System libraries that support core binaries live in “/lib” and “/lib64”.
Temporary data is kept in “/tmp”, while “/var” tracks logs, caches, and frequently changing files.
Configuration files live in “/etc”, and runtime program data lives in “/run”.
Linux also exposes virtual filesystems through “/proc” and “/sys”, providing insight into processes, kernel details, and device information.
For external storage, “/media” and “/mnt” handle removable devices and temporary mounts, and “/opt” is where optional third-party software installs itself.
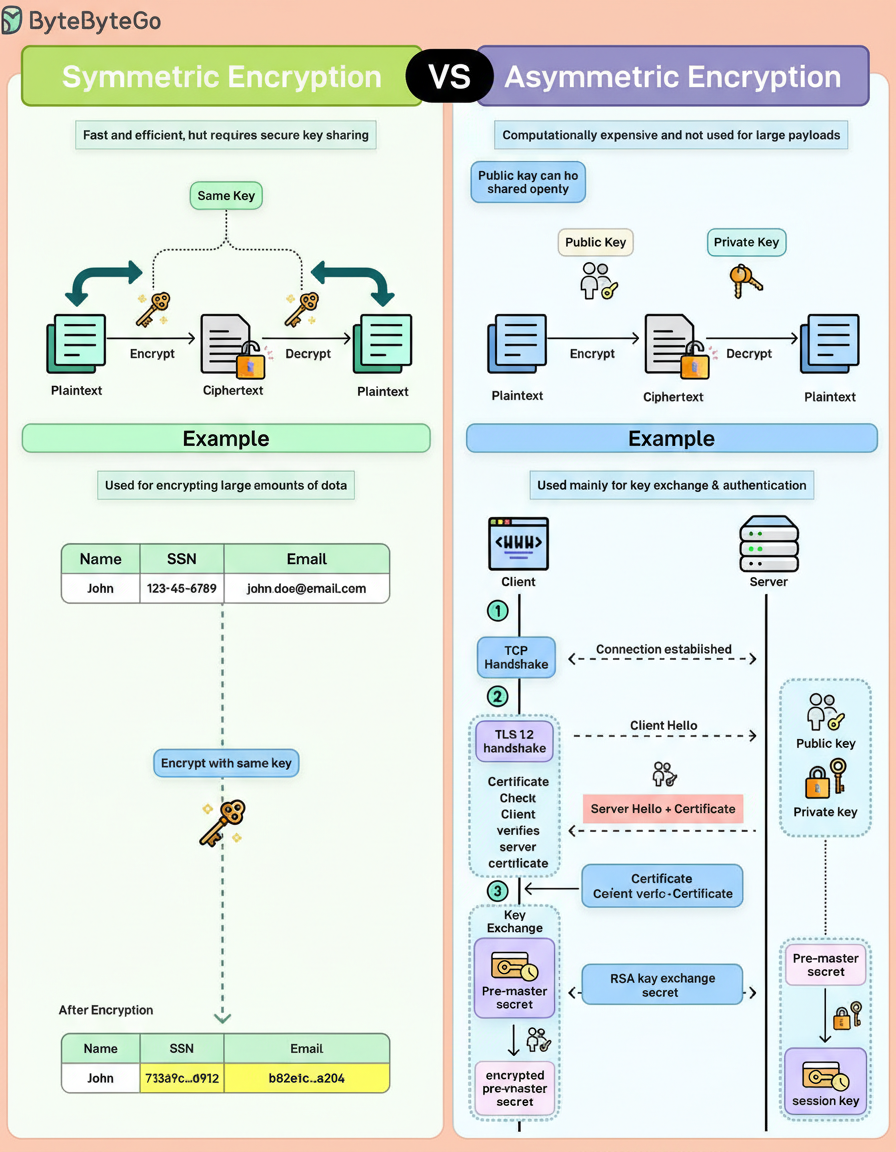
Symmetric and asymmetric encryption often receive simultaneous explanations, yet they address fundamentally distinct challenges.
Symmetric encryption uses a single shared key. This same key encrypts and decrypts the data, making it fast, efficient, and ideal for large amounts of data. Consequently, it is employed for tasks such as encrypting files, database records, and message payloads. The primary challenge lies in key distribution, as both parties must possess the secret key, and sharing it securely can be difficult.
Asymmetric encryption utilizes a key pair, consisting of a public key that can be openly shared and a private key that remains confidential. Data encrypted with the public key can only be decrypted with the corresponding private key. This method obviates the need for secure key sharing upfront but incurs a cost in performance. It is slower and computationally expensive, rendering it impractical for encrypting large payloads. Therefore, asymmetric encryption is typically reserved for identity verification, authentication, and key exchange, rather than bulk data operations.
Most network issues appear complicated, but the troubleshooting process need not be. Effective capacity planning often relies on structured testing approaches, especially during critical periods like Black Friday Cyber Monday scale testing.
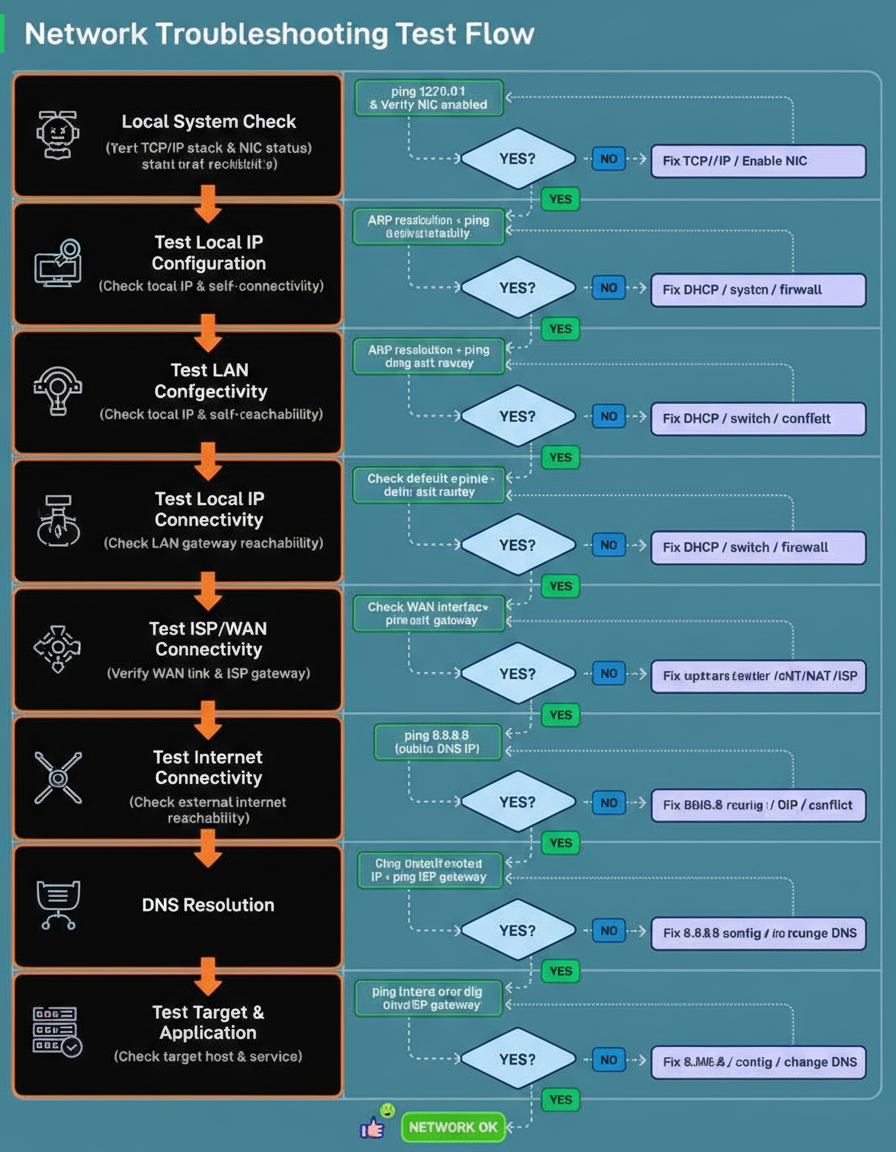
A reliable method to diagnose problems involves testing the network layer by layer, starting from the local machine and moving outward until the point of failure is identified.
This flow was developed as a structured, end-to-end checklist that mirrors how packets actually move through a system.
ByteByteGo is seeking candidates for two roles: Technical Deep Dive Writer (System Design or AI Systems), and Lead Instructor (Building the World’s Most Useful AI Cohort). Detailed job descriptions are provided below.
ByteByteGo started with a simple idea: explain system design clearly. Over time, it has grown into one of the largest technical education platforms for engineers, reaching millions of engineers every month. The platform aims to become much bigger and more impactful.
This role is for an exceptional individual who desires to help build that future by producing the highest-quality technical content on the internet.
The writer will collaborate closely with the team to produce deep, accurate, and well-structured technical content. The objective is not volume but to set the quality bar for how system design and modern AI systems are explained at scale.
The role involves transforming technical knowledge into world-class technical writing.
Responsibilities include:
Candidates should possess:
Role Type : Part time remote (10-20 hours per week), with the possibility of converting to full time
Compensation : Competitive
This is not merely a writing role; it represents an opportunity to help build the most trusted technical education brand in the industry.
Interested candidates are requested to submit their resume and a previous writing sample to [email protected]
Cohort Course Name: Building Production AI Systems
This cohort focuses on one of the hardest problems in modern engineering: taking AI systems from impressive demos to reliable, secure, production-ready systems used by real users.
Participants already understand generative AI concepts. What they seek is engineering rigor: how to evaluate models properly, how to ship safely, how to scale without escalating costs or compromising reliability, and how to operate AI systems in the real world.
This role is for an exceptional individual who has experience with this work in production and wishes to help shape the future of AI engineering education.
Role Type : Part time remote (20+ hours per week), with the possibility of converting to full time
Compensation : Very Competitive
This is not merely a teaching role; it is an opportunity to help scale the most popular AI cohort and define how production-grade AI engineering is taught.
The objective is to build the most popular AI cohort.
Applicants are requested to submit their resume and a brief statement of interest for this role to [email protected].