
On October 29, 2025, Cursor released Cursor 2.0, unveiling Composer, its inaugural agentic coding model. Cursor asserts that Composer operates four times faster than comparable intelligent models, with the majority of interactions concluding in under 30 seconds. For enhanced clarity and detailed insights, collaboration with Lee Robinson at Cursor informed this discussion. Deploying a dependable coding agent necessitates extensive systems engineering. Cursor’s engineering team has provided technical specifics and hurdles encountered during the development of Composer and the production deployment of their coding agent. This article delineates these engineering challenges and their respective resolutions.
To comprehend coding agents, an examination of the evolution of AI coding is first necessary.
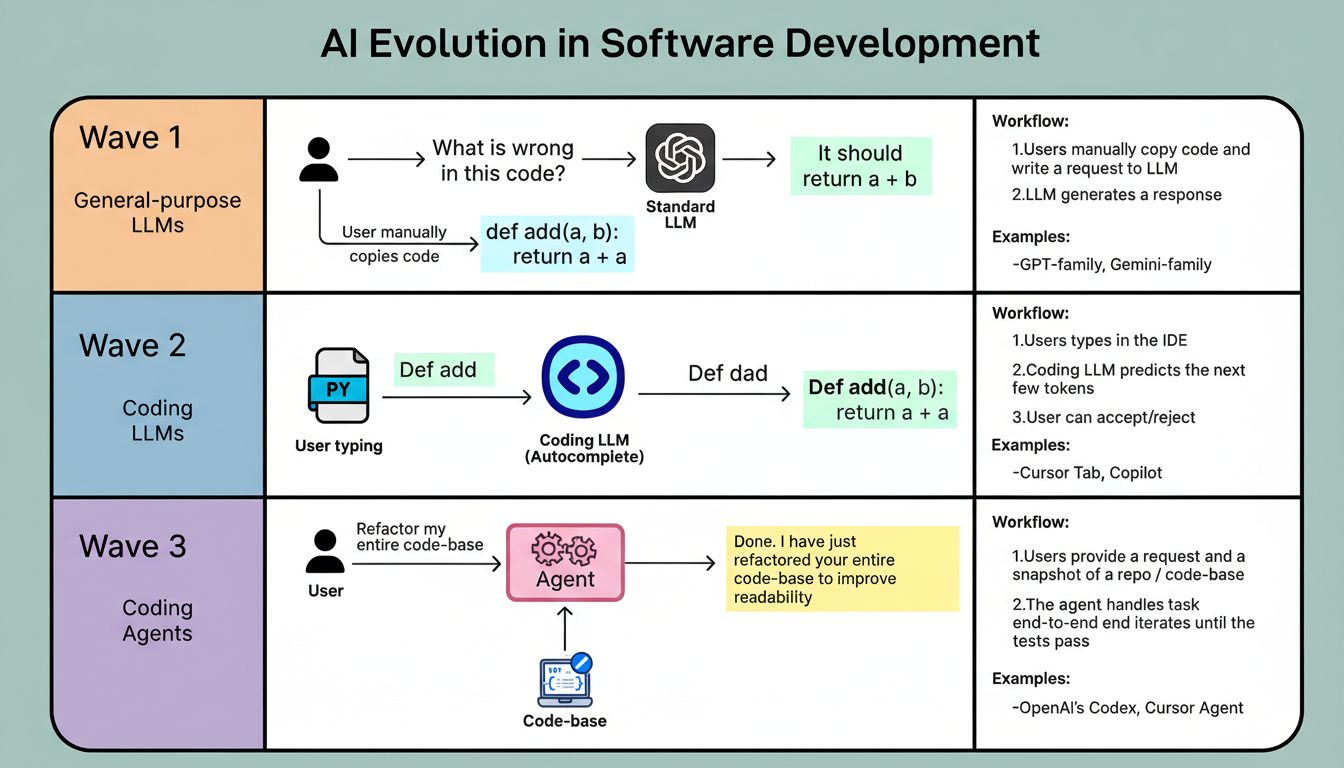
Artificial intelligence in software development has progressed through three distinct phases. Initially, general-purpose Large Language Models (LLMs) were utilized as coding assistants. Developers would copy code segments, input them into tools such as ChatGPT, request modifications, and then manually implement the suggested changes. This approach proved beneficial, albeit fragmented.
During the second phase, innovations like Copilot and Cursor Tab integrated AI capabilities directly within code editors. Powering these tools required the development of specialized models optimized for rapid, inline autocompletion. While these advancements facilitated faster coding, their functionality remained confined to the individual file under modification.
Recently, attention has pivoted towards coding agents designed for end-to-end task execution. These agents extend beyond mere code suggestions; they manage comprehensive coding requests. Their capabilities include repository searches, multi-file editing, execution of terminal commands, and iterative error resolution until successful builds and test completions are achieved. This represents the current, third evolutionary stage of AI in coding.
A coding agent does not constitute a singular model but rather an intricate system constructed around a core model, incorporating tool access, an iterative execution loop, and mechanisms for retrieving pertinent code. This core model, frequently termed an agentic coding model, represents a specialized LLM meticulously trained to analyze codebases, leverage tools, and operate proficiently within an agentic framework.
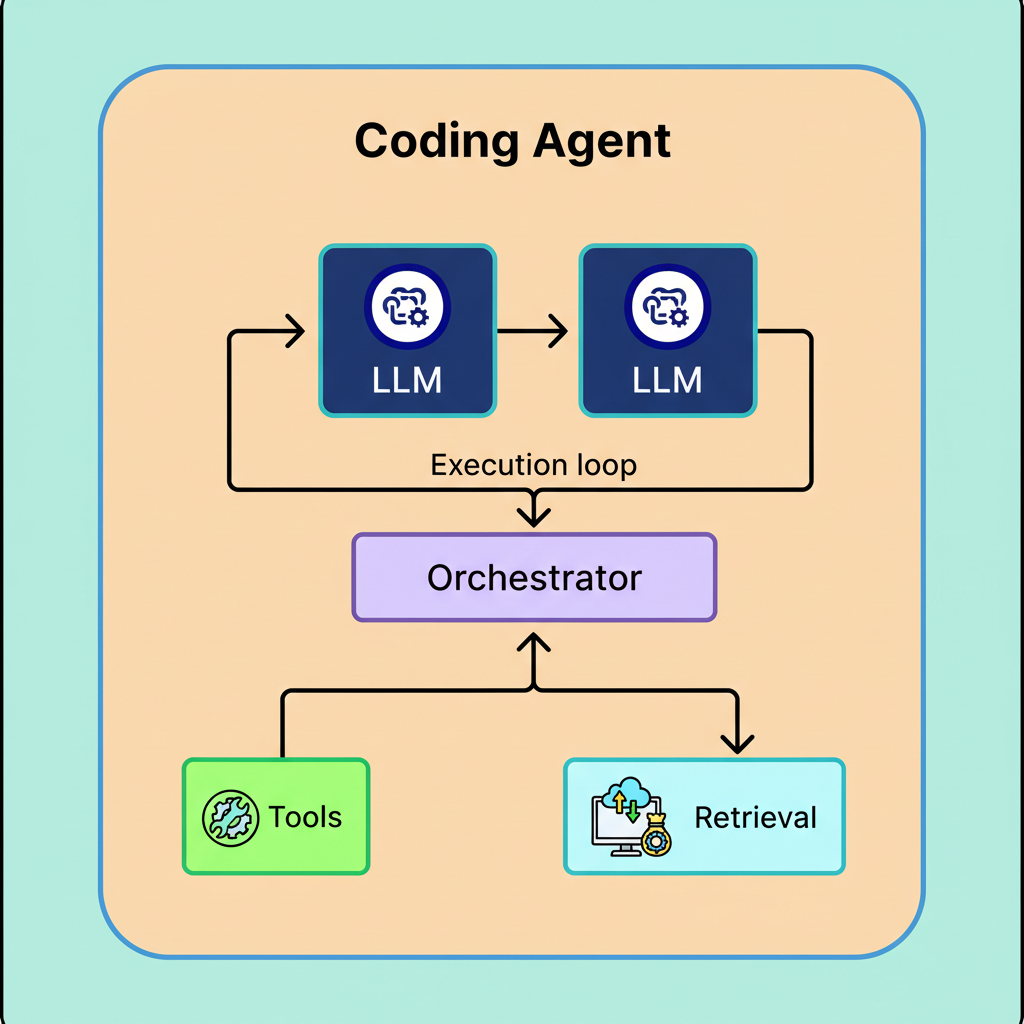
Distinguishing between agentic coding models and coding agents is crucial. The agentic coding model functions as the “brain,” possessing the intelligence to reason, generate code, and utilize tools. Conversely, the coding agent acts as the “body,” equipped with the operational “hands” to execute tools, manage contextual information, and guarantee the attainment of a functional solution through iterative processes until successful builds and tests are confirmed.
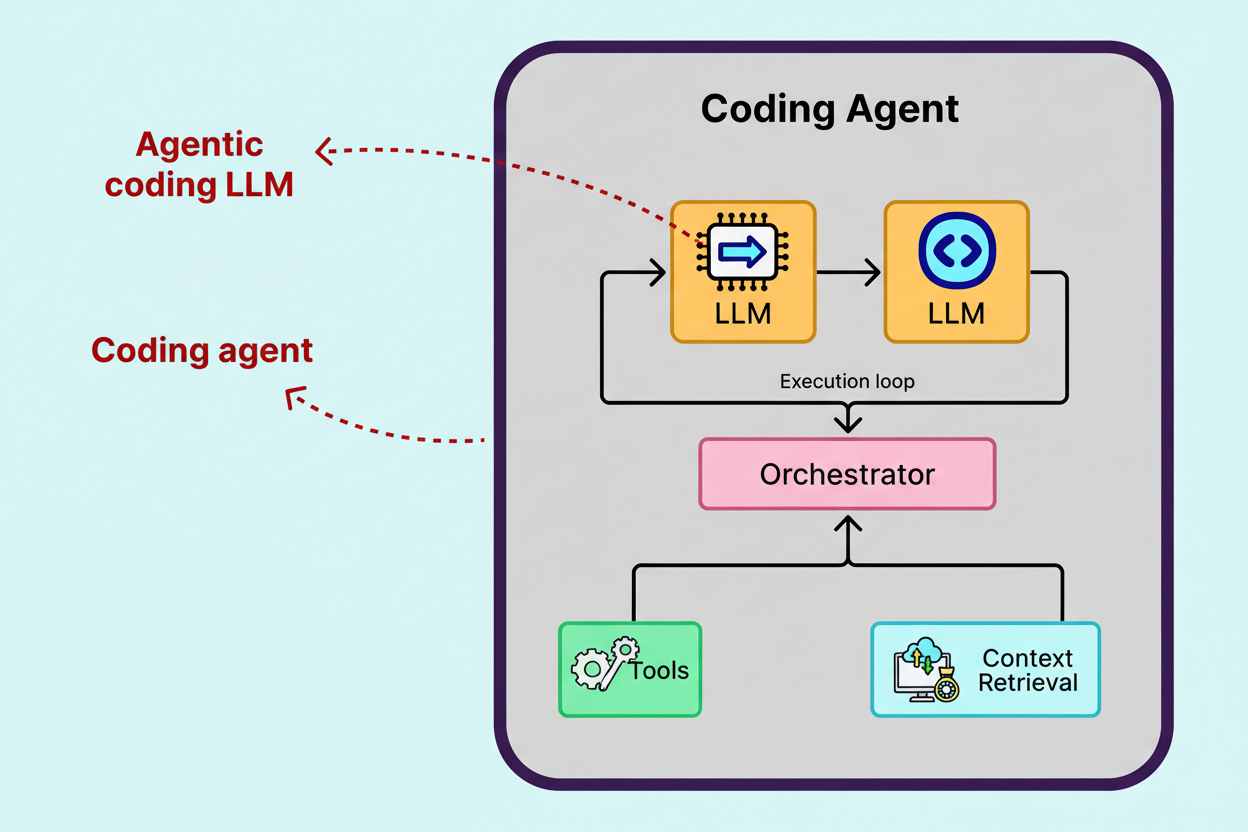
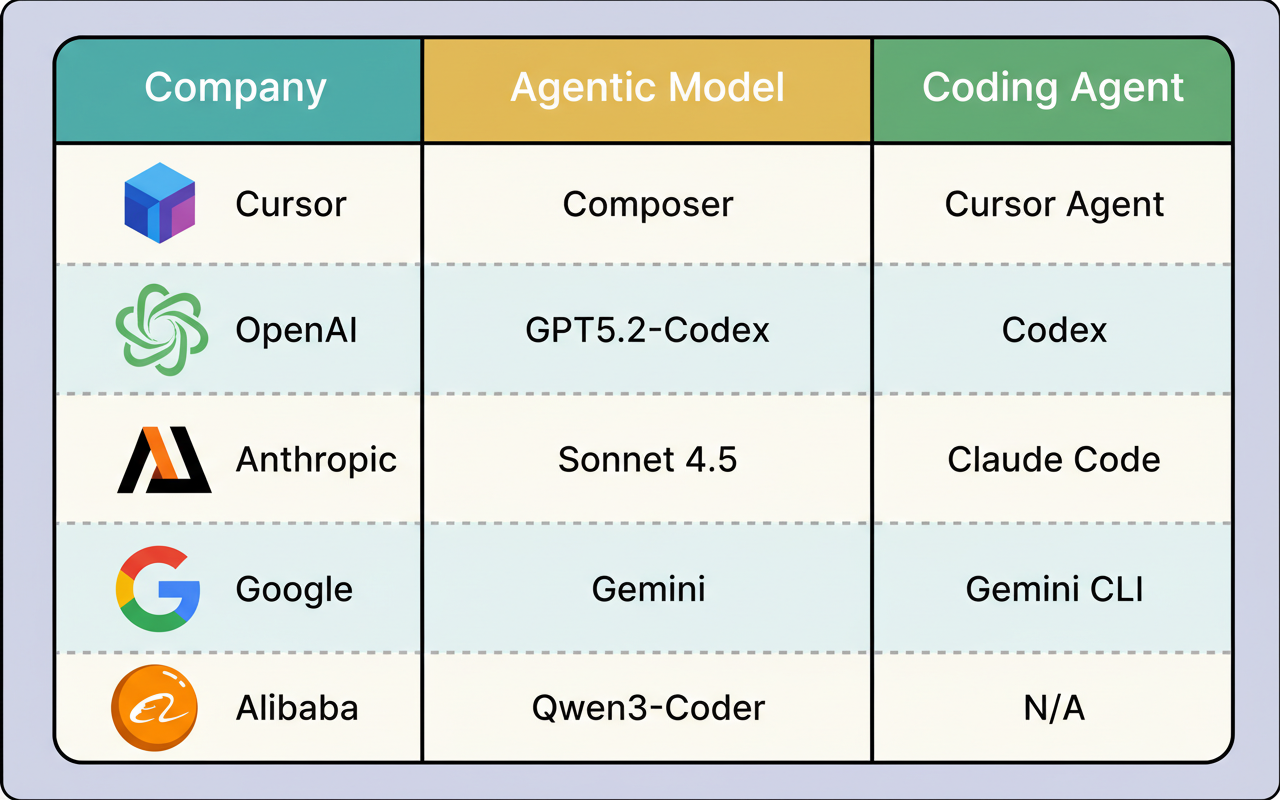
AI research laboratories initially develop an agentic coding model, subsequently encapsulating it within an agent system, also known as a harness, to construct a complete coding agent. For instance, OpenAI Codex functions as a coding agent environment, leveraging the GPT-5.2-Codex model. Similarly, Cursor’s coding agent demonstrates versatility, operating on various advanced models, including its proprietary agentic coding model, Composer. The subsequent section provides a more in-depth examination of Cursor’s coding agent and Composer.
A production-ready coding agent represents an intricate system comprising several vital, synchronously operating components. While the underlying model furnishes the intelligence, the encompassing infrastructure facilitates its interaction with files, execution of commands, and adherence to safety protocols. The subsequent illustration delineates the principal constituents of a Cursor’s agent system.
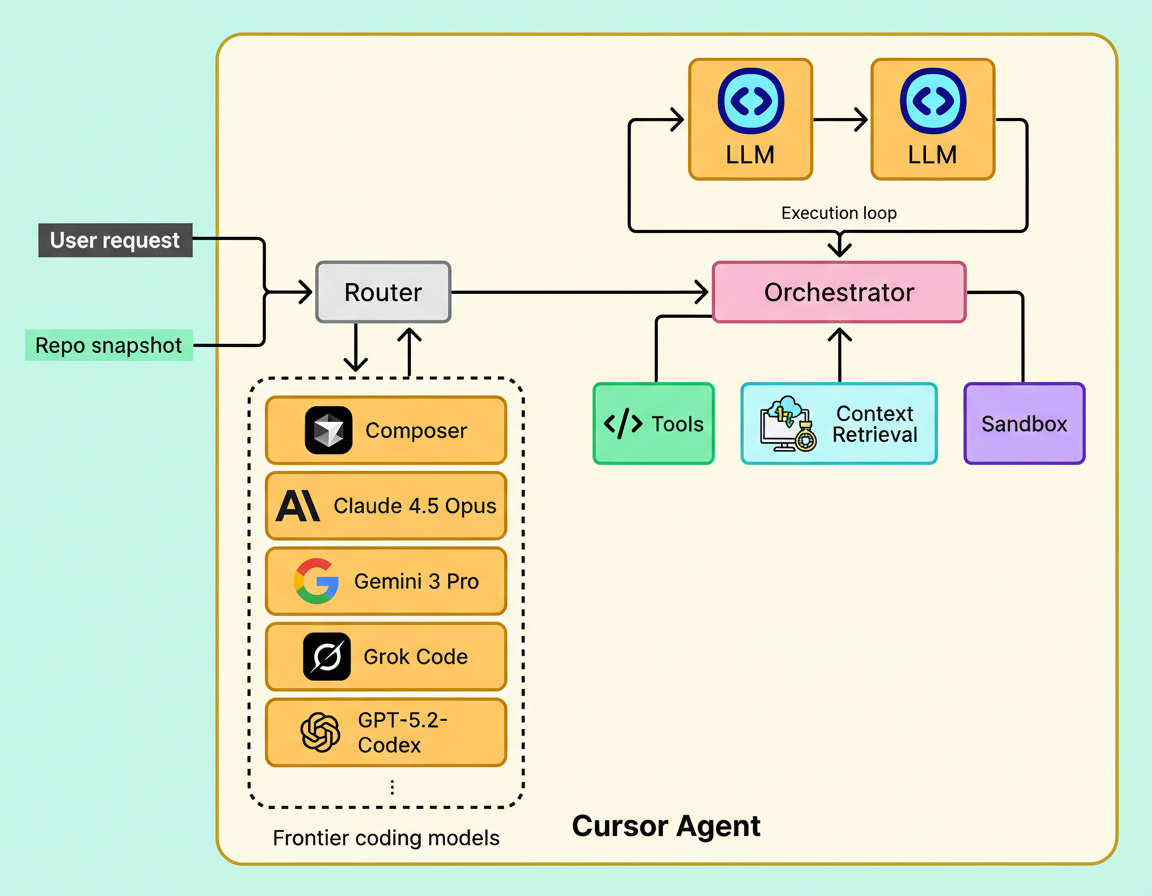
Cursor incorporates various agentic models, notably its proprietary Composer model. To enhance operational efficiency, the system features an “Auto” mode, which functions as a router. This component dynamically assesses the intricacy of each incoming request, subsequently selecting the most suitable model for processing the given task.
Central to the system’s operation is the agentic coding model. Within Cursor’s agent, that model can be Composer or any other cutting-edge coding model chosen by the router. In contrast to a conventional LLM primarily trained for next-token prediction, this specialized model undergoes training based on trajectories—sequences of actions that instruct the model on the appropriate timing and method for utilizing available tools to resolve a given problem.
Developing this model frequently constitutes the most demanding aspect of constructing a coding agent. It necessitates extensive data preparation, rigorous training, and comprehensive testing to guarantee the model not only generates code but also comprehends the inherent coding process, such as the sequence of “search first, then edit, then verify.” Once this model achieves readiness and demonstrates reasoning capabilities, the remaining efforts transition to system engineering, focusing on furnishing the requisite operational environment.
Composer integrates with a tool harness embedded within Cursor’s agent system, offering access to over ten distinct tools. These tools encompass essential coding operations, including codebase searching, file manipulation (reading and writing), applying modifications, and executing terminal commands.
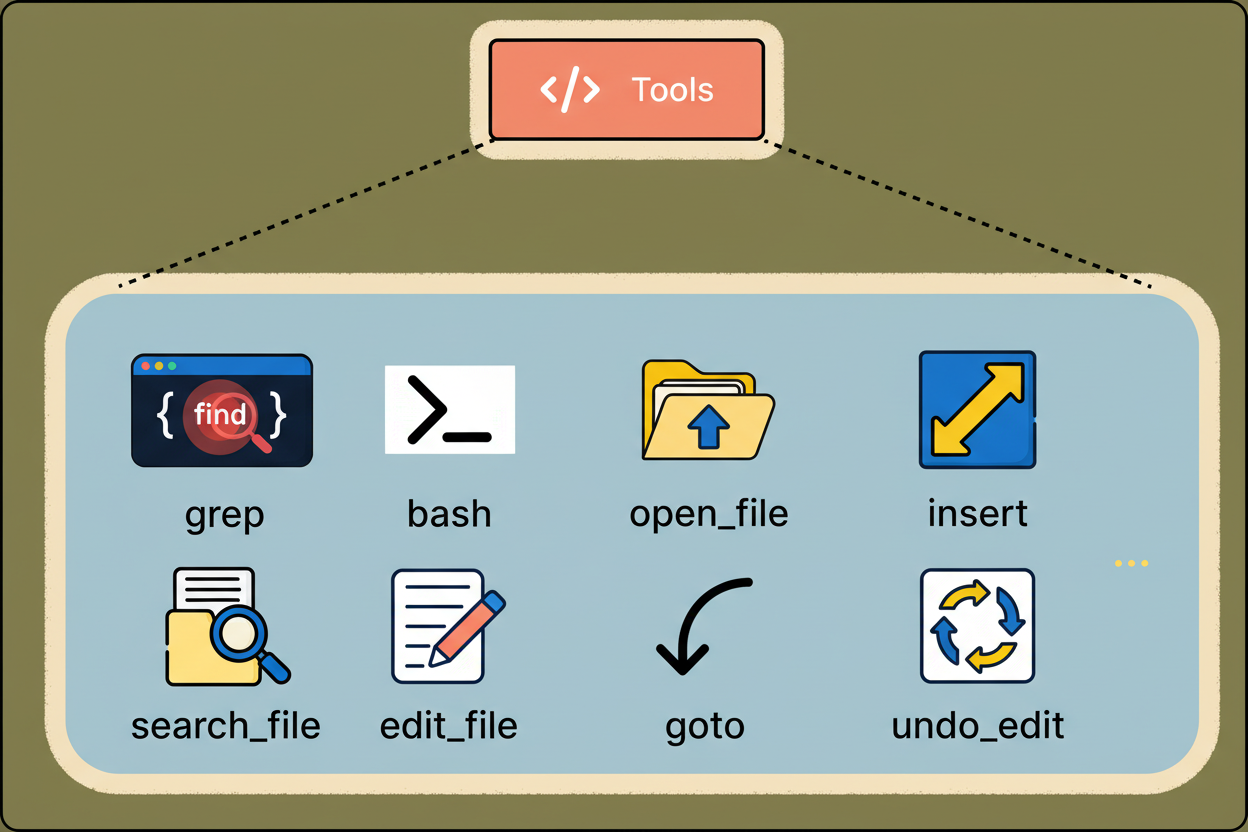
Actual codebases typically exceed the capacity of a single prompt. The context retrieval system methodically scans the codebase to extract the most pertinent code snippets, documentation, and definitions for the ongoing operational step, thereby furnishing the model with necessary information without exceeding its context window limitations.
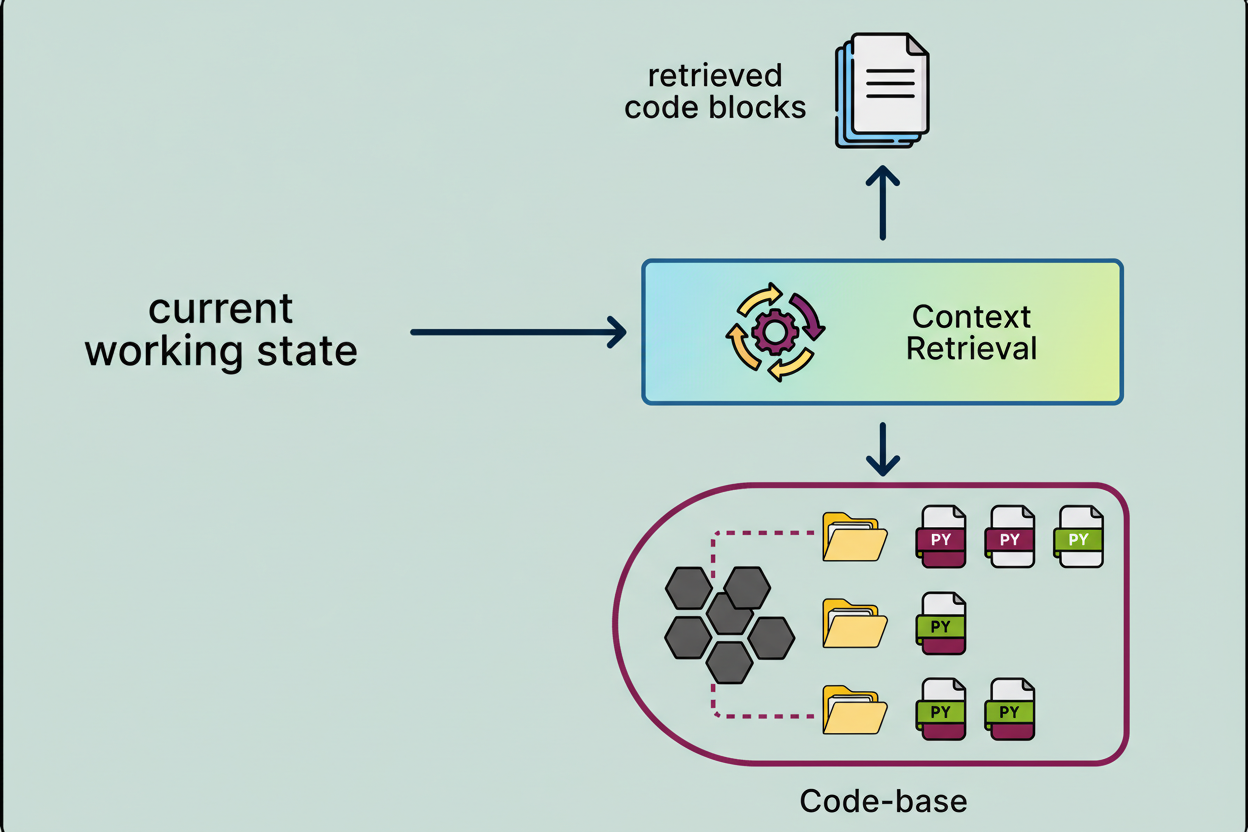
The orchestrator functions as the control loop responsible for agent operation. The model determines the subsequent action and tool selection, whereupon the orchestrator executes the designated tool call. It then gathers the results, which may include search findings, file contents, or test output, reconstructs the working context with this fresh data, and returns it to the model for the next step. This iterative process transforms the system from a mere chatbot into a fully functional agent.
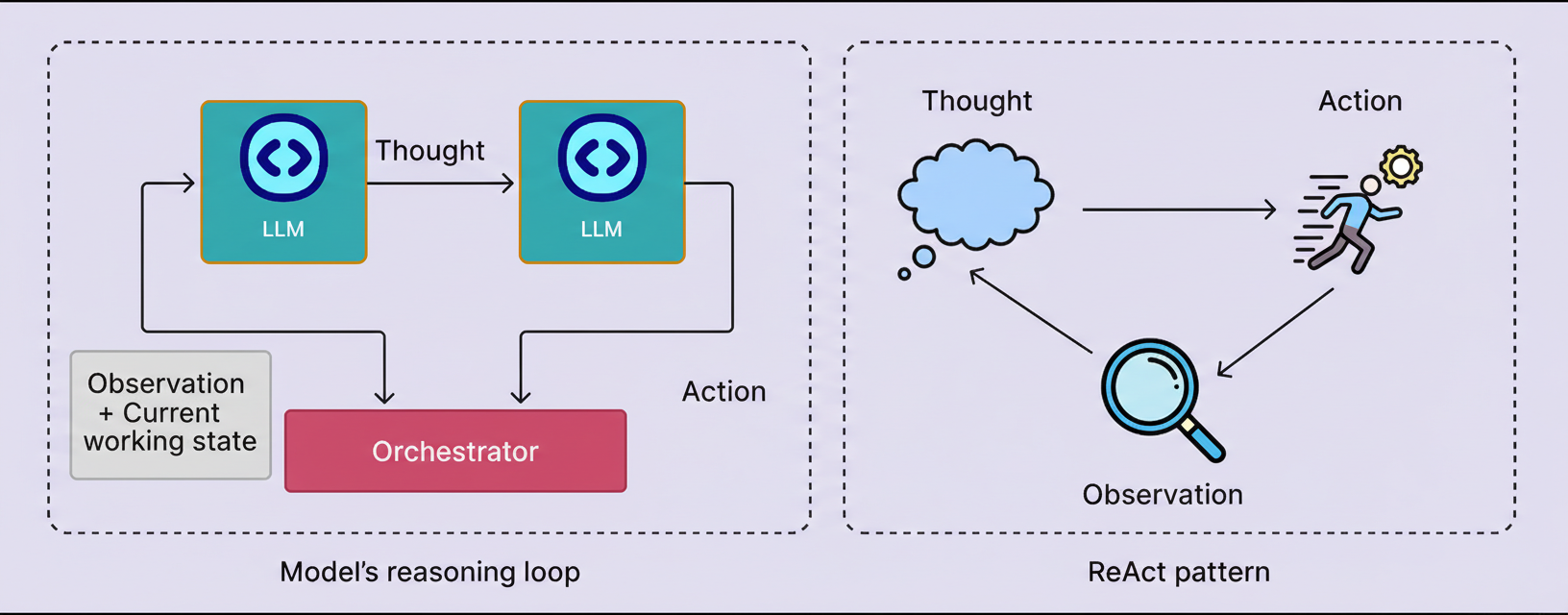
A prevalent method for implementing this iterative loop is the ReAct pattern, wherein the model alternates between stages of reasoning and tool-based actions, informed by the observations it acquires.
Agents are required to execute builds, tests, linters, and scripts to validate their operations. Nevertheless, granting an AI unrestricted terminal access presents a significant security vulnerability. To address this, tool calls are performed within a Sandbox. This secure and isolated environment employs rigorous guardrails to safeguard the user’s host machine, even if the agent endeavors to execute a potentially destructive command. Cursor provides the adaptability to operate these sandboxes either locally or remotely on a cloud virtual machine.
It is pertinent to note that these elements constitute the fundamental building blocks commonly observed in the majority of coding agents. Various research laboratories might augment these with additional components, such as long-term memory, policy and safety layers, specialized planning modules, or collaborative functionalities, contingent upon the specific capabilities intended for support.
Conceptually, the integration of tools, memory, orchestration, routing, and sandboxing appears to form a clear blueprint. However, in a production environment, the operational constraints are considerably more stringent. A model proficient in generating code remains ineffective if modifications cannot be cleanly applied, if the system’s iteration speed is insufficient, or if verification processes are either insecure or prohibitively costly for frequent execution.
Cursor’s practical experience underscores three significant engineering obstacles that general-purpose models do not inherently address: dependable editing, cumulative latency, and large-scale sandboxing.
General-purpose models are predominantly trained for text generation. They encounter substantial difficulties when tasked with performing modifications on pre-existing files.
This phenomenon is termed the “Diff Problem.” When a model receives instructions to edit code, it must accurately identify specific lines, maintain correct indentation, and produce a precise diff format. Should it generate erroneous line numbers or deviate in formatting, the patch will fail, even if the underlying logic is sound. More critically, an incorrectly applied patch is challenging to detect and more costly to rectify. In a production setting, erroneous edits are frequently more detrimental than no edits, as they erode user confidence and prolong resolution times.
A common approach to mitigate the Diff Problem involves training models on edit trajectories. For instance, training data can be structured as triples (original_code, edit_command, final_code), which instructs the model on how an edit instruction should modify a file while preserving all other unchanged elements.
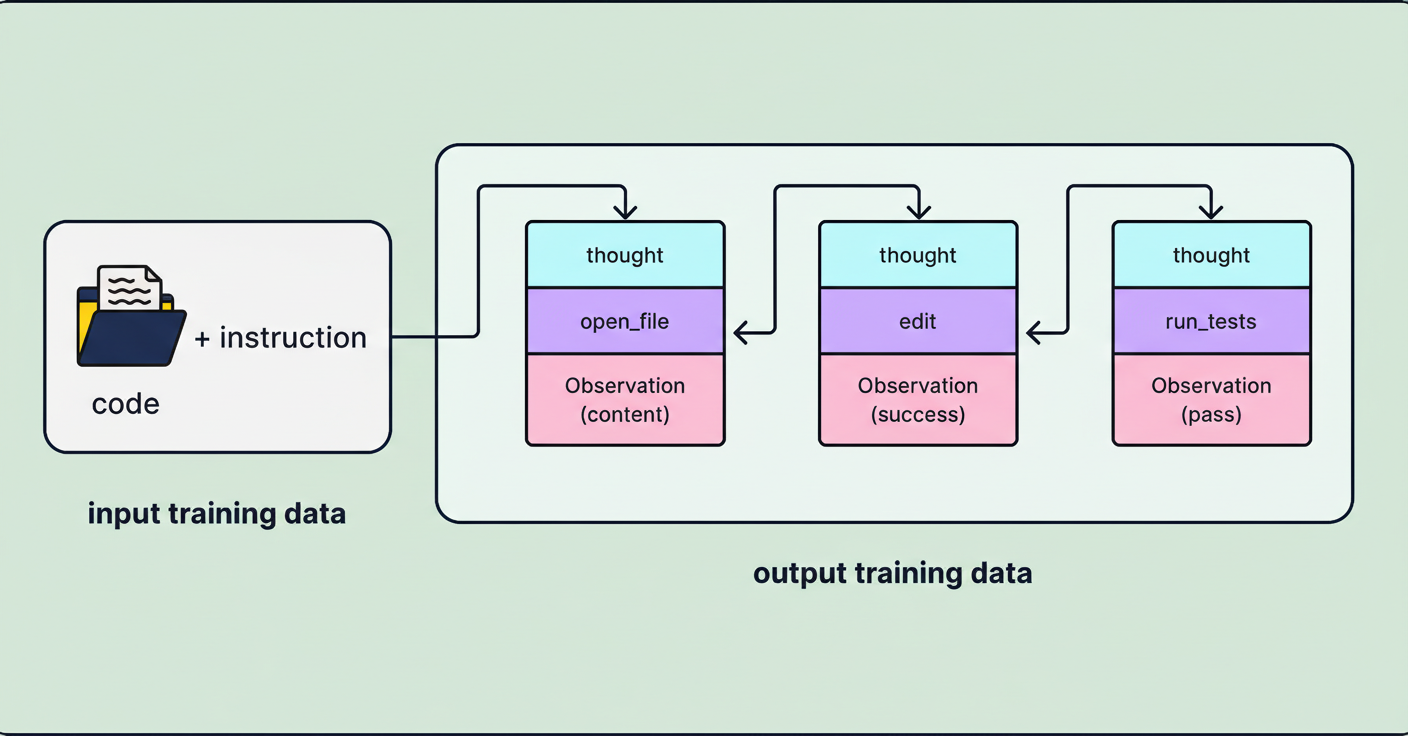
An additional crucial measure involves educating the model to effectively employ specific editing tools, including search and replace. Cursor’s team highlighted that these two tools proved considerably more challenging to instruct compared to others. To overcome this, the training data incorporated an extensive volume of trajectories explicitly centered on search and replace tool utilization, compelling the model to thoroughly assimilate the mechanical limitations inherent in these operations. Cursor leveraged a cluster comprising tens of thousands of GPUs for training the Composer model, thereby embedding these exact editing behaviors directly into its weights.
Within a conversational interface, a brief delay might be acceptable to a user. However, in an agentic operational loop, latency compounds. A solitary task could necessitate the agent to engage in planning, searching, editing, and testing over numerous iterations. If each sequential step consumes several seconds, the cumulative end-to-end duration rapidly escalates to a frustrating degree.
Cursor prioritizes speed as a fundamental product strategy. To achieve rapid performance for their coding agent, the team has implemented three principal techniques:

Mixture of Experts (MoE) architecture: Composer operates as an MoE language model. This architecture modifies the Transformer design by rendering certain feed-forward computations conditional. Rather than processing every token through an identical dense Multi-Layer Perceptron (MLP), the model intelligently routes each token to a limited subset of specialized MLP experts.
<0>
The MoE paradigm has the potential to enhance both processing capacity and efficiency by activating only a few experts per token. This approach can result in superior quality with comparable latency or equivalent quality at reduced latency, particularly in large-scale deployments. Nevertheless, MoE frequently introduces supplementary engineering complexities and hurdles. If all tokens are directed to a single expert, that expert transforms into a bottleneck, while others remain inactive, leading to elevated tail latency.
Development teams commonly address these challenges through a combination of strategies. During the training phase, load-balancing losses are incorporated to incentivize the router to distribute traffic evenly among experts. In the serving phase, capacity limits are enforced, and overflow is rerouted. At the infrastructure tier, cross-GPU communication overhead is minimized via batching and intelligent work routing, ensuring predictable data movement.
Speculative Decoding: Text generation inherently proceeds sequentially. Agents allocate significant time to formulating plans, tool arguments, diffs, and explanations, and generating these elements token by token is a time-consuming process. Speculative decoding mitigates latency by employing a smaller “draft” model to suggest tokens, which a larger model can then rapidly validate. When the proposed draft is accurate, the system accepts multiple tokens concurrently, thereby diminishing the count of computationally intensive decoding steps.
<1>
Given the highly predictable structure of code, encompassing elements like imports, brackets, and standard syntax, awaiting a large model such as Composer to generate each individual character proves inefficient. Cursor verifies its utilization of speculative decoding, having trained specialized “draft” models capable of swiftly predicting subsequent tokens. This methodology enables Composer to generate code considerably faster than the conventional token-by-token generation speed.
Context Compaction: Agents invariably generate a substantial volume of text that serves a singular purpose but incurs a high cost for retention, including tool outputs, logs, stack traces, interim diffs, and redundant code snippets. Should the system continuously append all generated content, prompts become excessively large, and latency consequently escalates.
<2>
Context compaction resolves this by summarizing the current working state and preserving only the information pertinent to the subsequent operational step. Rather than propagating complete logs, the system maintains stable indicators such as names of failing tests, error classifications, and critical stack frames. It compresses or discards outdated context, eliminates redundant snippets, and stores raw artifacts externally to the prompt unless their re-access becomes necessary. Numerous sophisticated coding agents, including OpenAI’s Codex and Cursor, depend on context compaction to uphold speed and reliability when approaching the context window threshold.
The implementation of context compaction enhances both system latency and output quality. A reduced token count diminishes the computational load per call, and decreased informational noise lowers the probability of the model deviating or fixating on obsolete data.
Collectively, these three techniques address distinct origins of cumulative latency. MoE effectively lowers the serving cost per invocation, speculative decoding abbreviates generation time, and context compaction minimizes repetitive prompt processing.
Coding agents extend beyond mere text generation; they actively execute code. These agents perform builds, tests, linters, formatters, and scripts as integral components of their primary operational loop. This functionality necessitates an execution environment characterized by isolation, resource limitations, and inherent safety.
<3>
Within Cursor’s operational workflow, the agent initiates a sandboxed workspace from a designated repository snapshot, executes tool calls within that isolated environment, and subsequently returns the results to the model. While at a modest scale, sandboxing primarily serves as a security feature, its application at a large scale introduces significant performance and infrastructure limitations.
Two principal issues emerge as dominant concerns during model training:
Provisioning time frequently becomes the critical bottleneck. Although the model might generate a solution within milliseconds, establishing a secure, isolated environment can consume substantially more time. If sandbox startup unduly prolongs the process, the system is unable to iterate with sufficient rapidity to provide a satisfactory user experience.
Concurrency transforms startup overhead into a bottleneck at scale. Rapidly deploying thousands of sandboxes simultaneously presents a considerable challenge. This complexity intensifies during the training phase, where instructing the model to invoke tools at scale necessitates the operation of hundreds of thousands of concurrent sandboxed coding environments within a cloud infrastructure.
These inherent challenges compelled the Cursor team to develop custom sandboxing infrastructure. They re-engineered their Virtual Machine (VM) scheduler to manage highly fluctuating demand, such as scenarios where an agent must rapidly provision thousands of sandboxes. Cursor regards sandboxes as a fundamental component of its core serving infrastructure, prioritizing swift provisioning and assertive recycling to ensure prompt initiation of tool executions and prevent sandbox startup time from dominating the overall duration to achieve a verified fix.
For enhanced security, Cursor defaults to a restricted Sandbox Mode for agent terminal commands. Commands are executed within an isolated environment where network access is blocked by default, and filesystem access is confined to the workspace and the /tmp/ directory. Should a command fail due to requiring broader access, the user interface provides options to either bypass the command or deliberately re-execute it outside the sandbox.
The crucial insight is to perceive sandboxes not merely as containers, but as a sophisticated system demanding its own dedicated scheduler, robust capacity planning, and meticulous performance tuning.
Cursor’s implementation demonstrates that contemporary coding agents transcend the capabilities of mere text generators. They represent comprehensive systems engineered to modify actual repositories, execute tools, and validate outcomes. Cursor integrated a specialized MoE model with a robust tool harness, latency-optimized serving, and sandboxed execution, enabling the agent to adhere to a pragmatic iterative loop: code inspection, modification, verification checks, and subsequent iteration until a confirmed fix is achieved.
Cursor’s practical experience in deploying Composer to production highlights three universally applicable lessons pertinent to the majority of coding agents:
Effective tool utilization must be intrinsically integrated into the model’s core design. Relying solely on prompting proves insufficient for dependable tool invocation within extended operational loops. The model is required to assimilate tool usage as a fundamental behavior, particularly for editing functions such as search and replace, where minor inaccuracies can compromise the integrity of the edit.
User adoption stands as the paramount metric. While offline benchmarks offer valuable insights, the ultimate success of a coding agent hinges on user trust. A solitary precarious edit or a failed build can deter users from depending on the tool; therefore, evaluation must accurately reflect actual usage scenarios and user acceptance.
Operational speed is an inherent characteristic of the product. Latency directly influences daily usage patterns. It is not necessary to employ a frontier model for every single step. Directing less complex steps to faster models, while reserving more capable models for intricate planning stages, transforms responsiveness into a fundamental product feature rather than solely an infrastructure metric.
Coding agents continue to evolve, with discernible promising trends. Propelled by swift advancements in model training and robust system engineering, the industry is progressing towards a future where these agents achieve significantly greater speed and efficacy.