
Digital services necessitate the precise extraction of data from user-provided documents, including identification cards, driver’s licenses, and vehicle registration certificates. This capability proves crucial for electronic know-your-customer (eKYC) verification. Nevertheless, the vast diversity of languages and document formats across the region presents a substantial challenge for such tasks. The Grab Engineering Team encountered considerable hurdles with conventional Optical Character Recognition (OCR) systems, which struggled to process the wide array of document templates. Although robust proprietary Large Language Models (LLMs) were accessible, these frequently demonstrated insufficient comprehension of Southeast Asian languages, generated inaccuracies and hallucinations, and exhibited high latency. While open-source Vision LLMs offered enhanced efficiency, they often lacked the necessary accuracy for deployment in a production environment. This scenario compelled Grab to fine-tune existing models and, subsequently, develop a lightweight, specialized Vision LLM from inception. This article details the comprehensive architecture, the technical decisions undertaken, and the outcomes realized during this development.
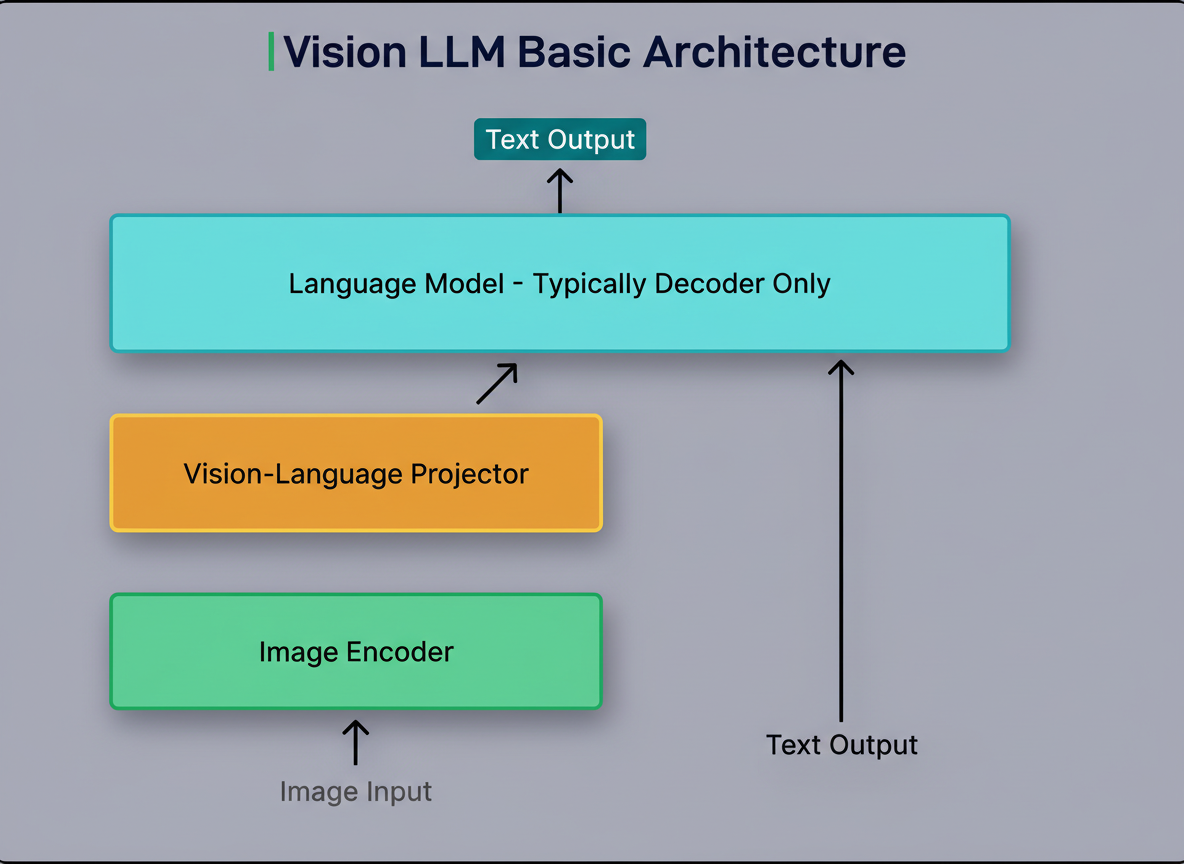
Prior to exploring the solution, a foundational understanding of Vision LLMs and their distinction from conventional text-based language models is beneficial. A standard LLM processes textual inputs and produces textual outputs. A Vision LLM expands upon this functionality by empowering the model to comprehend and process images. Its architecture comprises three vital components that operate in conjunction: The initial component is the image encoder. This module processes an image, converting it into a numerical format suitable for computational processing. This can be conceptualized as translating visual data into a structured representation of numbers and vectors. The second component is the vision-language projector. This element serves as an intermediary between the image encoder and the language model, converting the numerical image representation into a format that the language model can interpret and utilize alongside text inputs. The third component is the language model itself. This familiar text-processing model incorporates both the transformed image information and any textual directives to generate a conclusive text output. For document processing applications, this output would constitute the extracted text and structured data from the document. The accompanying diagram illustrates this architecture:
Grab conducted an evaluation of several open-source models capable of performing Optical Character Recognition (OCR) and Key Information Extraction (KIE). The models considered included Qwen2VL, miniCPM, Llama3.2 Vision, Pixtral 12B, GOT-OCR2.0, and NVLM 1.0. Following a comprehensive assessment, Qwen2-VL 2B was chosen as the foundational multimodal LLM. This choice was predicated on several crucial considerations: Firstly, the model’s size was deemed suitable. Possessing 2 billion parameters, it was sufficiently compact to facilitate full fine-tuning on GPUs with constrained VRAM. Larger models would have necessitated more costly infrastructure and extended training durations, impacting capacity planning. Secondly, the model demonstrated robust support for Southeast Asian languages. Its tokenizer exhibited efficiency for languages such as Thai and Vietnamese, indicating commendable native vocabulary coverage. A tokenizer functions by segmenting text into smaller units, known as tokens, which the model subsequently processes. Effective tokenization allows the model to represent these languages without inefficient resource utilization. Thirdly, and of paramount importance, Qwen2-VL supports dynamic resolution. In contrast to models demanding fixed-size image inputs, this model is capable of processing images at their original resolution. This feature is indispensable for OCR tasks, as resizing or cropping images can introduce distortions to text characters, leading to recognition inaccuracies. Maintaining the original resolution safeguards text integrity and enhances precision. Preliminary benchmarking of Qwen2VL and miniCPM against Grab’s dataset revealed suboptimal accuracy, primarily attributable to the restricted coverage of Southeast Asian languages. This outcome spurred the team to undertake fine-tuning initiatives aimed at elevating OCR and KIE accuracy. However, LLM training demands both extensive data and significant GPU resources, prompting two key inquiries: how to effectively leverage open-source and proprietary internal data, and how to tailor the model to minimize latency while preserving high accuracy, crucial for scenarios such as Shopify BFCM readiness.
Two distinct methodologies were developed by Grab for generating the model’s training data:
The initial methodology centered on the creation of synthetic training data. Southeast Asian language text content was extracted from Common Crawl, an extensive online text corpus encompassing data from across the internet. Leveraging an in-house synthetic data pipeline, text images were generated by rendering this content with diverse fonts, backgrounds, and augmentations. The resultant dataset incorporated text in Bahasa Indonesia, Thai, Vietnamese, and English. Each image comprised a paragraph of randomly selected sentences from the corpus. This synthetic strategy presented multiple benefits, including the controlled generation of training examples, the capacity for producing boundless variations, and guaranteed coverage of various visual styles and document states.
The second strategy harnessed authentic documents gathered by Grab. Empirical findings indicated that the application of document detection and orientation correction substantially enhanced OCR and information extraction capabilities. For the purpose of generating a preprocessing dataset, Grab developed Documint, an internal platform that establishes an auto-labelling and preprocessing framework for document comprehension. Documint facilitates the preparation of high-quality, labeled datasets via various submodules that perform the complete OCR and KIE tasks. This pipeline was utilized with a considerable volume of Grab-collected cards and documents to derive training labels. Subsequent refinement by human reviewers ensured a high degree of label accuracy. Documint is composed of four principal modules: The detection module identifies the pertinent document region within a complete image. The orientation module ascertains the requisite correction angle, for instance, 180 degrees if a document is inverted. The OCR module extracts text values in an unstructured format. Ultimately, the KIE module transforms the unstructured text into structured JSON values. 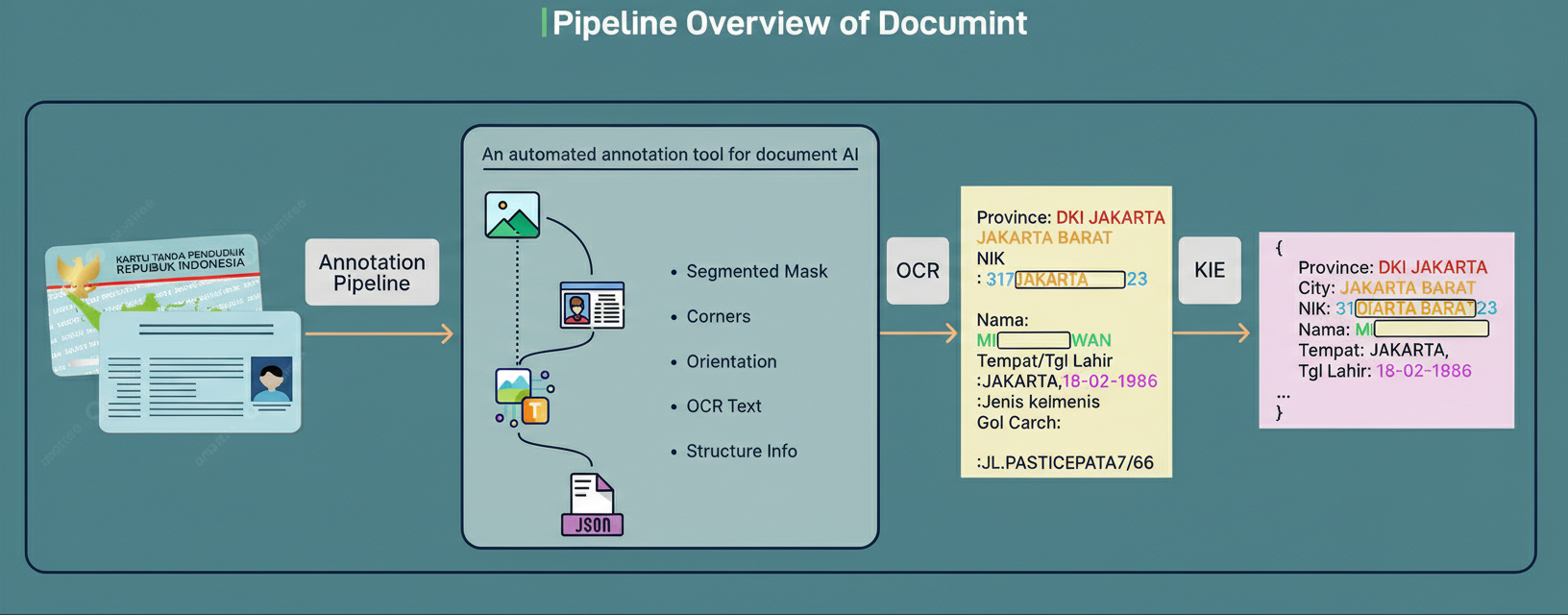 Source: Grab Engineering Blog
Source: Grab Engineering Blog
The model’s development at Grab unfolded across three discrete phases, with each phase building upon the insights gleaned from its predecessor:
The initial fine-tuning endeavor utilized Low-Rank Adaptation, or LoRA. This technique proves efficient by updating only a limited subset of the model’s parameters, as opposed to retraining the entirety of the model. Specifically, LoRA integrates minor trainable matrices into the model while retaining the majority of the original weights in a frozen state. This methodology curtails computational resource demands and shortens training durations. Grab trained the model using curated document data encompassing diverse document templates in multiple languages. Its performance demonstrated potential for documents employing Latin scripts, with the LoRA fine-tuned Qwen2VL-2B achieving high field-level accuracy for Indonesian documents. Nevertheless, the fine-tuned model encountered difficulties with two classifications of documents: Firstly, it struggled with documents featuring non-Latin scripts, such as Thai and Vietnamese. Secondly, its performance was suboptimal on unstructured layouts characterized by small, dense text. The experiments unveiled a critical constraint. Although open-source Vision LLMs frequently possess extensive multilingual text corpus coverage for the language model decoder’s pre-training, they often lack visual examples of Southeast Asian language text during vision encoder training. The language model might comprehend Thai text, but the vision encoder had not been trained to discern the visual characteristics of Thai characters within images. This realization underscored the necessity of pursuing full parameter fine-tuning.
Adopting principles from the Large Language and Vision Assistant (LLAVA) methodology, Grab implemented a two-stage training strategy: During Stage 1, referred to as continual pre-training, only the model’s vision components were trained, utilizing synthetic OCR datasets developed for Bahasa Indonesia, Thai, Vietnamese, and English. This phase facilitated the model’s acquisition of the distinctive visual patterns characteristic of Southeast Asian scripts. Throughout this stage, the language model remained frozen, ensuring its weights were not altered. In Stage 2, designated full-parameter fine-tuning, Grab undertook the fine-tuning of the entire model, encompassing the vision encoder, the projector, and the language model. Task-specific document data was employed for this training, allowing all model components to be optimized collectively for the document extraction objective. 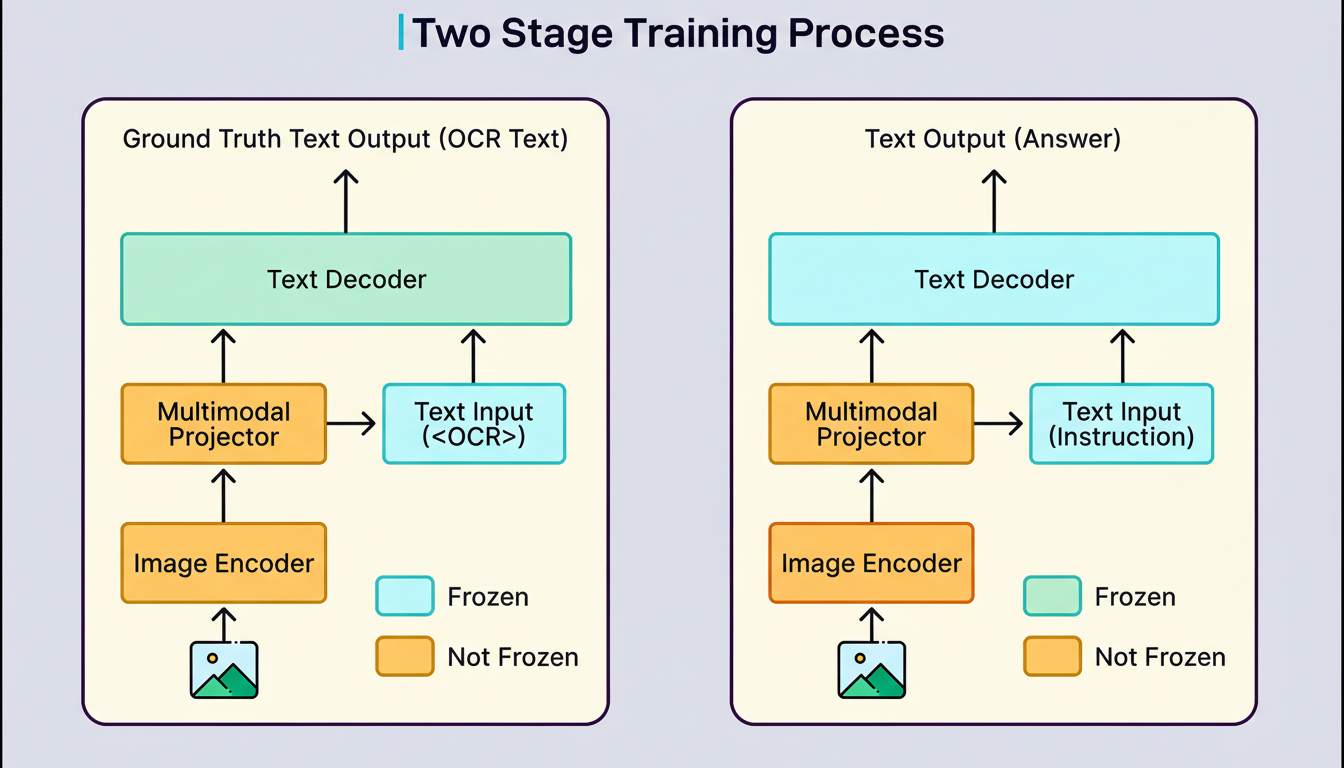 The outcomes proved substantial. For instance, Thai document accuracy witnessed a 70 percentage point increase from the baseline. Vietnamese document accuracy elevated by 40 percentage points from its baseline. Indonesian documents experienced a 15 percentage point enhancement, and Philippine documents demonstrated a 6 percentage point improvement. The fully fine-tuned Qwen2-VL 2B model delivered considerable advancements, particularly concerning documents that had presented challenges for the LoRA model.
The outcomes proved substantial. For instance, Thai document accuracy witnessed a 70 percentage point increase from the baseline. Vietnamese document accuracy elevated by 40 percentage points from its baseline. Indonesian documents experienced a 15 percentage point enhancement, and Philippine documents demonstrated a 6 percentage point improvement. The fully fine-tuned Qwen2-VL 2B model delivered considerable advancements, particularly concerning documents that had presented challenges for the LoRA model.
Although the 2B model achieved success, full fine-tuning strained the capabilities of available GPUs. To maximize resource utilization and develop a model precisely aligned with their requirements, Grab opted to construct a lightweight Vision LLM, comprising approximately 1 billion parameters, entirely from the ground up. This strategic approach involved integrating optimal components from various models. The robust vision encoder from the larger Qwen2-VL 2B model, which had demonstrated efficacy in comprehending document images, was adopted. This was then coupled with the compact and efficient language decoder derived from the Qwen2.5 0.5B model. These components were interconnected via an adjusted projector layer, ensuring unimpeded communication between the vision encoder and language decoder. This synergistic combination resulted in a custom Vision LLM of roughly 1 billion parameters, optimized for both training and operational deployment.
This novel model was subjected to a comprehensive four-stage training process by Grab:
Stage 1 centered on projector alignment. The initial phase involved training the newly introduced projector layer to guarantee effective communication between the vision encoder and language decoder. In the absence of appropriate alignment, the language model would be unable to accurately interpret the vision encoder’s outputs.
Stage 2 encompassed vision tower enhancement. The vision encoder underwent training on an extensive and varied collection of public multimodal datasets. These datasets addressed tasks such as visual question answering, general OCR, and image captioning. This phase augmented the model’s fundamental visual comprehension across a multitude of scenarios.
Stage 3 concentrated on language-specific visual training. The model was trained by Grab using two categories of synthetic OCR data tailored for Southeast Asian languages. This stage demonstrated crucial importance, as its omission would have resulted in a performance decrement of up to 10 percentage points on non-Latin documents. This phase guaranteed the vision encoder’s capacity to identify the distinct visual characteristics of Thai, Vietnamese, and other regional scripts.
Stage 4 concluded the process with task-centric fine-tuning. Full-parameter fine-tuning was executed on the custom 1B model, employing the meticulously curated document dataset. This culminating stage optimized the entire system for the specialized production application of document information extraction. 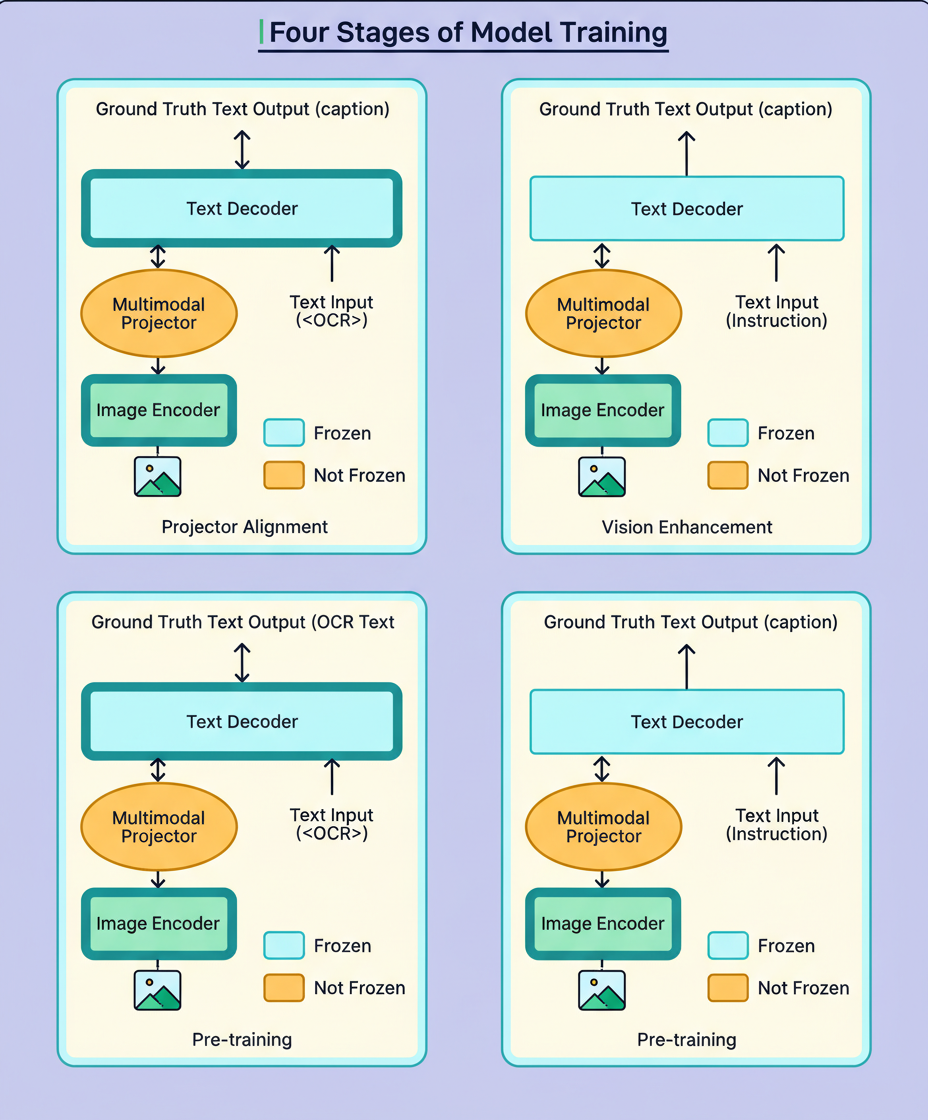
The ultimate 1B model demonstrated notable achievements across two pivotal metrics: accuracy and latency. Regarding accuracy, the model exhibited performance comparable to the larger 2B model, maintaining an accuracy differential within 3 percentage points across the majority of document types. Furthermore, the model preserved robust generalization when trained on quality-augmented datasets, signifying its ability to manage variations not encountered during training. The latency results proved even more compelling. The 1B model attained 48 percent faster processing at the P50 latency (median response time), 56 percent faster at P90 latency (90th percentile), and 56 percent faster at P99 latency (99th percentile, indicative of worst-case scenarios). These enhancements in latency hold particular significance. Grab determined that a primary shortcoming of external APIs, such as ChatGPT or Gemini, was their P99 latency, which can readily be 3 to 4 times greater than the P50 latency. Such variability would be deemed unacceptable for extensive production deployments requiring unwavering performance, particularly during critical periods like Black Friday Cyber Monday scale testing, where every edge network requests per minute counts.
This initiative produced several crucial insights that can inform analogous undertakings. Full parameter fine-tuning demonstrated superiority over LoRA for specialized, non-Latin script domains. While LoRA offers efficiency, it cannot rival the performance enhancements realized by updating all model parameters when confronting notably disparate data distributions. Lightweight models exhibit substantial effectiveness. A more compact model, approximating 1 billion parameters, developed independently and trained thoroughly, is capable of achieving near state-of-the-art outcomes. This substantiates the efficacy of custom architecture in preference to merely employing the largest available model. The selection of the base model holds considerable importance. Commencing with a model possessing native support for target languages is paramount for successful implementation. Endeavoring to compel a model to learn languages for which it was not designed typically yields suboptimal results. Data quality plays a decisive role. Meticulous dataset preprocessing and augmentation are as significant as the model architecture in attaining consistent and precise results. The investment in constructing Documint and generating synthetic datasets directly contributed to the ultimate model’s success. Lastly, native resolution support is revolutionary for OCR tasks. A model capable of managing dynamic image resolutions preserves text integrity and dramatically elevates OCR capabilities, effectively mitigating the distortion that arises when images are resized to accommodate fixed input dimensions.
Grab’s trajectory in constructing a Vision LLM illustrates that specialized Vision LLMs possess the capability to effectively supersede conventional OCR pipelines with a singular, integrated, and highly accurate model. This innovation unlocks new opportunities for document processing at scale. The project demonstrates that through strategic training methodologies, rigorous data preparation, and judicious model architecture choices, more compact, specialized models can surpass larger, general-purpose counterparts. The resultant system processes documents with greater speed and precision than preceding solutions, concurrently consuming fewer computational resources. Grab persistently advances these functionalities. The team is actively developing Chain of Thought-based OCR and KIE models to bolster generalization and address an even wider array of document scenarios. Concurrently, support is being expanded to all Grab markets, introducing sophisticated document processing to regions including Myanmar, Cambodia, and beyond. References: How we built a custom vision LLM to improve document processing at Grab (URL: https://engineering.grab.com/custom-vision-llm-at-grab) Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution (URL: https://arxiv.org/abs/2409.12191)