
LinkedIn provides rapid user experiences to hundreds of millions of global members, whether they are accessing their feeds or sending messages. This seamless operation relies on the collaborative functioning of thousands of software services. Service Discovery, as an essential infrastructure system, facilitates this intricate coordination.
In contemporary large-scale applications, LinkedIn employs tens of thousands of microservices, each dedicated to specific functions such as authentication, messaging, or content generation, rather than developing a singular monolithic program. These microservices necessitate continuous communication and precise location awareness within the network.
Service discovery addresses this fundamental location challenge. Rather than utilizing hardcoded addresses that are susceptible to changes during server restarts or scaling events, services leverage a centralized directory that tracks the current location of every active service. This directory meticulously maintains IP addresses and port numbers for all active service instances.
At LinkedIn’s immense scale, encompassing tens of thousands of microservices deployed across global data centers and processing billions of daily requests, the efficacy of service discovery becomes exceptionally critical. The system must facilitate real-time updates as servers scale up or down, maintain paramount reliability, and deliver responses within milliseconds. This context highlights the importance of robust capacity planning.
This article examines the development and deployment of LinkedIn’s Next-Gen Service Discovery, a highly scalable control plane designed to support application containers in diverse programming languages.
Disclaimer: This post is derived from publicly shared information by the LinkedIn Engineering Team. Any identified inaccuracies are welcomed for correction.
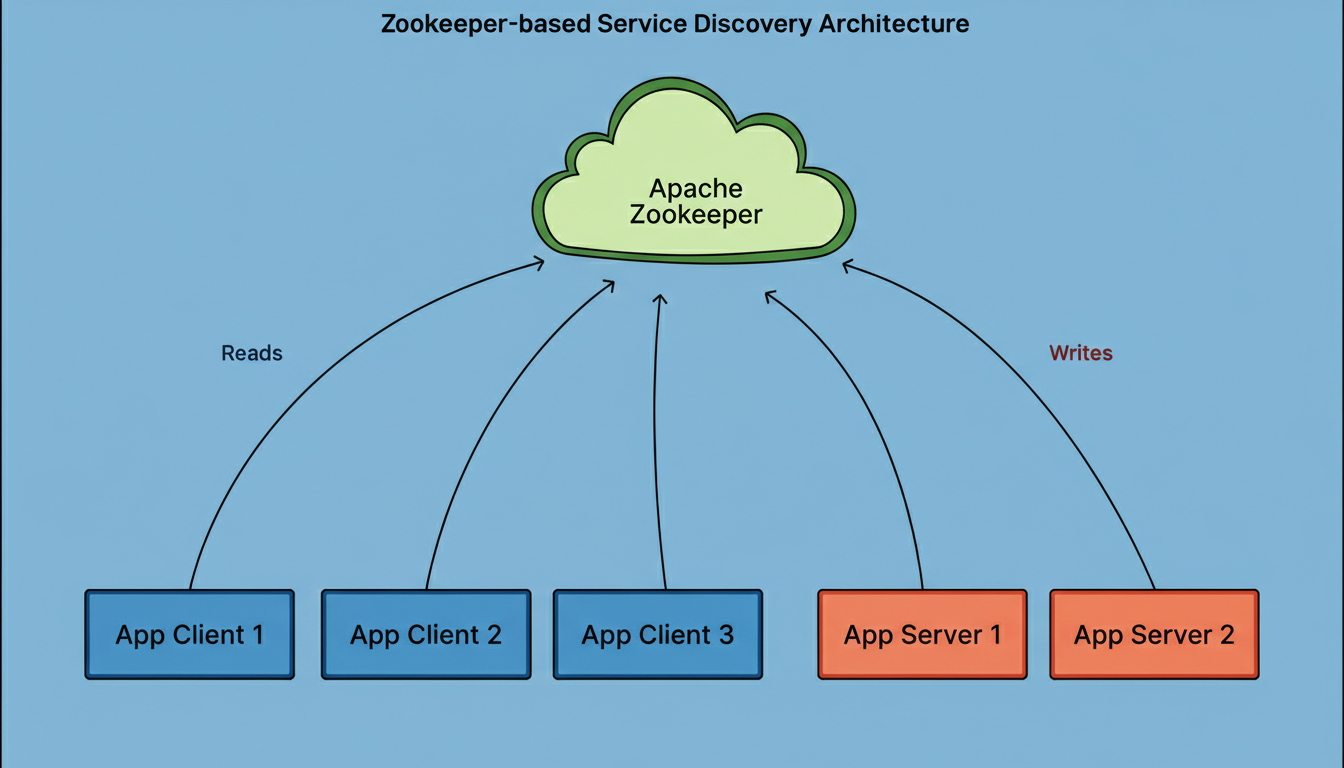
For a decade, LinkedIn utilized Apache Zookeeper as the control plane for its service discovery operations. Zookeeper functions as a coordination service responsible for maintaining a centralized registry of deployed services.
Within this architectural paradigm, Zookeeper enabled server applications to register their endpoint addresses using a proprietary format known as D2, an acronym for Dynamic Discovery. The system then stored and served configurations dictating RPC traffic flow, termed D2 configs, to client applications. The data plane comprised these application servers and clients, managing inbound and outbound RPC traffic via LinkedIn’s custom Rest.li framework, a robust RESTful communication system.
The operational mechanism of this system involved several key steps:
The Zookeeper client library was deployed across all application servers and clients.
The Zookeeper ensemble directly processed write requests from application servers, registering their endpoint addresses as ephemeral nodes, specifically D2 URIs.
Ephemeral nodes represent temporary entries that persist only for the duration of an active connection.
Zookeeper continuously performed health checks on these connections to ensure the vitality of the ephemeral nodes.
Furthermore, Zookeeper directly handled read requests from application clients, allowing them to establish watchers on the server clusters they intended to communicate with. Upon any updates, clients would subsequently retrieve the modified ephemeral nodes.
Despite its perceived straightforwardness, this architecture presented significant challenges across three domains: scalability, compatibility, and extensibility. Historical benchmark evaluations indicated that the system was projected to reach its operational capacity by early 2025.
The primary issues associated with Zookeeper were identified as follows:
The control plane functioned as a flat architectural layer, managing requests for hundreds of thousands of application instances.
During the deployment phases of substantial applications, characterized by numerous calling clients, the D2 URI ephemeral nodes exhibited frequent modifications. This dynamic resulted in “read storms,” where a massive fanout occurred as all clients simultaneously attempted to retrieve updates, consequently inducing elevated latencies for both read and write operations. Such scenarios are common challenges in large-scale distributed systems and highlight the need for careful capacity planning and strategies like chaos engineering to identify weaknesses.
Zookeeper adheres to a strong consistency model, prioritizing strict transactional ordering over availability. All read operations, write requests, and session health checks traverse a singular request queue. A substantial backlog of read requests within this queue could impede the processing of write requests. Furthermore, an overloaded queue led to the premature termination of all sessions due to health check timeouts. This issue caused the removal of ephemeral nodes, culminating in a reduction in application server capacity and potential site unavailability.
The process of conducting session health checks across all registered application servers proved to be an unscalable endeavor as the fleet expanded. By July 2022, LinkedIn faced an estimated 2.5 years of remaining capacity, considering a projected 50 to 100 percent annual growth rate in cluster size and the volume of watchers, even after augmenting the number of Zookeeper hosts to 80.
The reliance on LinkedIn’s proprietary custom schemas for D2 entities rendered them incompatible with contemporary data plane technologies such as gRPC and Envoy.
The read and write logic residing within application containers was predominantly implemented in Java, with an incomplete and antiquated counterpart for Python applications. Consequently, integrating applications developed in other programming languages necessitated a complete rewrite of the underlying logic.
The absence of an intermediary architectural layer between the service registry and individual application instances impeded the evolution of modern, centralized RPC management methodologies, including centralized load balancing.
This limitation also introduced complexities in integrating with alternative service registries designed to supersede Zookeeper, such as Etcd in conjunction with Kubernetes, or any emergent storage systems offering enhanced functionality or performance.
The LinkedIn Engineering Team conceived a new architectural design specifically engineered to overcome the previously identified limitations. In contrast to Zookeeper’s unified handling of read and write requests, Next-Gen Service Discovery employs a bifurcated approach, utilizing Kafka for write operations and the Service Discovery Observer for read operations.
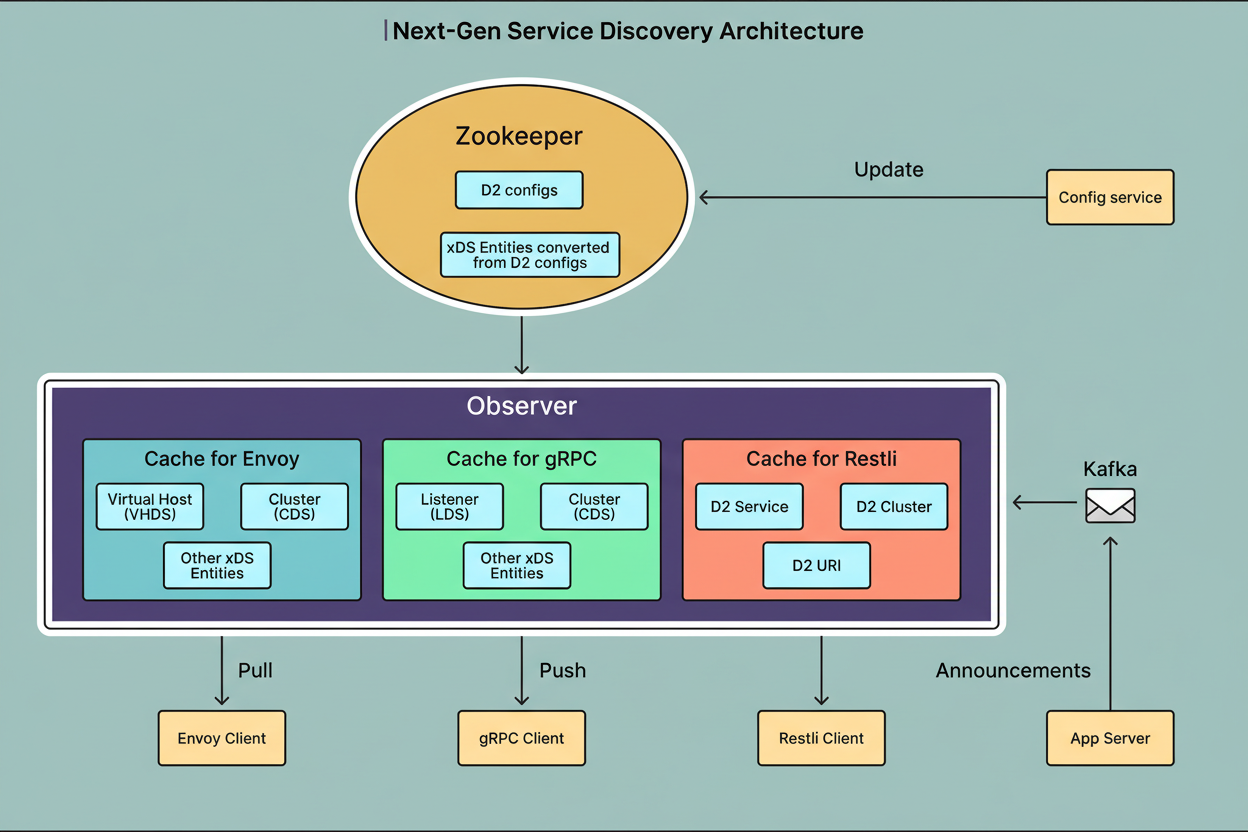
Kafka ingests application server writes and periodic heartbeat signals, which are transmitted via Kafka events referred to as Service Discovery URIs. Kafka operates as a distributed streaming platform, proficient in processing millions of messages per second. Each Service Discovery URI encapsulates vital information pertaining to a service instance, encompassing its service name, IP address, port number, health status, and associated metadata.
The Service Discovery Observer retrieves URIs from Kafka and commits them to its main memory. Application clients establish bidirectional gRPC streams with the Observer, submitting subscription requests through the xDS protocol. The Observer maintains these persistent streams to instantaneously push data and all subsequent updates to connected application clients.
The xDS protocol constitutes an industry standard, originally developed by the Envoy project, specifically for service discovery functionalities. This mechanism eliminates the need for clients to poll for updates, as the Observer actively pushes changes in real-time. Such a streaming paradigm represents a significant efficiency enhancement compared to the traditional polling model.
D2 configurations continue to be maintained within Zookeeper. Application owners execute CLI commands to utilize the Config Service for updating D2 configurations and subsequently transforming them into xDS entities.
The Observer retrieves these configurations from Zookeeper and distributes them to client applications using the identical mechanism employed for URIs.
The Observer is designed for horizontal scalability and is implemented in Go, a language selected for its exceptional concurrency capabilities.
It demonstrates efficient processing of extensive volumes of client requests, proficient dispatch of data updates, and effective consumption of URIs across the entire LinkedIn fleet. Presently, a single Observer instance is capable of sustaining 40,000 client streams while simultaneously transmitting 10,000 updates per second and consuming 11,000 Kafka events per second.
Based on projections indicating a fleet size expansion to 3 million instances in the forthcoming years, LinkedIn anticipates requiring approximately 100 Observer instances.
The implementation of the new architecture yielded several notable improvements when benchmarked against the Zookeeper-based system:
LinkedIn prioritized system availability over strict consistency, acknowledging that service discovery data primarily requires eventual convergence. Transient inconsistencies across servers are deemed acceptable, provided the data maintains high availability for the expansive client fleet. This strategic decision marks a significant departure from Zookeeper’s inherent strong consistency model.
Multiple Observer replicas achieve eventual consistency once a Kafka event has been consumed and processed across all replicas. Even in scenarios where Kafka experiences substantial lag or becomes inoperative, the Observer persistently fulfills client requests utilizing its cached data, thereby effectively mitigating cascading failures. This architecture enhances system resilience, a core tenet often explored through methodologies like chaos engineering.
Further enhancements to scalability can be realized by segmenting dedicated Observer instances. Certain Observers can be designated to focus exclusively on consuming Kafka events as consumers, while others can function as servers, dedicated to serving client requests. The server-oriented Observers would then subscribe to the consumer-oriented Observers for cache update notifications.
Next-Gen Service Discovery offers native support for the gRPC framework, facilitating extensive multi-language compatibility.
Given the control plane’s adoption of the xDS protocol, it seamlessly integrates with open-source gRPC and the Envoy proxy. Applications that do not utilize Envoy can leverage open-source gRPC code to directly subscribe to the Observer. Furthermore, applications integrating the Envoy proxy automatically acquire multi-language support.
The introduction of Next-Gen Service Discovery as a central control plane, positioned between the service registry and clients, empowers LinkedIn to expand into advanced service mesh functionalities. These capabilities encompass centralized load balancing, the implementation of robust security policies, and the dynamic transformation of endpoint addresses between IPv4 and IPv6.
LinkedIn also gains the ability to integrate this system with Kubernetes, thereby capitalizing on application readiness probes. This integration would facilitate the collection of status and metadata from application servers, transitioning servers from an active announcement model to a more reliable and manageable passive reception of status probes.
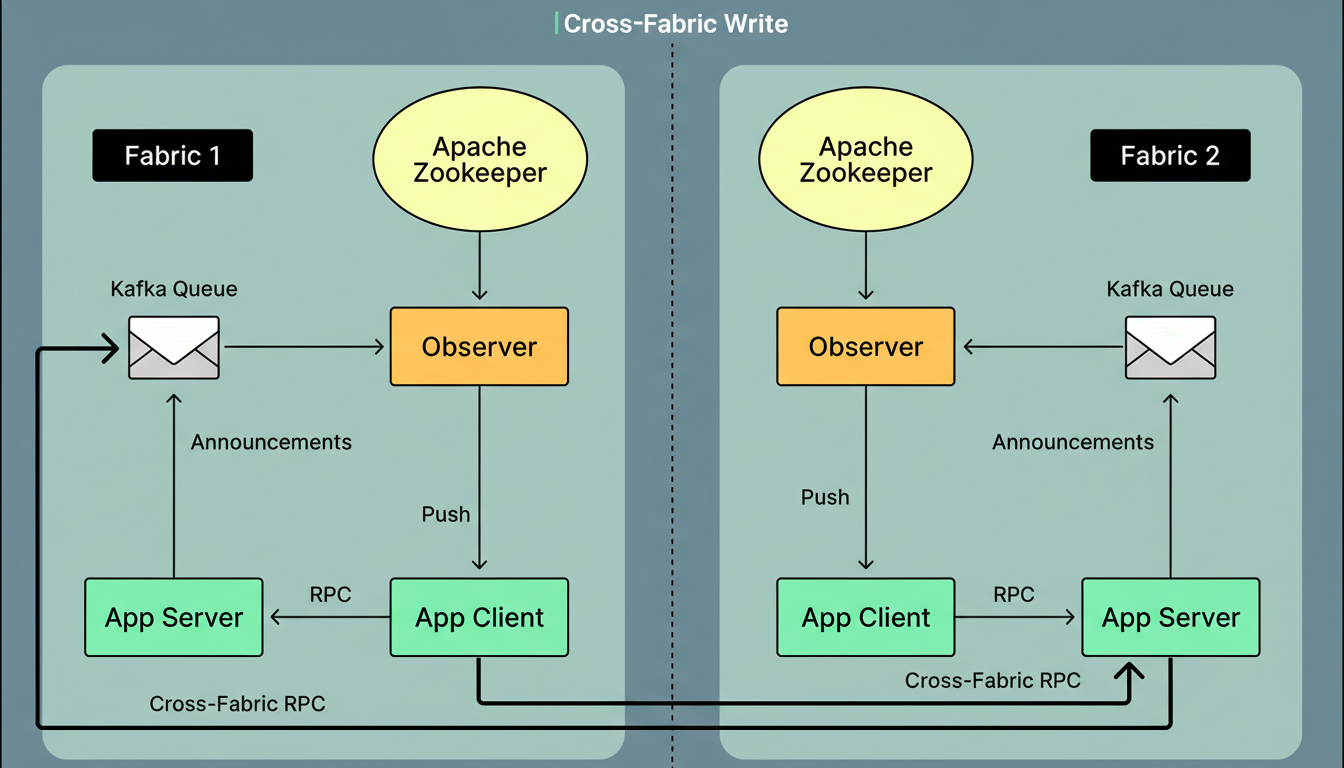
Next-Gen Service Discovery Observers operate autonomously within each fabric, where a fabric denotes either a data center or an isolated cluster. Application clients possess the configurable option to establish connections with an Observer situated in a remote fabric, subsequently being served by the server applications hosted within that particular fabric. This functionality accommodates bespoke application requirements or furnishes failover mechanisms in instances where an Observer in one fabric becomes inoperative, thereby ensuring uninterrupted business traffic. This design supports robust multi-region deployment strategies for global infrastructure.
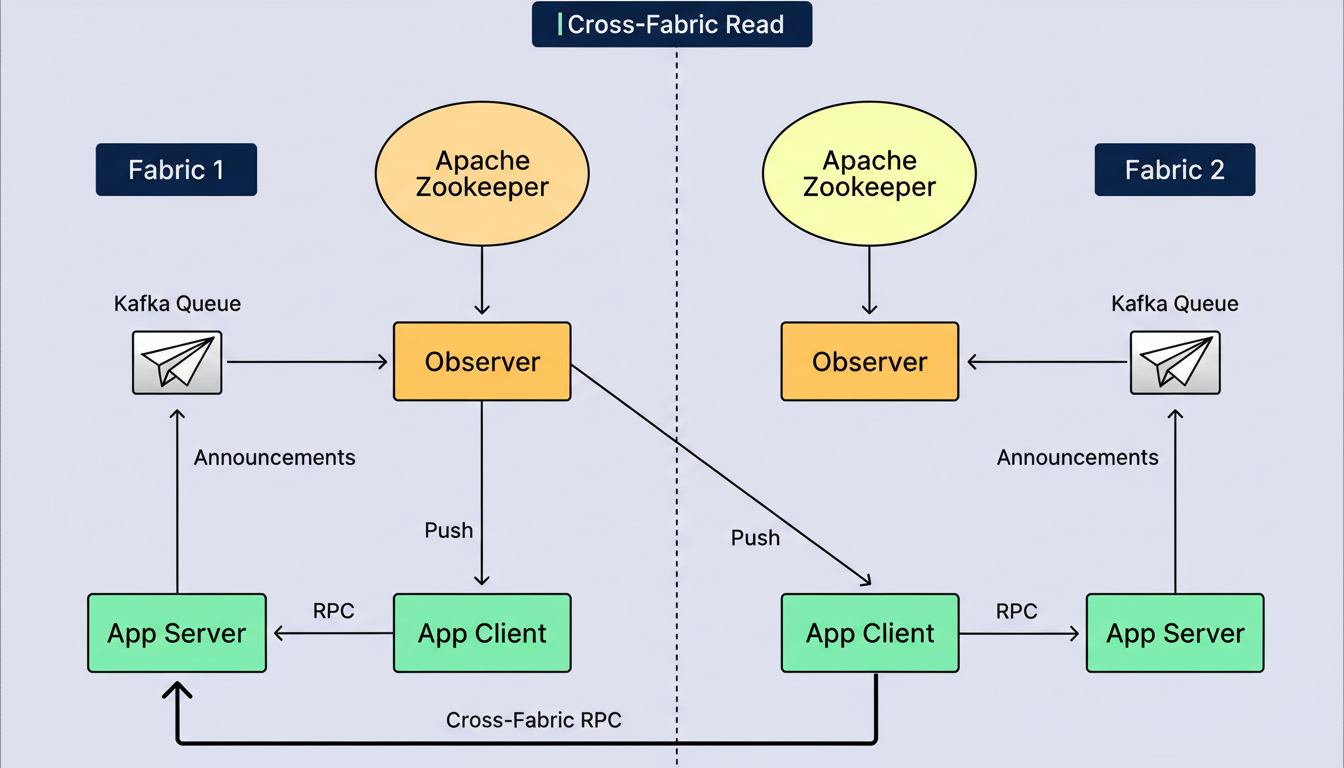
Furthermore, application servers are capable of submitting write operations to the control plane across multiple fabrics. Cross-fabric announcements are distinguished from local announcements by the appending of a fabric name suffix. This capability allows application clients to direct requests to application servers located in both local and remote fabrics, based on predefined preferences.
The deployment of Next-Gen Service Discovery across hundreds of thousands of hosts, without incurring any disruption to ongoing requests, necessitated meticulous planning and execution.
LinkedIn required the service discovery data delivered by the new control plane to precisely mirror the data residing on Zookeeper. This undertaking involved equipping all company-wide application servers and clients with the requisite mechanisms through a simple infrastructure library version increment. Centralized control on the infrastructure side was also essential to enable or disable Next-Gen Service Discovery read and write functionalities on an application-by-application basis. Lastly, robust central observability across thousands of applications spanning all fabrics was paramount for assessing migration readiness, verifying outcomes, and facilitating troubleshooting efforts.
The migration encountered three principal challenges:
Firstly, given the mission-critical nature of service discovery, any operational error carried the potential for severe site-wide incidents. With Zookeeper nearing its capacity limitations, an urgent imperative existed for LinkedIn to expedite the migration of as many applications as possible away from the legacy Zookeeper system.
Secondly, the states of existing applications were inherently complex and unpredictable. Next-Gen Service Discovery Read functionality mandated client applications to establish gRPC streams. However, Rest.li applications, which had been operational within the company for over a decade, exhibited highly disparate states concerning dependencies, gRPC SSL configurations, and network access. The compatibility of numerous applications with the new control plane remained uncertain until the read functionality was actually enabled.
Thirdly, the read and write migration processes were intrinsically coupled. A failure to migrate write operations meant no data could be accessed via Next-Gen Service Discovery. Conversely, if read operations remained unmigrated, data continued to be retrieved from Zookeeper, thereby impeding write migration. Due to the susceptibility of read path connectivity to application-specific states, the read migration phase had to commence first. Even after client applications had transitioned for reads, LinkedIn needed a mechanism to ascertain which server applications were prepared for Next-Gen Service Discovery Write and to prevent clients from reverting to Zookeeper-based read operations.
LinkedIn adopted a dual mode migration strategy, wherein applications concurrently operated both the legacy and the new systems, enabling background verification of the emergent data flow.
To effectively decouple the read and write migration processes, the new control plane was configured to serve a consolidated dataset comprising Kafka and Zookeeper URIs. Kafka functioned as the primary data source, with Zookeeper serving as a contingency backup. In scenarios where no Kafka data was available, the control plane provided Zookeeper data, replicating the information clients would directly retrieve from Zookeeper. This approach facilitated the independent initiation of the read migration phase.
In the Dual Read mode, an application client simultaneously retrieves data from both Next-Gen Service Discovery and Zookeeper, with Zookeeper retaining its role as the authoritative source for serving live traffic. An independent background thread within the client attempted to resolve traffic as if it were being served by Next-Gen Service Discovery data, subsequently reporting any encountered errors.
LinkedIn established a comprehensive suite of metrics to validate connectivity, assess performance, and confirm data correctness across both the client and Observer components. On the client side, connectivity and latency metrics monitored connection status and data latencies, measuring the duration from subscription request submission to data reception. Dual Read metrics facilitated a comparison between data received from Zookeeper and Next-Gen Service Discovery to pinpoint any discrepancies. Service Discovery request resolution metrics displayed the status of requests, mirroring Zookeeper-based metrics but incorporating a Next-Gen Service Discovery prefix to identify whether requests were resolved using the new system’s data and to detect potential issues like missing critical information.
On the Observer side, connection and stream metrics provided insights into client connection types, counts, and overall capacity. These metrics were instrumental in identifying problems such as imbalanced connections and unexpected connection losses during restart. Request processing latency metrics quantified the time elapsed from the Observer’s reception of a request to the queuing of the requested data for transmission. The actual duration of data transmission over the network was deliberately excluded, as problematic client hosts could experience delays in data reception, thereby skewing the metric. Supplementary metrics continuously tracked Observer resource utilization, encompassing CPU usage, memory consumption, and network bandwidth.
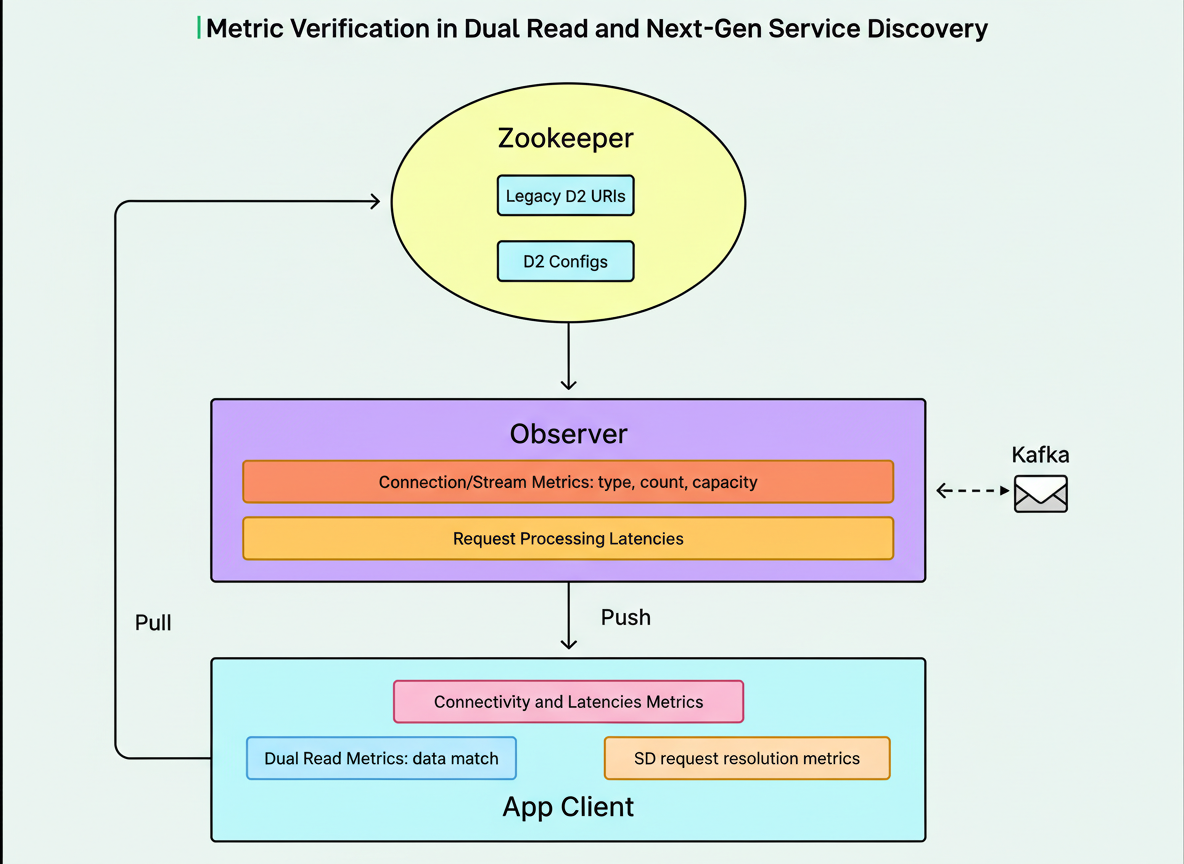
Leveraging this extensive array of metrics and alerts, LinkedIn proactively identified and rectified numerous issues—including connectivity problems, reconnection storms, flawed subscription handling logic, and data inconsistencies—before applications actively consumed Next-Gen Service Discovery data. This proactive approach averted numerous company-wide incidents. Following the successful completion of all verification stages, applications were progressively transitioned to perform Next-Gen Service Discovery read-only operations.
Under the Dual Write mode, application servers concurrently reported their status to both Zookeeper and Next-Gen Service Discovery.
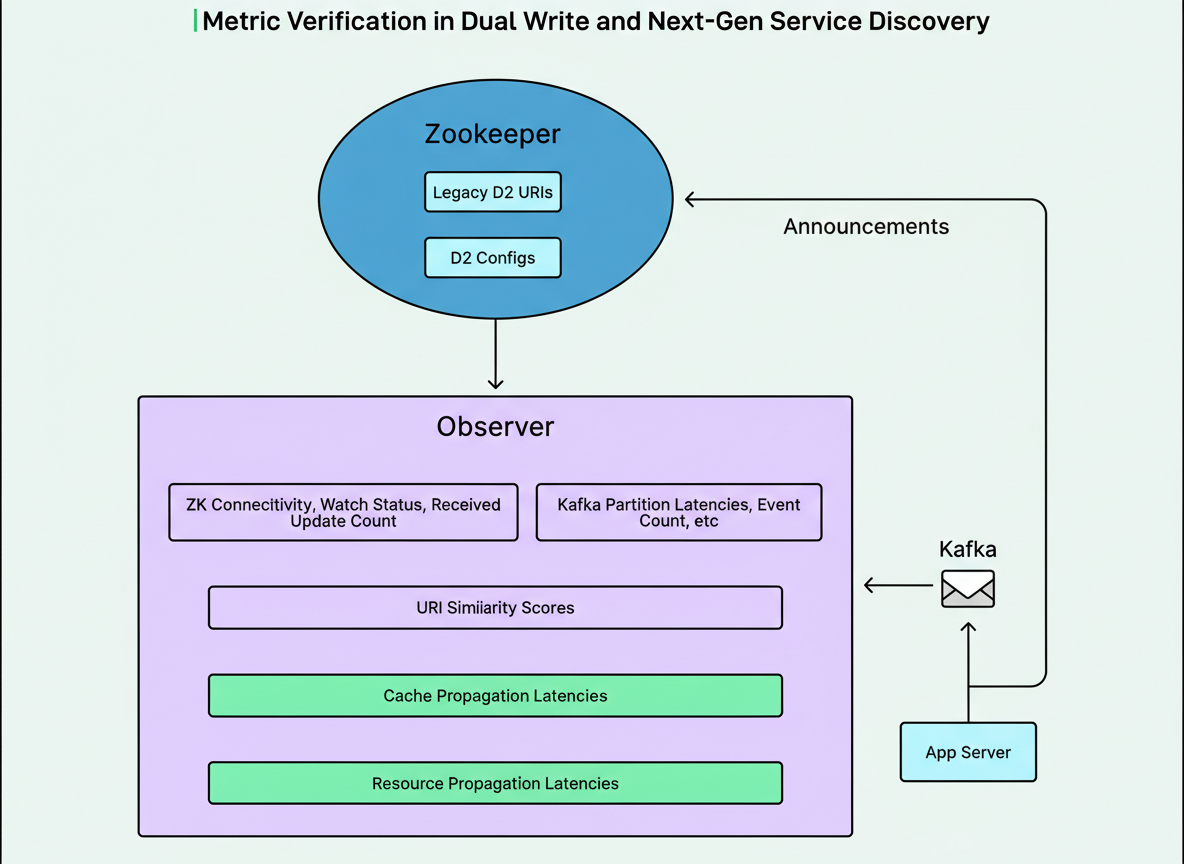
From the Observer’s perspective, Zookeeper-related metrics continuously monitored for potential outages, connection losses, or elevated latencies by tracking connection status, watch status, received data counts, and associated lags. Concurrently, Kafka metrics provided oversight for potential outages and high latencies through observation of partition lags and event counts.
LinkedIn devised a URI Similarity Score for each application cluster, derived from comparing data received from Kafka and Zookeeper. A perfect 100 percent match indicated that all URIs within a given application cluster were identical, thereby guaranteeing that Kafka announcements precisely corresponded with existing Zookeeper announcements.
Cache propagation latency was quantified as the temporal interval from the moment data was received by the Observer to the subsequent update of the Observer’s cache.
Resource propagation latency represented the comprehensive end-to-end write latency, calculated as the duration from an application server’s announcement to the final update of the Observer’s cache.
On the application server side, a dedicated metric tracked the server announcement mode, enabling precise determination of whether a server was announcing solely to Zookeeper, engaging in dual write, or exclusively utilizing Next-Gen Service Discovery. This provided LinkedIn with clarity regarding the full adoption of each new stage by all instances of a server application.
LinkedIn additionally monitored end-to-end propagation latency, measuring the time from an application server’s initial announcement to a client host’s reception of the update. A specialized dashboard was developed to facilitate daily measurement across all client-server pairings, with continuous monitoring for a P50 latency of less than 1 second and a P99 latency of less than 5 seconds. The P50 metric signifies that 50 percent of clients received the propagated data within the specified timeframe, while P99 indicates that 99 percent received it within that same duration.
The most conservative approach for write migration would have entailed deferring the cessation of Zookeeper announcements until all client applications had transitioned to Next-Gen Service Discovery Read and all Zookeeper-reading code had been purged. Nevertheless, confronting constrained Zookeeper capacity and the critical need to avert outages, LinkedIn was compelled to initiate write migration concurrently with client application migration.
LinkedIn engineered cron jobs to systematically analyze Zookeeper watchers configured on the Zookeeper data for each application, subsequently enumerating the corresponding reader applications. A watcher constitutes a mechanism through which clients register their interest in data modifications; upon data alteration, Zookeeper issues notifications to all registered watchers. These automated tasks generated snapshots of watcher status at brief intervals, thereby capturing even ephemeral readers such as offline jobs. The compiled snapshots were then aggregated into daily and weekly reports.
These reports served to identify applications that had recorded no active readers on Zookeeper within the preceding two-week period, a criterion established by LinkedIn to signify an application’s readiness to commence Next-Gen Service Discovery Write operations. The reports also highlighted “top blockers,” denoting reader applications that impeded the migration of the greatest number of server hosts, and “top applications being blocked,” pinpointing the largest applications unable to migrate and specifying their obstructing readers.
This critical intelligence empowered LinkedIn to strategically prioritize efforts on the most significant impediments to Next-Gen Service Discovery Read migration. Furthermore, the automated process was capable of detecting any new client that began reading server applications already migrated to Next-Gen Service Discovery Write and sending alerts, allowing prompt coordination with the respective reader application owner for either migration or troubleshooting.
The Next-Gen Service Discovery system has delivered substantial enhancements compared to the legacy Zookeeper-based architecture.
Presently, the system efficiently manages the company-wide fleet of hundreds of thousands of application instances within a single data center, exhibiting data propagation latencies of P50 less than 1 second and P99 less than 5 seconds. In stark contrast, the preceding Zookeeper-based architecture frequently encountered incidents of elevated latency and unavailability, with data propagation latencies typically registering P50 less than 10 seconds and P99 less than 30 seconds.
This notable achievement represents a tenfold improvement in median latency and a sixfold improvement in 99th percentile latency. The new system not only fortifies platform reliability at an immense scale but also paves the way for future innovations in areas such as centralized load balancing, seamless service mesh integration, and robust cross-fabric resiliency.
Next-Gen Service Discovery signifies a fundamental transformation within LinkedIn’s infrastructure, redefining the mechanisms by which applications discover and interact across global data centers. Through the replacement of a decade-old Zookeeper-based system with an architecture powered by Kafka and xDS, LinkedIn has successfully attained near real-time data propagation, comprehensive multi-language compatibility, and genuine horizontal scalability.
References: