
2026 has started with notable advances. In January alone, Moonshot AI revealed Kimi K2.5, a trillion-parameter multimodal agent model released as open source. Alibaba introduced Qwen3-Coder-Next, a high-efficiency coding model tailored for agentic coding workflows. Additionally, OpenAI launched a macOS application for its Codex coding assistant. These developments reflect trends evolving over several months.
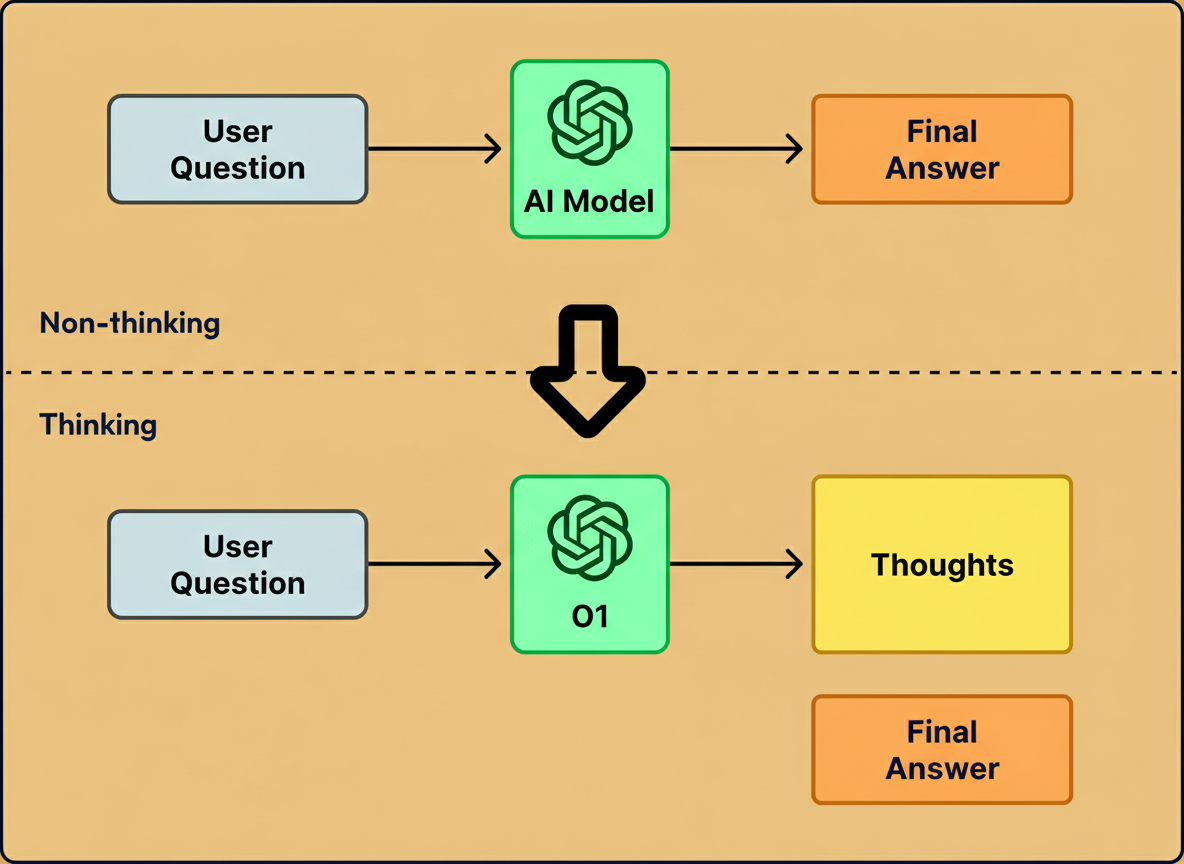
Initial language models, such as GPT-4, generated responses token-by-token immediately after receiving input. This approach proved effective for straightforward questions but often faltered on complex problems involving advanced mathematics or multi-step reasoning.
Subsequent models like OpenAI’s o1 improved performance by incorporating a “thinking” phase prior to outputting answers. Instead of directly producing a final response, these models generate intermediate reasoning steps before concluding. Although this process demands additional computation, it enables solving more sophisticated logic and planning tasks.
By early 2026, a majority of prominent AI laboratories had either released reasoning models or integrated reasoning capabilities into their core products.
A pivotal technique enabling scalable model training is Reinforcement Learning with Verifiable Rewards (RLVR). First introduced by AI2’s Tülu 3, RLVR gained broader recognition with DeepSeek-R1’s large-scale implementation. Understanding RLVR benefits from examining the typical training pipeline.
Large language model (LLM) training involves two phases: pre-training and post-training. In the latter stage, reinforcement learning (RL) lets models practice generating responses, with updates guided by feedback to favor better answers over time.
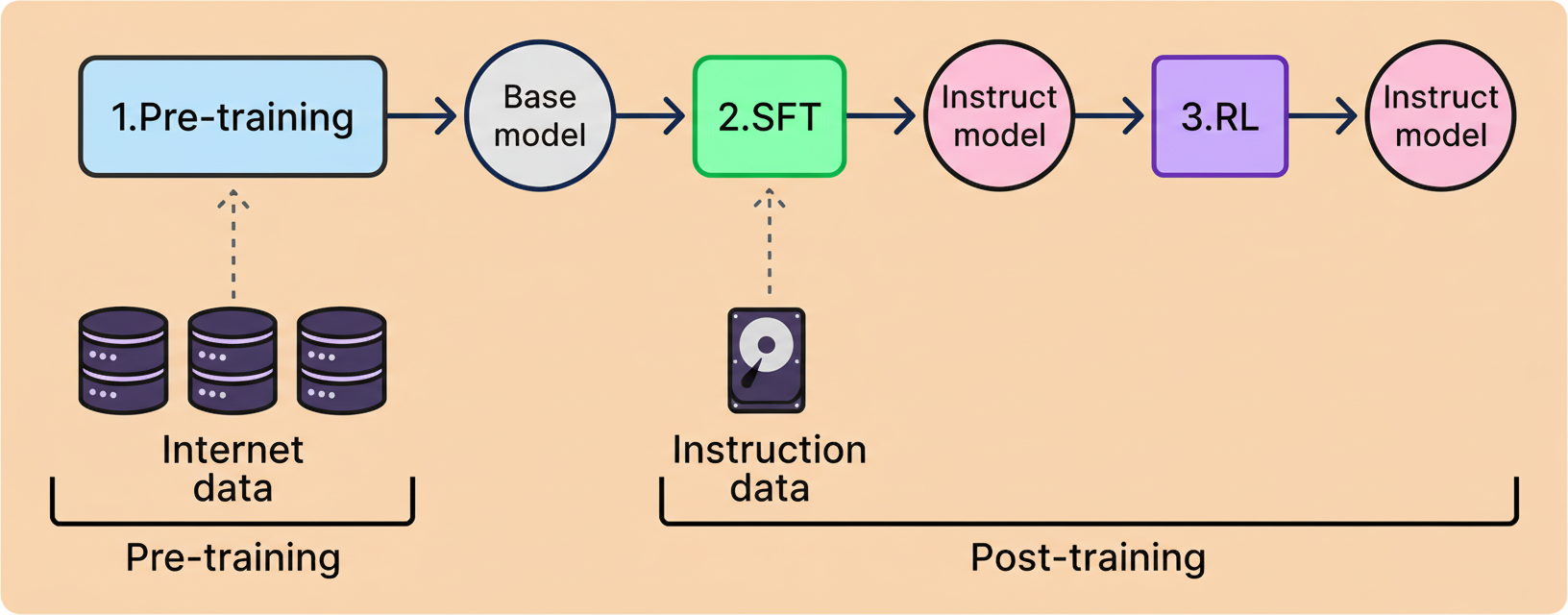
Historically, reward models, trained to approximate human preference, have driven RL training. These models relied on human-labeled data to guide LLM improvements through Reinforcement Learning from Human Feedback (RLHF).
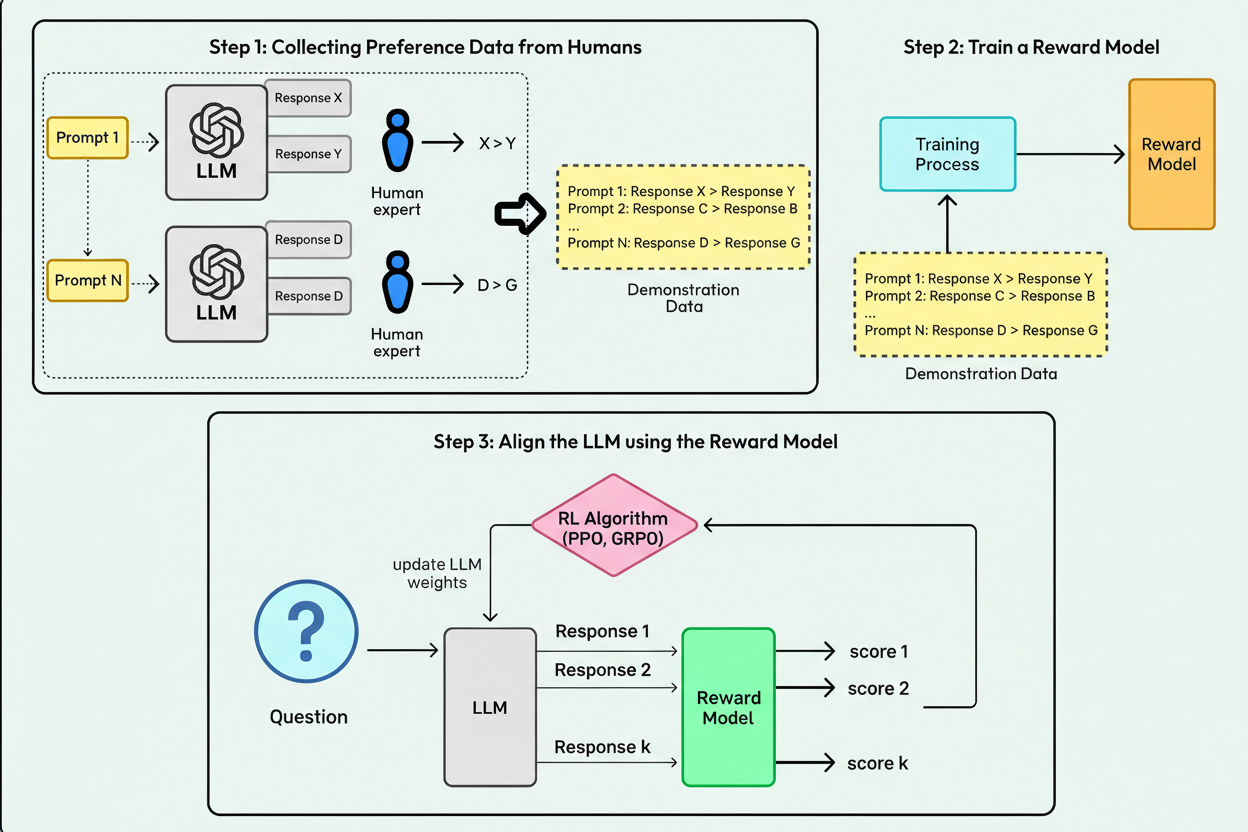
RLHF introduces bottlenecks, as human annotation is labor-intensive and costly at scale. Furthermore, human evaluators struggle with complex tasks involving extended reasoning logs.
RLVR overcomes these limitations by replacing human preference proxies with automated correctness verification. Tasks such as math and coding, which permit definitive correctness checks, enable models to receive immediate feedback without separate reward predictors.
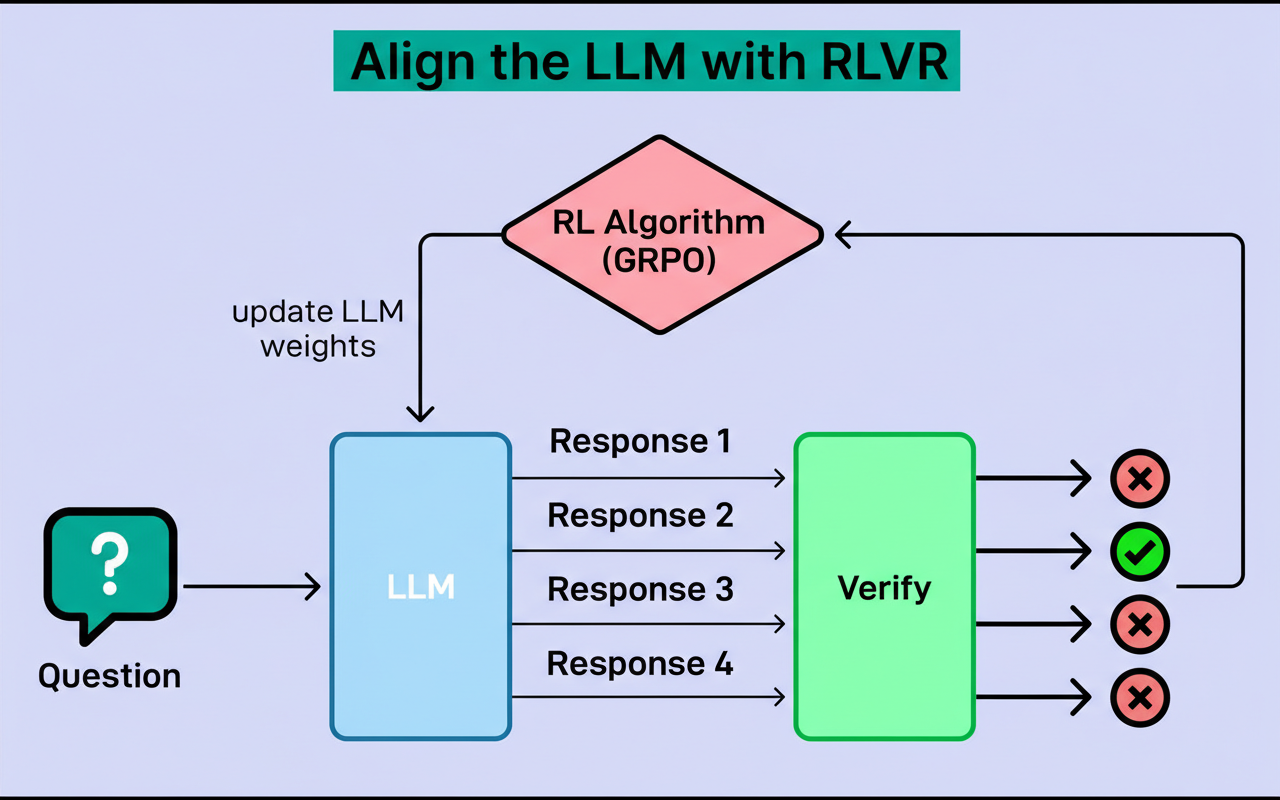
This approach supports scalable training by allowing millions of problems to be evaluated automatically and quickly. DeepSeek-R1 demonstrated that RLVR can achieve state-of-the-art reasoning, shifting main constraints from labeling to computation capacity.
Currently, reasoning integration and RLVR use are widespread among leading AI labs. Reasoning itself ceases to be a unique selling point; efficiency constitutes the prime focus.
Adaptive reasoning, in which models adjust cognitive effort depending on task complexity, is a key innovation. Instead of expending extensive tokens on simple inputs like greetings, models conserve resources for genuinely challenging prompts. Gemini 3 exemplifies this with its default dynamic thinking mode and controllable reasoning depth, optimizing speed and cost for practical deployment.
Early language models excelled at text generation but lacked direct action capabilities. Requests like flight booking could only be described theoretically, and real-time verifications of facts, such as current restaurant hours, were absent.
This gap catalyzed the development of AI agents—systems combining language models with external tools operating in iterative loops. Agents decompose goals into steps, execute relevant tools, and adapt plans based on outcomes instead of producing single-shot answers.
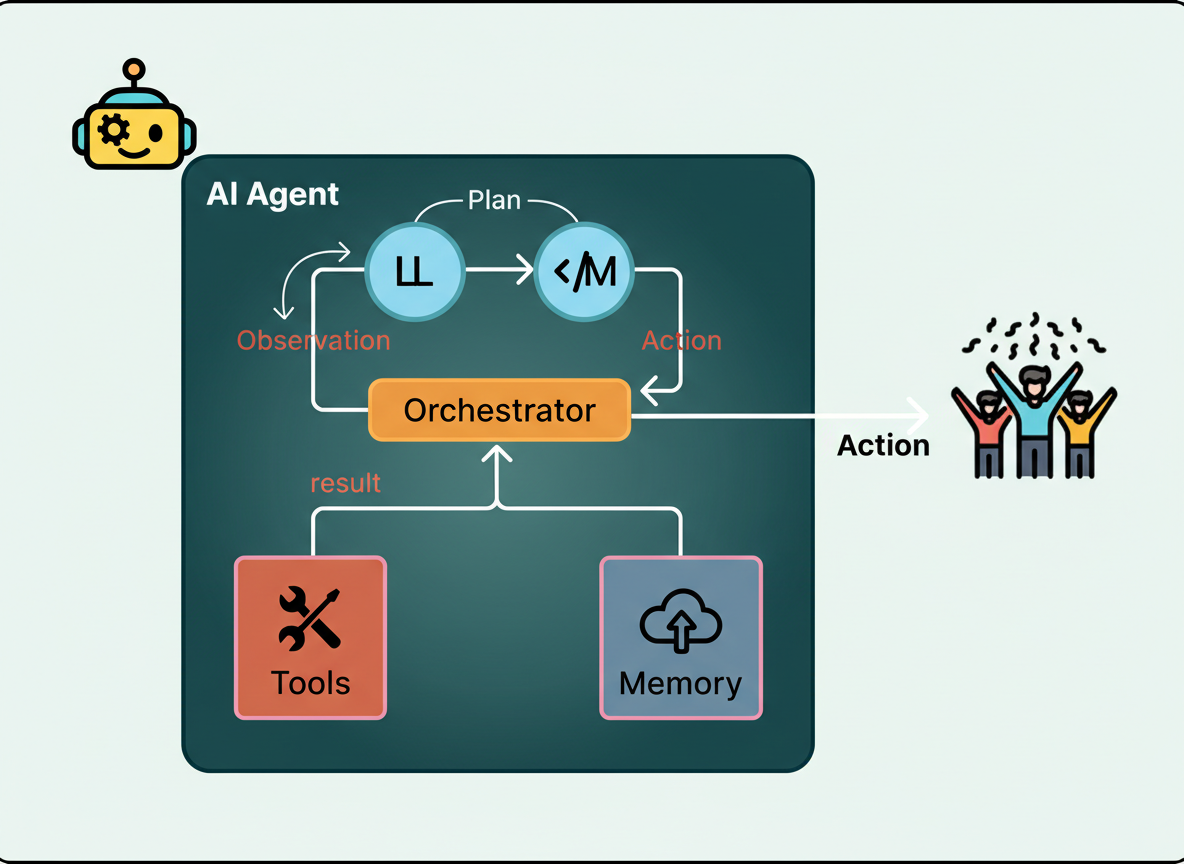
Such agents typically feature a language model deciding subsequent steps, connected tools accessing external resources like search engines or APIs, and a loop managing execution, error handling, and result inspection.
Agents have transitioned from experimental concepts to production-ready technologies. OpenAI’s ChatGPT agent can browse the internet and accomplish tasks autonomously, while Anthropic’s Claude supports multi-step problems and coding tasks.
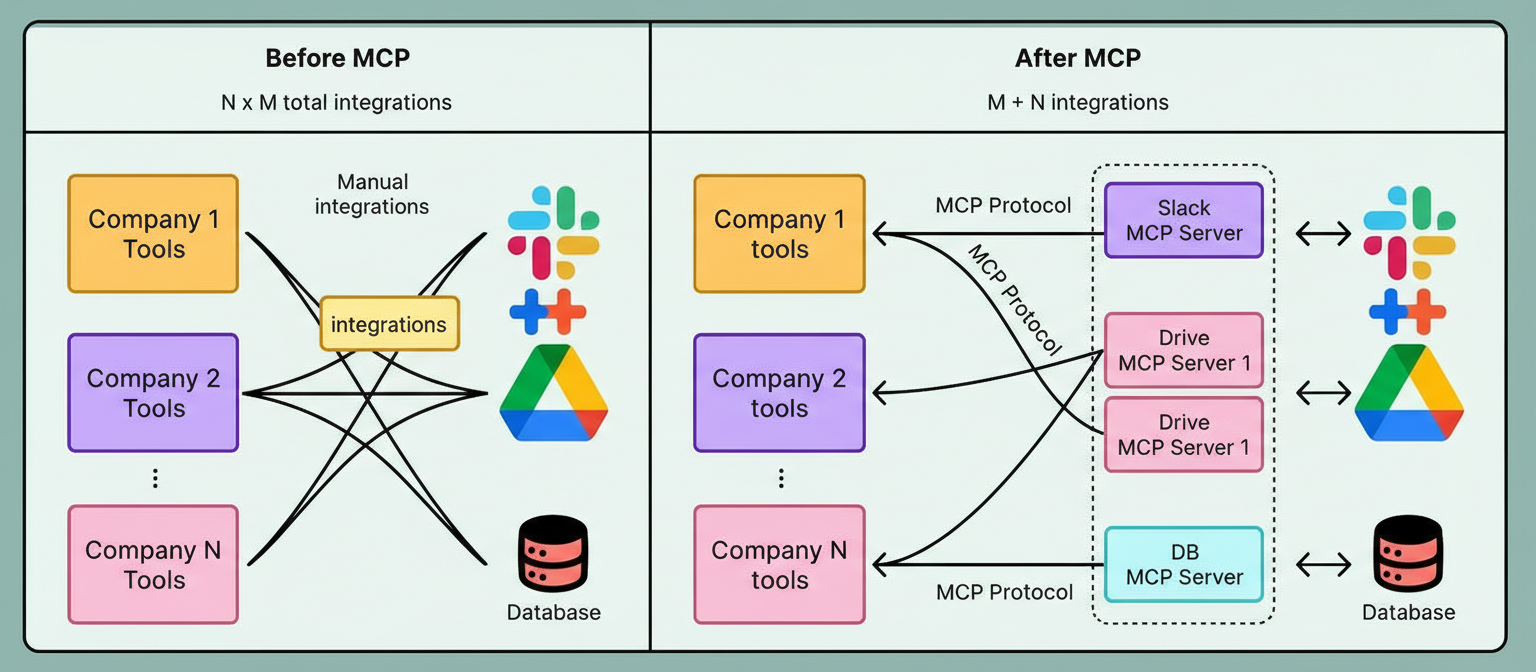
Three advancements enable this progress: enhanced reasoning for multi-step planning and intermediate state tracking; simplified tool connectivity via protocols like Anthropic’s Model Context Protocol (MCP), substantially reducing integration complexity; and mature development frameworks such as LangChain and LlamaIndex that facilitate agent creation with ready-made components.
Despite current strengths, agents face challenges with extended workflows spanning dozens of steps due to diminishing context retention and error accumulation. Sandbox restrictions limit access to user data unless explicitly connected.
Persistent agents designed for longer-lasting assistance and improved resource integration represent a growing trend. These agents often operate locally for privacy and seamless access to files, applications, and system configuration. OpenClaw exemplifies this personal hybrid, run-on-device approach.

Greater agent access amplifies security and reliability concerns. Ensuring consistent task adherence, robust error recovery, and predictable behavior under prolonged use, alongside safeguarding personal data from unauthorized or harmful actions, will be priorities throughout 2026.
AI involvement in software engineering initially focused on limited autocomplete functionality with a narrow field of context around the cursor. Full project comprehension, including structural and functional aspects, was absent.
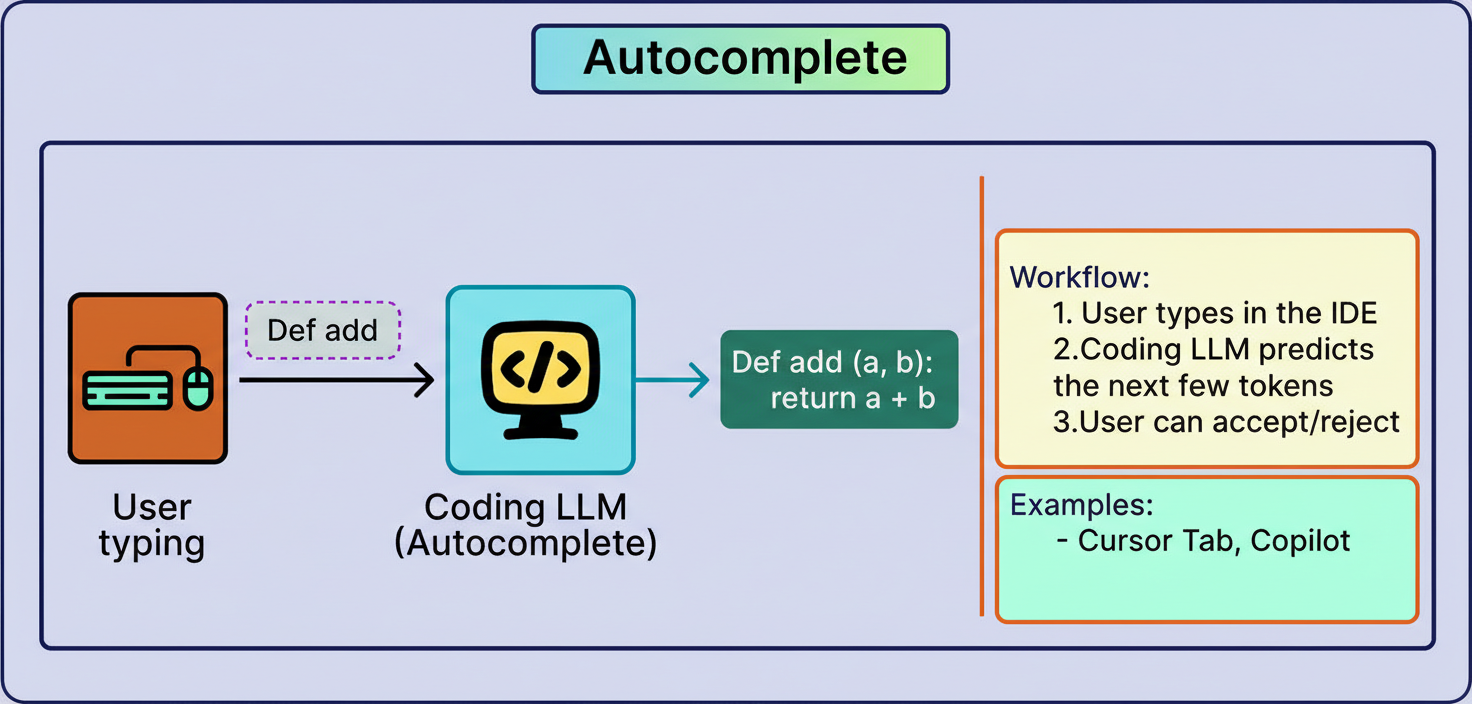
This has evolved through applying agent architectures specifically tailored to coding workflows. Models undergo fine-tuning on codebases, documentation, and programming idioms, coupled with specialized tools such as read_file, search_codebase, edit_file, run_terminal_command, and execute_tests.
Consequently, these coding agents grasp software engineering principles like project dependencies and debugging and strategically orchestrate tool use to complete complex tasks.
<0>
Leading proprietary agents like Anthropic’s Claude Code and OpenAI’s Codex have excelled by comprehending entire repositories and sophisticated project designs. Meanwhile, open-source efforts like the 80B-parameter Qwen3-Coder-Next have approached these performances while enabling local execution on consumer hardware.
<1>
Coding agents have visibly transformed developers’ daily workflows. Requests including repository-wide fixes now yield rapid, functioning patches while lowering entry barriers for novice programmers through platforms such as Replit and Lovable built atop these agents.
The future baseline extends beyond generating code to encompassing comprehensive software management. Anticipated advancements encompass improved contextual awareness across repositories addressing cross-file relations and architecture, integrated security vulnerability detection woven into workflows, and accelerated generation times for real-time responsiveness.
Initially, the most capable language models were proprietary, offered through APIs without access to model weights or local deployment options. Open-weight models existed but lagged behind in performance.
This disparity diminished swiftly via two pivotal phases: an industry-defining DeepSeek moment and subsequent rapid community momentum.
January 2025 marked DeepSeek’s release of DeepSeek-R1 with fully open-sourced weights, code, and training methodology. This reasoning model equaled or surpassed closed competitors on crucial benchmarks, proving that leading-edge reasoning does not necessitate proprietary APIs. The term “DeepSeek moment” emerged to describe such breakthroughs.
<2>
DeepSeek-R1’s training leveraged RLVR rather than the prevalent RLHF methods used by many earlier chatbots like ChatGPT, significantly reducing the dependence on human labeling and enhancing reasoning training scalability.
Following this, multiple labs published comprehensive weights and methodologies. Alibaba’s Qwen line became a platform for open innovation, Z.ai’s GLM advanced multilingual and multimodal capabilities, and Moonshot’s Kimi series integrated agentic and tool-use functions.
<3>
In August 2025, OpenAI released gpt-oss, open-weight models including 120B and 20B parameters under the Apache 2.0 license. Other contributors such as Mistral, Meta, and the Allen Institute also issued competitive open-weight models.
<4>
Accompanying detailed reports accelerated replication and improvement, firmly establishing open-weight models near parity with premier closed models across numerous benchmarks.
By 2026, open-weight releases have normalized. Focus shifts towards improving architectural efficiency—often leveraging sparse MoE designs with extended context windows, exemplified by Qwen3-Coder-Next’s ultra-sparse setup and 256k-token native context.
<5>
Agent readiness remains a priority, with open-weight models designed from inception for tool usage, structured output, and long-context reasoning to support growing autonomous workflows.
<6>
Deployment ease increases due to emerging inference formats, compression advances, and hardware vendor support treating open-weight models as first-class deployment targets.
Early chatbot iterations focused solely on text inputs and outputs, often handling images, audio, and video in isolated systems. Initial image generation was striking but inconsistent and difficult to control.
Two developments changed this landscape: the emergence of natively multimodal chatbots and significant improvements in generative media models.
Leading models like Gemini 3 and ChatGPT-5 support integrated text and image modalities within unified systems, enhancing media interaction capabilities. Open-weight models such as Qwen2.5-VL exhibit comparable vision-language competencies with broad visual insight.
This integration allows intuitive interactions, such as uploading diagrams, querying specific elements, and receiving visually grounded answers within a single conversational thread.
<7>
Image and video generation capabilities transitioned from demonstrations to practical tools. OpenAI’s Sora 2 demonstrated compelling video synthesis, while Google’s Veo 3.1 incorporated audio enhancement and advanced editing controls including object insertion. Nano Banana Pro (Gemini 3 Pro Image) improved image generation precision, particularly in text rendering and manipulation.
<8>
Two prominent areas will drive multimodal advancements: physical AI and world models.
Physical AI, encompassing robots, is moving from research toward real-world deployment. CES 2026 showcased numerous humanoid robot demonstrations. Boston Dynamics introduced the electric Atlas robot and announced a collaboration with Google DeepMind to integrate Gemini Robotics models. Tesla plans to scale production of Optimus humanoid robots.
<9>
These systems combine vision-language understanding, reinforcement learning, and planning. Jensen Huang marked CES 2026 as robotics’ “ChatGPT moment,” highlighting physical AI models capable of real-world comprehension and action planning.
Video generation models have evolved beyond pixel realism to constructing fundamental physical world representations capable of simulating physics, predicting outcomes, and reasoning about reality.
<0>
In November 2025, Yann LeCun departed Meta to found AMI Labs, funded with €500M to develop AI systems modeling physics rather than just text prediction. Google DeepMind released Genie 3, an interactive real-time world model generating persistent 3D environments. NVIDIA’s Cosmos Predict 2.5, trained on 200 million curated video clips, unifies text-to-world, image-to-world, and video-to-world generation to train robots and autonomous vehicles in simulations.
<1>
Advancements in world model training are expected to continue throughout 2026, as reliable environment simulation underpins robotics, autonomous vehicles, and other physical systems. This convergence of video generation, robotics, and simulation represents a major direction to monitor.
Rather than one defining breakthrough, 2026 will be characterized by the interplay of multiple mature capabilities reinforcing each other. Combined innovations will drive new workflows ranging from autonomous code refactoring to robots learning tasks via simulated environments, making the year a critical period for observing AI progress.