
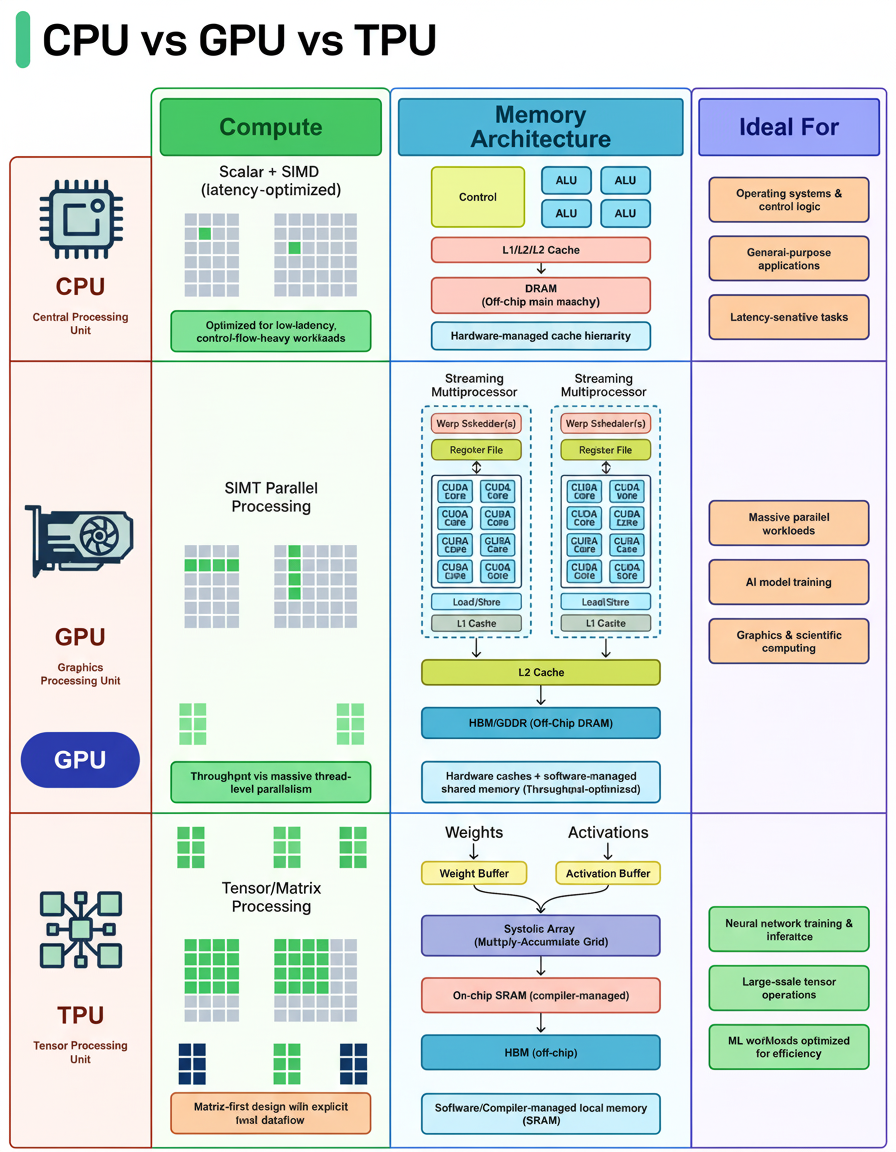
Why does the same code execute quickly on a GPU, slower on a CPU, and even faster on a TPU? The explanation lies in their distinct architectures. CPUs, GPUs, and TPUs are each engineered for specific types of workloads.
CPU (Central Processing Unit): Handles general-purpose computing designed for low latency and complex control flow, including branching logic, system calls, interrupts, and decision-heavy code. Operating systems, databases, and most applications run on CPUs due to their flexibility.
GPU (Graphics Processing Unit): Operates differently by leveraging thousands of cores to execute identical instructions simultaneously across extensive datasets (SIMT/SIMD-style). Tasks with repetitive structures such as matrix math, pixel shading, and tensor operations are efficiently processed by GPUs.
TPU (Tensor Processing Unit): Specialized hardware tailored for matrix multiplication via systolic arrays, featuring compiler-controlled dataflow and on-chip buffers for weights and activations. TPUs excel at neural network training and inference when the workload aligns well with hardware capabilities.
In system design today, selecting between CPU, GPU, and specialized accelerators requires understanding workload characteristics and architecture strengths.
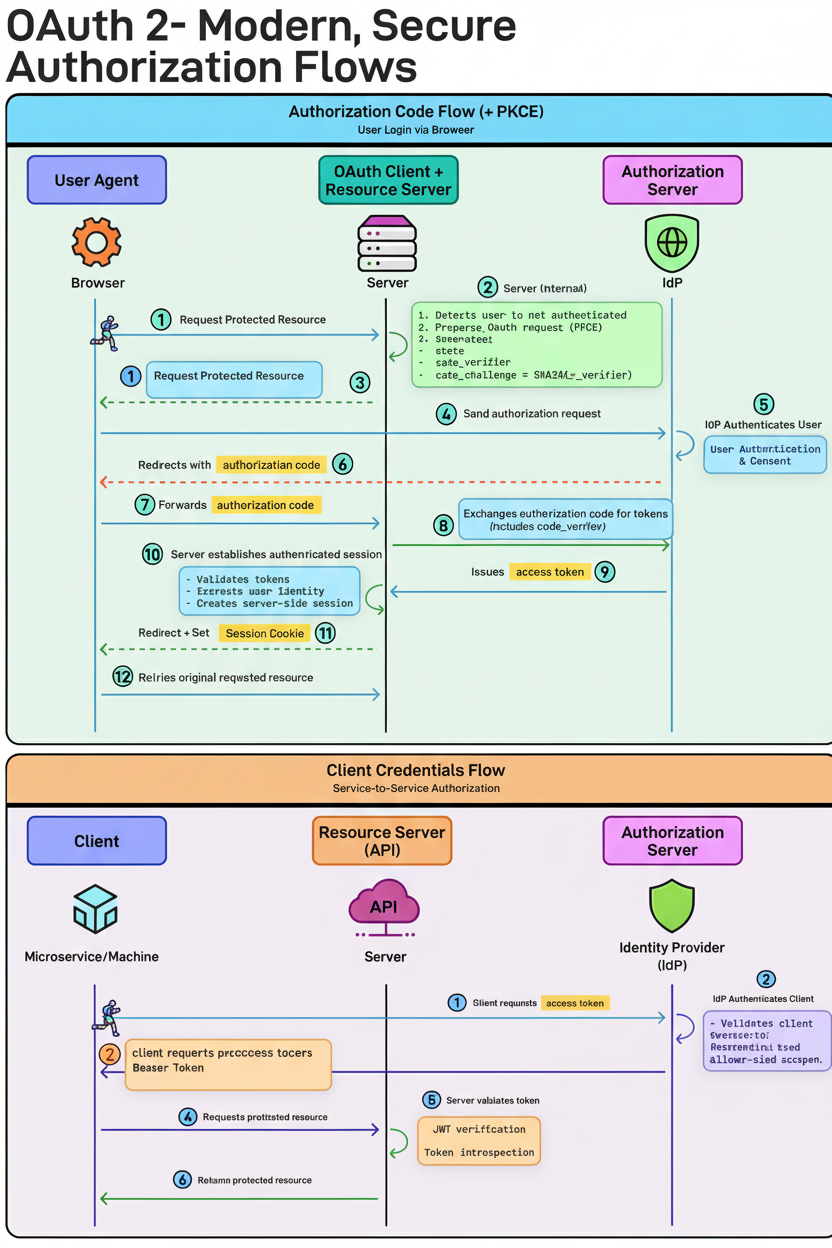
Authorization Code Flow (+ PKCE) – for user login:
The user requests access to a protected resource, prompting the server to redirect to the Authorization Server (IdP). The client generates a code_verifier and code_challenge (PKCE). After user authentication and consent, the IdP issues an authorization code. The server exchanges this code, including the verifier, for tokens, validates them, and creates a session. PKCE safeguards against intercepted authorization codes being reused, making it the contemporary default for web and mobile applications.
Client Credentials Flow – for service-to-service communication:
A service requests an access token, which the IdP authenticates before issuing. The service then calls the API using a Bearer token. This flow involves no user, representing machine identity exclusively.
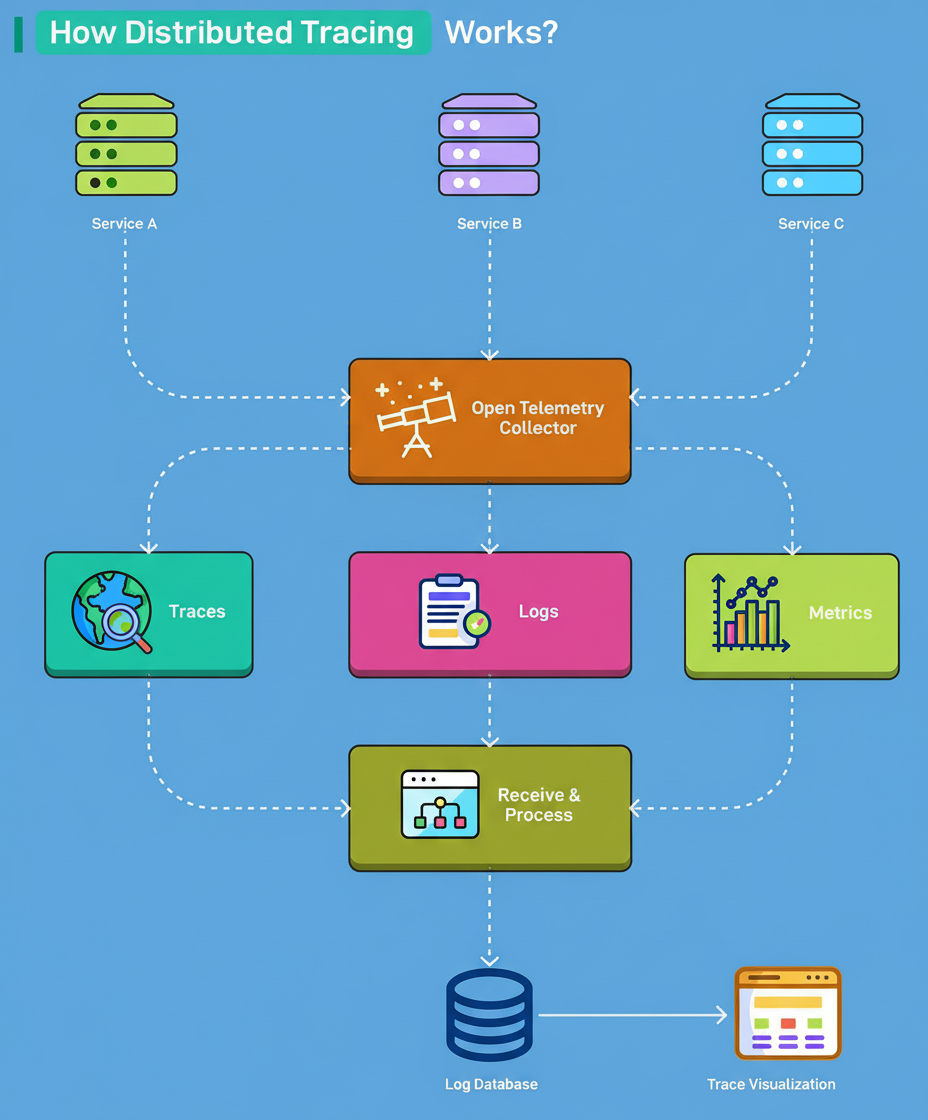
Services generate telemetry data such as traces, logs, and metrics when processing requests. The OpenTelemetry Collector gathers this data from all services in a standardized format. This collector separates the data into three streams: traces, logs, and metrics.
Each stream is directed to a Receive & Process unit that prepares data for storage and subsequent analysis. Processed data is stored in a Log Database accessible for querying and long-term retention.
Visualization dashboards then present the data for monitoring and debugging purposes, enhancing system observability and reliability.
Advanced capacity planning and insights into edge network requests per minute can be derived to optimize performance.
GPUs are powerful primarily because they are designed for extensive parallelism. This involves multiple Streaming Multiprocessors (SMs) functioning as numerous mini parallel engines across the chip. Instead of a singular core, dozens of smaller cores operate simultaneously.
Within each SM:
Each SM operates independently, linked by an on-chip interconnect. The shared L2 Cache coordinates between SMs, checking it before accessing global memory if an L1 cache miss occurs.
Memory Controllers interface with Global Memory, which offers extremely high bandwidth but with higher latency. Hence, GPUs depend on massive parallelism; while some threads await memory access, thousands continue executing uninterrupted.
An API Gateway stands between clients and services, performing functions far beyond simple routing. Key use cases include:
Handling Traffic Spikes: Rate limiting prevents a single misbehaving client from overwhelming the entire system. The API Gateway enforces policies based on user, IP, or subscription tier. If limits are exceeded, a 429 Too Many Requests response is returned, protecting backend services.
Securing Public APIs: The gateway validates bearer tokens against the Identity Provider (IdP) and manages authentication and authorization centrally, avoiding duplication across microservices.
Reducing Client-Server Roundtrips: Request aggregation allows a client to make a single request (e.g., GET /dashboard), which the gateway fans out to various backend services, consolidating responses into one JSON payload.
Supporting Multiple Clients: Different clients may require varied data. The gateway manages API versioning and payload transformation, serving rich responses to web clients (e.g., GET /v2/home) and lighter responses to mobile clients (e.g., GET /v1/home), optimizing data usage.
These functionalities critically contribute to resiliency and scalability, essential for large-scale environments such as Shopify BFCM readiness and Black Friday Cyber Monday scale testing, especially when utilizing Google Cloud multi-region deployments.