

Imagine watching a video with AI-generated subtitles where the speaker is mid-sentence—gesturing and making a point—yet the subtitles suddenly vanish. After a few seconds of blank screen, they reappear as if nothing occurred. This phenomenon, seemingly a bug, is actually a side effect of the AI’s proficiency in translation.
The Vimeo engineering team encountered this issue while implementing large language model (LLM)-powered subtitle translation on their platform. Although the translations were fluent, natural, and often indistinguishable from human work, the viewing experience was disrupted by subtitles disappearing mid-playback. The root cause was traced to the AI’s very competence.
This article examines how Vimeo’s engineering team resolved this problem and the architectural decisions they applied.
A subtitle file consists of a sequence of timed slots, each with a start time, an end time, and a text segment. The video player displays text during these intervals and shows nothing outside them. Empty slots result in blank screens.
Subtitle translation follows an implicit contract: the translated file must produce the exact number of lines as the source language, with each translated line aligned to the original time slot. Violating this contract results in empty slots and missing subtitles.
LLMs commonly disrupt this contract by prioritizing fluency. When encountering natural but fragmented human speech—such as filler words or false starts—they consolidate it into a polished sentence. For example, a speaker saying, “Um, you know, I think that we’re gonna get… we’re gonna remove a lot of barriers,” maps to two subtitle slots. Traditional translation processes each line separately, but an LLM may combine it into one grammatically correct Japanese sentence. This causes the second slot to go blank, resulting in subtitles disappearing while speech continues.
Vimeo refers to this occurrence as the blank screen bug, a frequent side effect of any capable language model translating fragmented speech.
This issue intensifies when translating beyond European languages due to fundamentally different linguistic structures. Vimeo described this as “the geometry of language,” emphasizing that sentence shape variations across languages can make one-to-one line mappings structurally impossible.
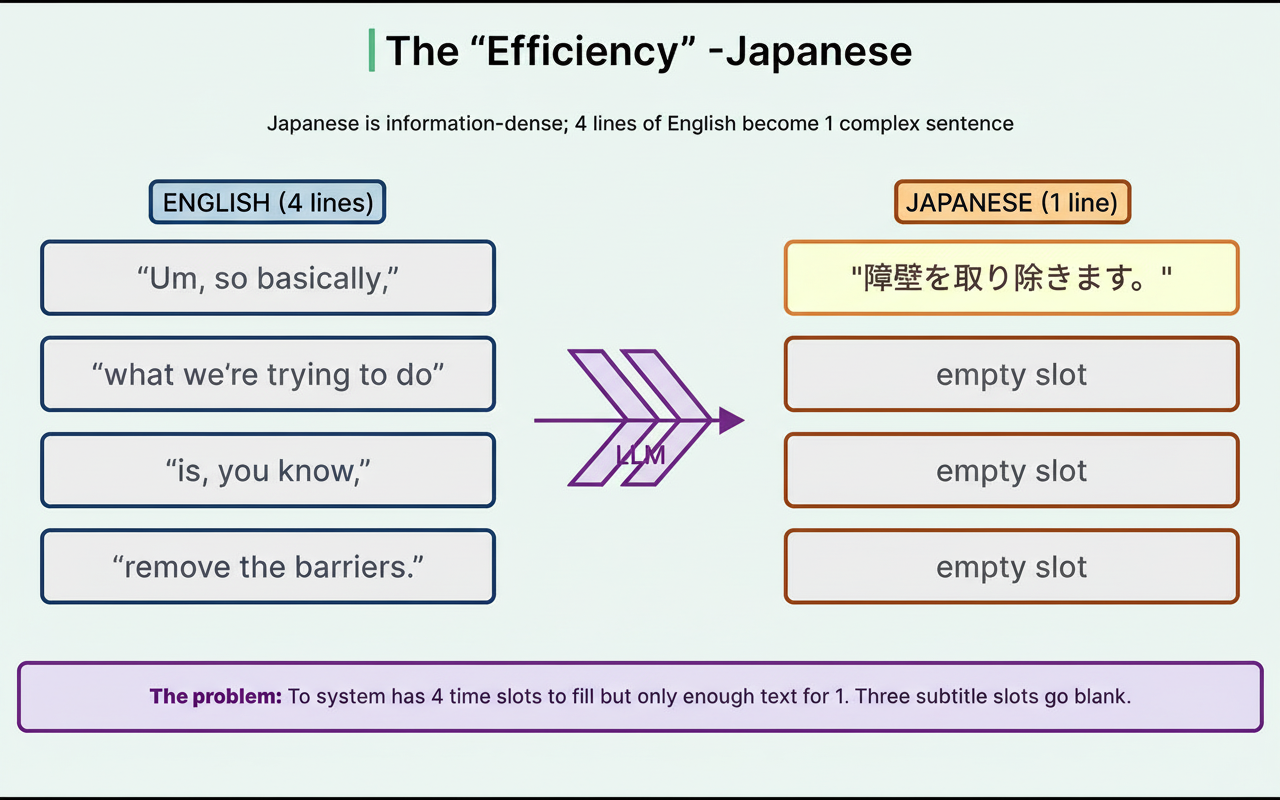
For instance, Japanese conveys more information per sentence than English. Where English uses four lines of filler speech, Japanese often condenses that into a single tight sentence. This creates a mismatch where four time slots need to be filled by one line, leaving multiple slots blank.
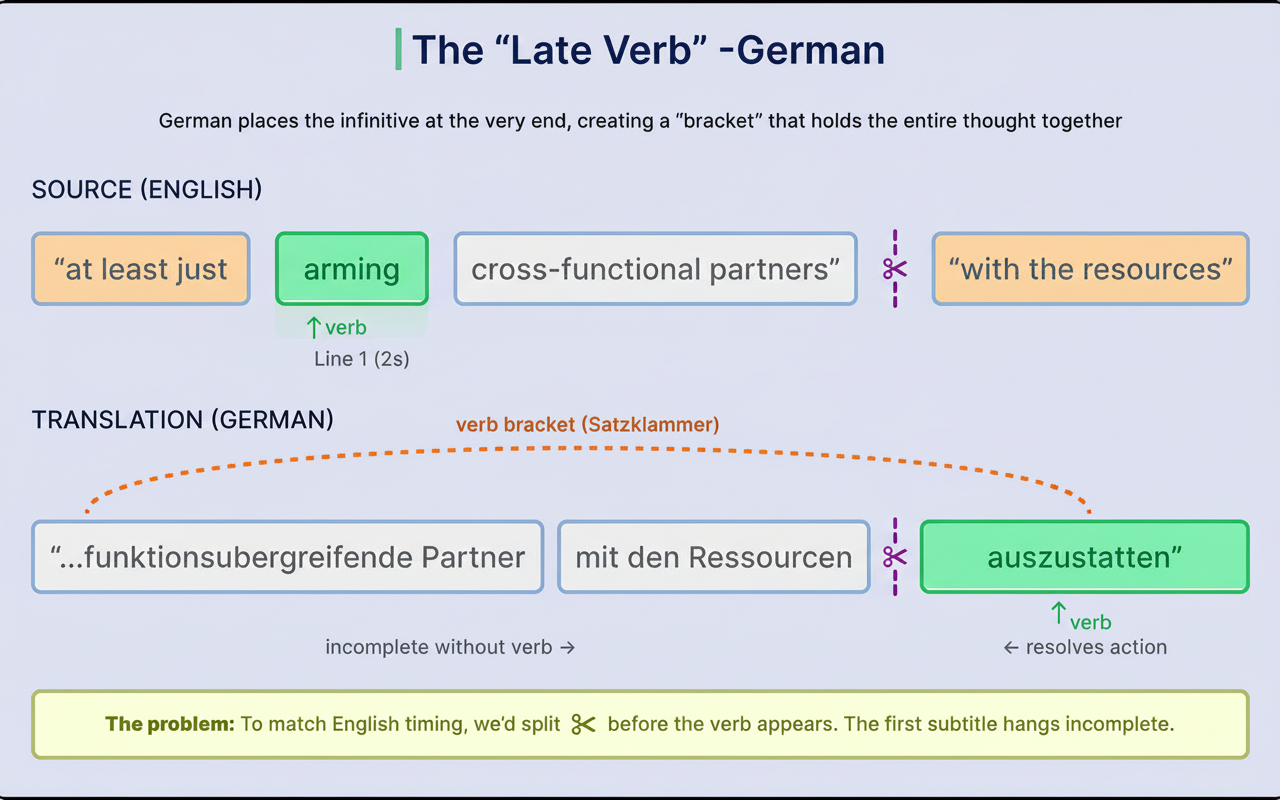
German introduces a different problem with verb placement at clause ends, known as the “verb bracket.” Splitting sentences at line boundaries can leave a subtitle grammatically incomplete, which the LLM tries to avoid by resisting split lines.
These scenarios represent distinct failure modes where the LLM succeeds in translation quality but fails to meet structural requirements. Recognizing these as separate challenges led Vimeo to reconsider their system’s architecture.
Initially, Vimeo attempted to translate and preserve line counts with one LLM prompt but found this approach ineffective. The model struggled to optimize both fluency and structural timing simultaneously.
Research supports this difficulty: imposing strict format constraints on LLMs degrades reasoning quality, making models worse at both creativity and adherence to structure.
Consequently, Vimeo divided the pipeline into three distinct phases, allowing separate optimization for creative translation and timing compliance.
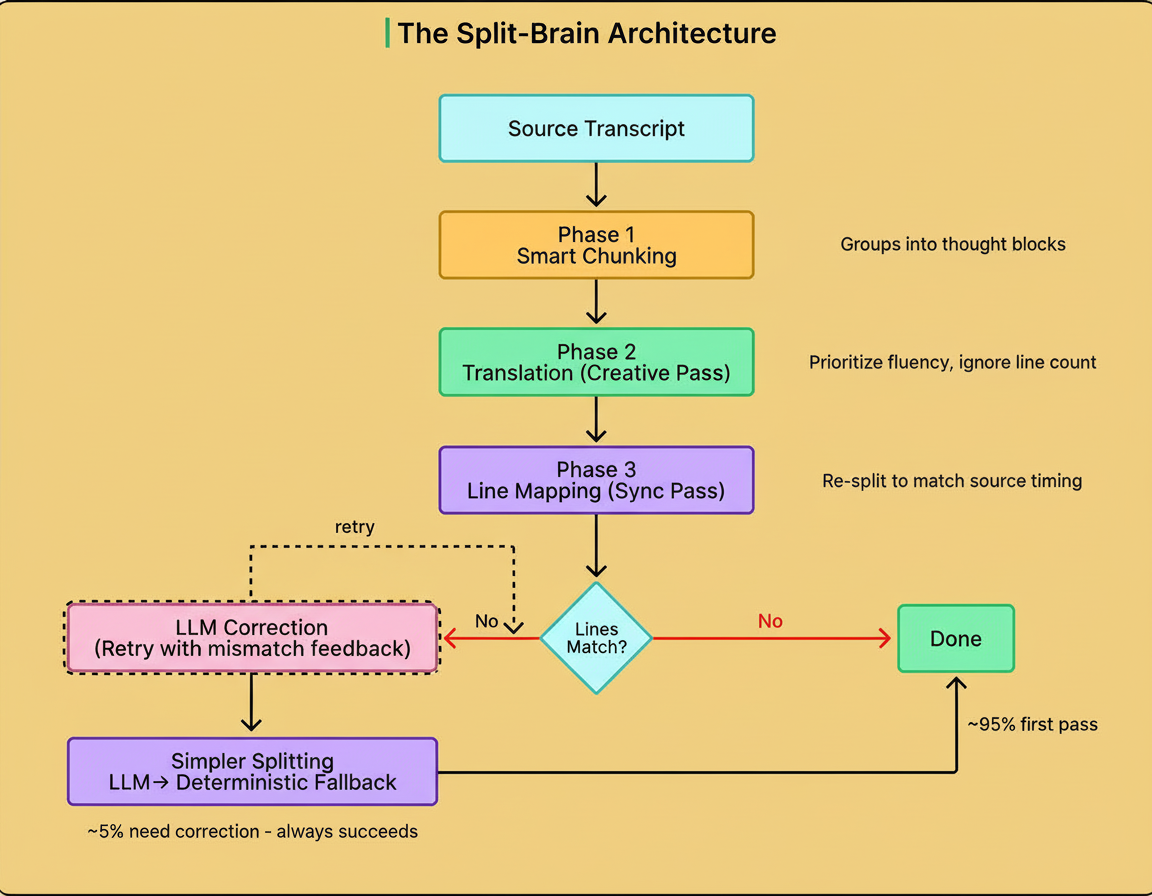
Before translation, the system groups source lines into logical segments of 3-5 lines to provide coherent context. Single isolated lines lack necessary context, while lengthy full transcripts can overwhelm and cause hallucinations.
The chunking algorithm ensures the LLM always receives complete thoughts to translate, improving both fidelity and contextual accuracy.
Each chunk is translated by the LLM without constraints on line count or structure, allowing natural handling of linguistic peculiarities such as German verb brackets or Japanese compression. The focus here is solely on translation quality and meaning.
The translated chunk undergoes a second LLM call focused entirely on structure. The prompt instructs it to segment the translation back into the same number of lines as the source, matching original timing.
Separating creativity and structure lets each phase excel at its respective task, with approximately 95% of chunks mapping perfectly on the first attempt.
While 95% accuracy is strong, Vimeo’s system supports millions of viewers across nine languages, making the remaining 5% critical to address.
Rather than expecting perfection, the system incorporates a correction loop. When mismatches occur (e.g., one translated line instead of two), it retries with explicit feedback for the LLM to refine its output. This loop resolves roughly a third of failures.
If necessary, a simpler LLM prompt focuses solely on line splitting without semantic constraints. Should the model still fail, rule-based algorithms provide final fallback by filling empty lines, duplicating text to pad shortfalls, or truncating excess lines.
This layered fallback ensures functional subtitles without blank screens, even if some phrases repeat or line splits occasionally feel awkward. Vimeo’s data indicate that 32% of failure corrections arise from the loop, with the rule-based method handling the remainder, ensuring a valid output for 100% of chunks.
This multi-pass architecture delivers effective subtitle translation with structural integrity, albeit with additional processing time (4-8%) and token cost (6-10%) compared to single-step methods. Nonetheless, it saves significant manual QA effort—around 20 hours per 1,000 videos—justifying the tradeoff at Vimeo’s scale.
Quality varies across languages due to fallback usage; structurally complex languages encounter more repeated phrases or line split artifacts. The system prioritizes continuous subtitle display over perfect quality, a deliberate product choice rather than technical inevitability.
Vimeo’s experience offers broader insights for integrating AI in products with structural constraints: first, separating creative from structural tasks optimizes outcomes; second, building robust fallback chains addresses inevitable errors; third, smarter AI demands more sophisticated infrastructure, a concept Vimeo terms the “infrastructure tax of intelligence.”
These principles are critical for anyone implementing Shopify BFCM readiness with Black Friday Cyber Monday scale testing, chaos engineering practices, capacity planning on Google Cloud multi-region setups, or managing edge network requests per minute.