
Databricks is a cloud platform that helps companies manage all their data in one place. It combines the best features of data warehouses and data lakes into a lakehouse architecture, which means any type of data can be stored and processed effectively.
Recently, Databricks developed an internal AI-powered agentic platform that has reduced database debugging time by up to 90% across thousands of OLTP instances spanning hundreds of regions on multiple cloud platforms. This innovation illustrates the application of chaos engineering and capacity planning in a Google Cloud multi-region environment.
The AI agent interprets, executes, and debugs by retrieving key metrics and logs, automatically correlating signals to simplify the engineers’ tasks. Engineers now query service health through natural language interactions without needing to contact on-call storage teams. This platform, originating from a hackathon project, has evolved into a company-wide tool unifying metrics, tooling, and expertise for managing complex databases at scale amid Black Friday Cyber Monday scale testing activities.
Before AI integration, Databricks engineers manually used multiple tools to debug database issues. The workflow involved opening Grafana to review performance metrics and charts reflecting database behavior over time, switching to internal dashboards to assess client application workloads, using command-line tools to inspect InnoDB status for MySQL internal states, and retrieving slow query logs from the cloud provider’s console.
A preliminary effort during a company-wide hackathon created a prototype unifying core metrics and dashboards into a single interface. Following this, the team conducted research by observing live on-call debugging sessions and interviewing engineers to identify challenges.
Key problems included fragmented tooling with isolated systems lacking integration, which resulted in slow, error-prone debugging due to manual data reconciliation. Incident response predominantly involved gathering extensive context rather than direct problem resolution. Engineers also lacked clear guidance or automated runbook support, leading to delays waiting for senior experts or investing significant time in investigation.
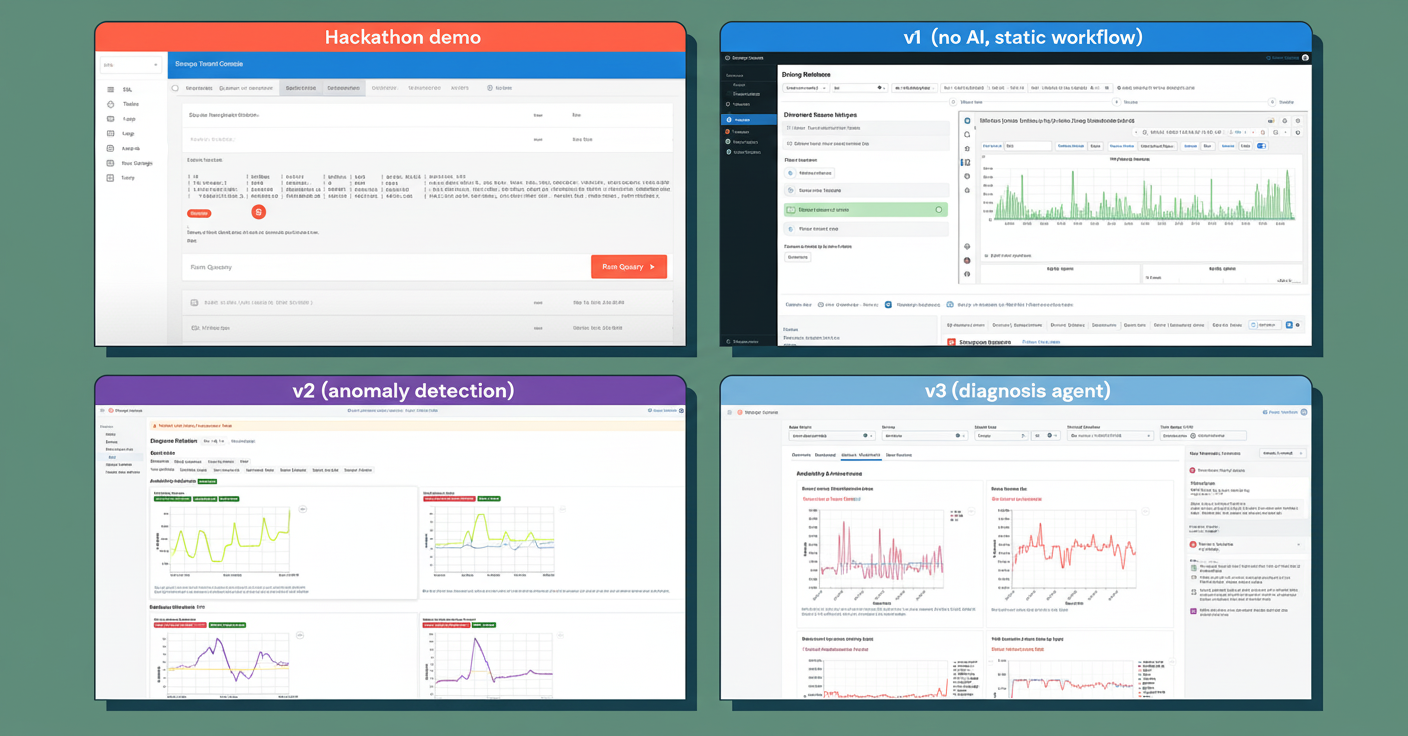
The AI debugging platform was developed iteratively over multiple versions. The initial static agentic workflow followed a fixed standard operating procedure but failed as engineers desired automatic analysis with actionable diagnostic reports rather than manual checklists.
The second version focused on anomaly detection to identify unusual database behaviors; however, it only reported issues without prescribing remediation, falling short of user needs.
The third version introduced an interactive chat assistant encapsulating expert debugging knowledge and facilitating conversational interactions, enabling engineers to ask follow-up questions and receive contextual guidance. This interactive assistant transformed debugging from isolated steps into a continuous, guided investigation process.
See the evolution journey in the diagram below:
 Source: Databricks Tech Blog
Source: Databricks Tech Blog
Before integrating AI, the Databricks engineering team established a robust architecture to handle region- and cloud-specific complexities. Operating thousands of database instances across hundreds of regions, eight regulatory domains, and three cloud providers demanded a scalable, unified approach to prevent roadblocks in AI deployment.
The architecture addresses several challenges: context fragmentation, where debugging data is scattered; unclear governance boundaries hindering permission management; and slow iteration loops caused by inconsistent cloud-region practices.
The foundation rests on three core principles creating a unified, secure, and scalable platform.
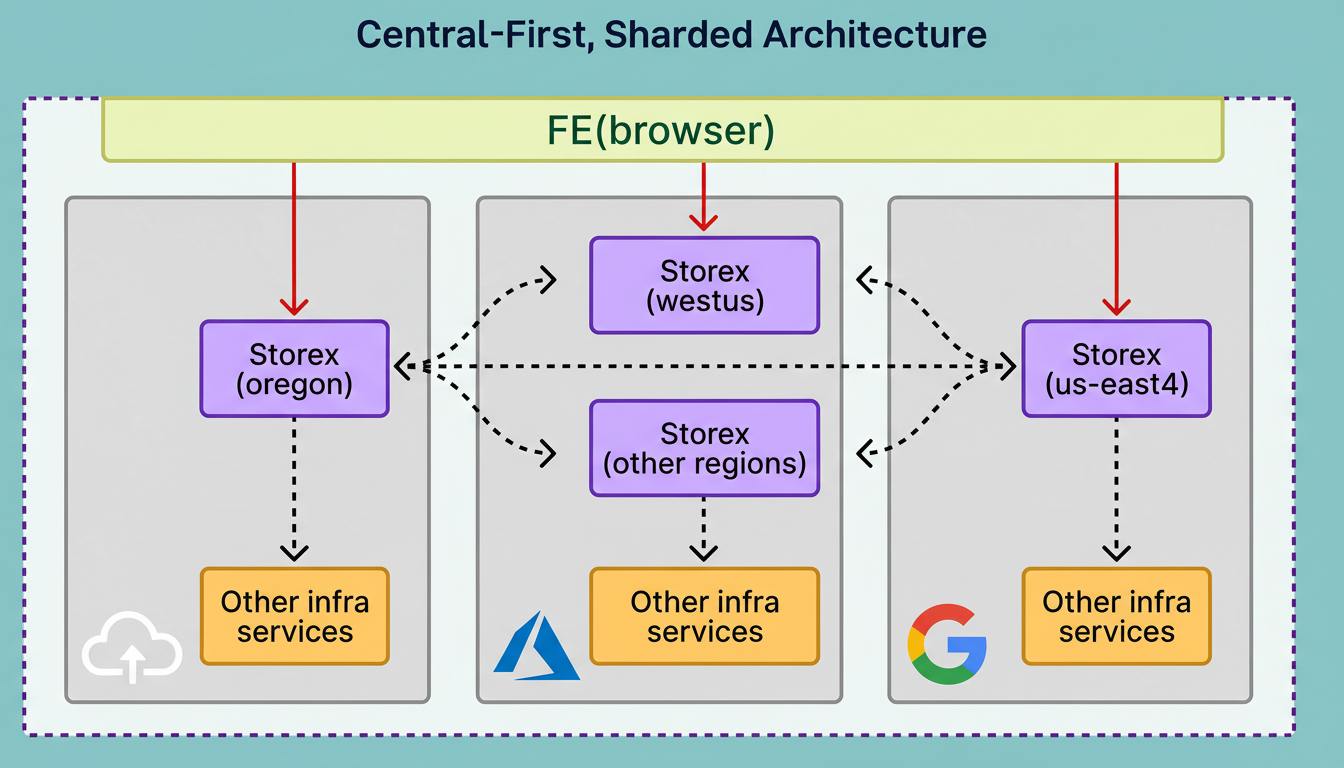
The first principle is a central-first sharded architecture featuring a central “brain” called Storex that coordinates regional system components. This global Storex instance functions as a traffic controller, providing engineers a unified interface for accessing databases regardless of physical location.
While this architecture centralizes access, sensitive data remains localized to comply with privacy and regulatory requirements. The system supports compliance across eight distinct regulatory domains with varying legal mandates on data storage and access.
The second principle establishes fine-grained access control, enforcing precise permissions at several levels:
This layered permissions framework ensures AI agents and engineers operate strictly within authorized boundaries, preventing unauthorized modifications.
The third principle is unified orchestration, integrating all infrastructure services into one cohesive system.
This creates consistent abstractions, allowing engineers to interact with databases uniformly across AWS in Virginia, Azure in Europe, and Google Cloud in Asia, eliminating the need to manage cloud or region-specific differences.
The AI agent framework draws inspiration from MLflow’s prompt optimization tools and the DsPy system. Its key innovation lies in decoupling prompt design from tool implementation. Engineers define tools with simple Scala classes describing functionalities rather than complex AI instructions.
Each tool uses a concise docstring enabling the large language model to infer input formats, output structure, and result interpretation automatically. This design supports rapid iteration, facilitating prompt experimentation and tool swapping without modifying underlying infrastructure, critical for effective chaos engineering and readiness during Shopify BFCM readiness efforts.
See the diagram below:
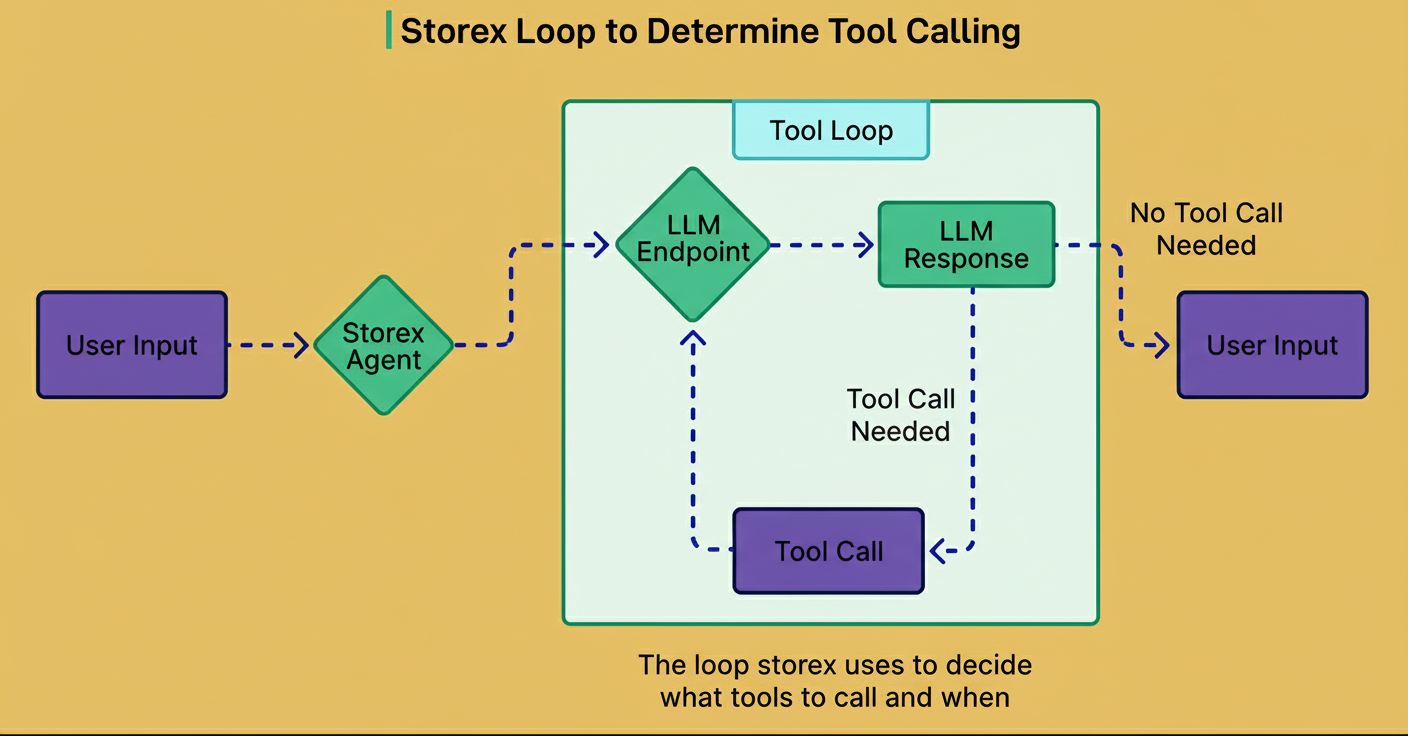
The AI agent operates within a continuous decision loop based on user input. The sequence includes:
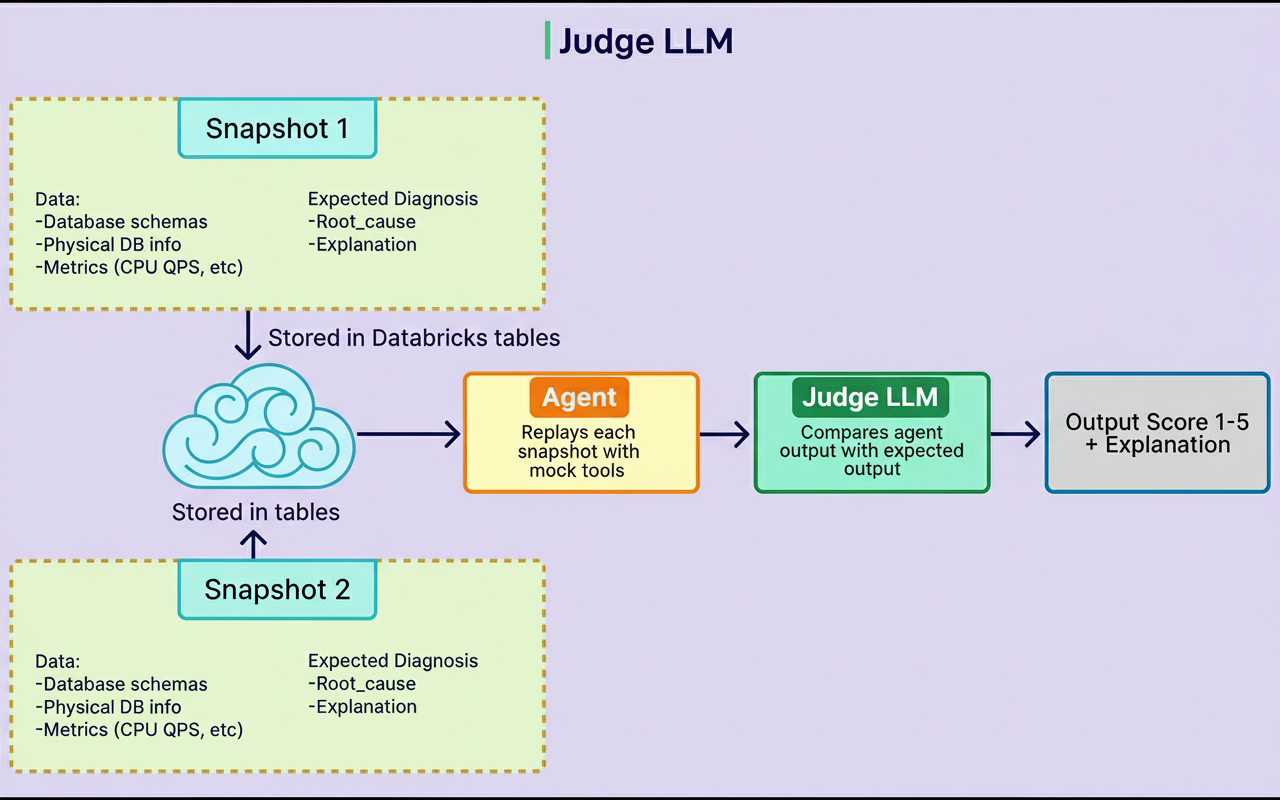
A validation framework ensures AI agent improvements do not cause regressions. It captures production snapshots representing database states, problems, and expected diagnostics—covering schemas, physical configurations, CPU usage, and IOPS.
These snapshots are replayed to the agent and assessed for accuracy and helpfulness by a judge LLM. Results are saved in Databricks tables to analyze trends and verify ongoing enhancements. This rigorous validation supports robust capacity planning for sustained Black Friday Cyber Monday scale testing under peak edge network requests per minute.
Rather than a monolithic AI agent, Databricks employs specialized agents targeting different expertise domains. A system and database issues agent addresses low-level technical problems, while a client-side traffic patterns agent focuses on application workload anomalies.
Additional domain-specific agents can be developed as needed, each with tailored prompts, tools, and context. These agents collaborate to deliver comprehensive root cause analysis, for example, correlating traffic spikes with database configuration changes.