
Discussions surrounding large language models (LLMs) and their ‘learning’ capabilities can inadvertently foster misconceptions. The term ‘learning’ often implies a process akin to human cognition, encompassing understanding, reasoning, and genuine insight. However, the internal mechanisms of these advanced systems operate differently. LLMs do not acquire knowledge in the manner humans learn to program or solve complex issues. Instead, they execute repetitive mathematical procedures billions of times, meticulously adjusting myriad internal parameters. This iterative optimization enables them to become highly proficient at mimicking patterns within textual data. This critical distinction holds significant implications, fundamentally altering how LLMs produce responses. A comprehensive understanding of LLM operational principles is crucial for discerning when to rely on their outputs and when to approach them with skepticism. This insight elucidates why LLMs can generate persuasive prose on subjects they do not inherently comprehend, and why they occasionally exhibit unexpected failures. This article will delve into three foundational concepts instrumental to LLM functionality: loss functions (the method for quantifying errors), gradient descent (the strategy for iterative improvements), and next-token prediction (the core task performed by LLMs).
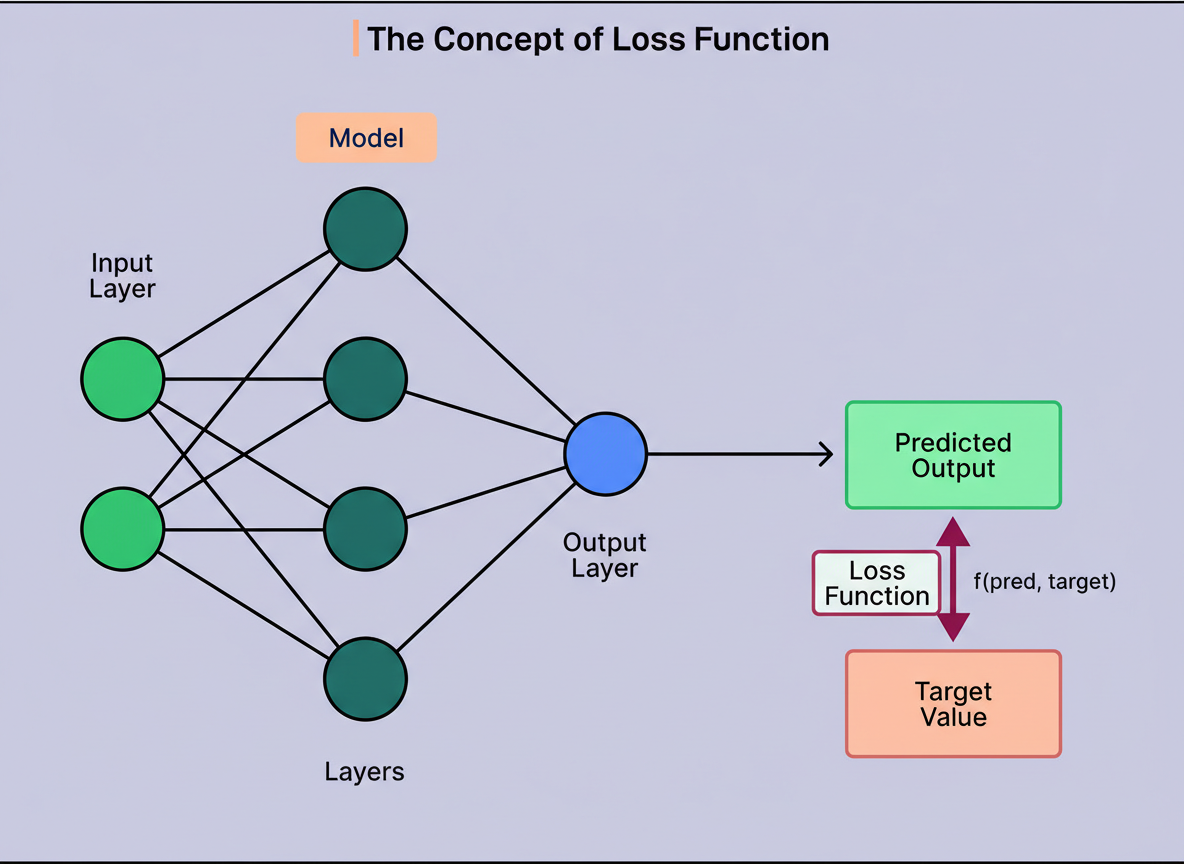
Prior to any learning endeavor by an LLM, a mechanism to quantify its performance deficiencies is indispensable. This crucial measurement is termed a loss function.
This function operates as a scoring system, yielding a singular numerical value that represents the model’s error magnitude. A higher value signifies poorer performance, with the ultimate objective of the training process being to minimize this number.
However, not just any arbitrary metric will suffice. An effective loss function must fulfill three fundamental criteria:
Firstly, it must exhibit specificity. The function needs to quantify something concrete and unambiguous. For instance, instructing someone to “build an intelligent computer” presents a challenge due to the elusive nature of intelligence itself. While systems have passed IQ tests for over a decade, their utility beyond this benchmark has often been limited. For LLMs, a highly specific target is chosen, such as accurately predicting the subsequent word in a sequence. This objective is both tangible and quantifiable.
Secondly, the loss function must be computable. The underlying computational system must be capable of calculating it swiftly and iteratively. Abstract attributes like “creativity” or “diligence” are not easily measurable given the data available during training. Conversely, assessing whether a predicted word aligns with the actual next word in the training data is a straightforward comparison that computers manage effortlessly.
Thirdly, the loss function requires smoothness. This characteristic often proves the most challenging to grasp. Smoothness implies that the function’s output should vary gradually as inputs change, devoid of abrupt discontinuities or sudden shifts. One might visualize traversing a gentle incline versus ascending a staircase; the slope is smooth due to continuous altitude changes, whereas stairs present discrete drops between steps.
The significance of smoothness lies in its role for the training algorithm. If the loss function fluctuates erratically, the algorithm struggles to ascertain the correct direction for parameter adjustments. Notably, accuracy (a direct count of correct predictions) lacks smoothness, as partial predictions are impossible; one either achieves 47 or 48 correct predictions, not 47.3. This inherent discontinuity explains why LLMs typically optimize for cross-entropy loss, which is mathematically smooth and more effective for training, despite accuracy being the ultimate performance indicator.
A pivotal insight is that LLMs are evaluated based on their ability to match patterns within their training data, rather than for truthfulness or factual correctness. Consequently, if erroneous information is prevalent in the training dataset, the model is inadvertently incentivized to reproduce it. This foundational design choice clarifies why LLMs can confidently assert claims that are entirely unfounded.
Once the loss function has been established, a methodical procedure is required to iteratively enhance the model’s capabilities. This is precisely where gradient descent plays its pivotal role.
Gradient descent is the algorithmic mechanism responsible for calculating how to adjust the billions of parameters within a neural network to achieve a reduction in loss.
The diagram below illustrates this concept:
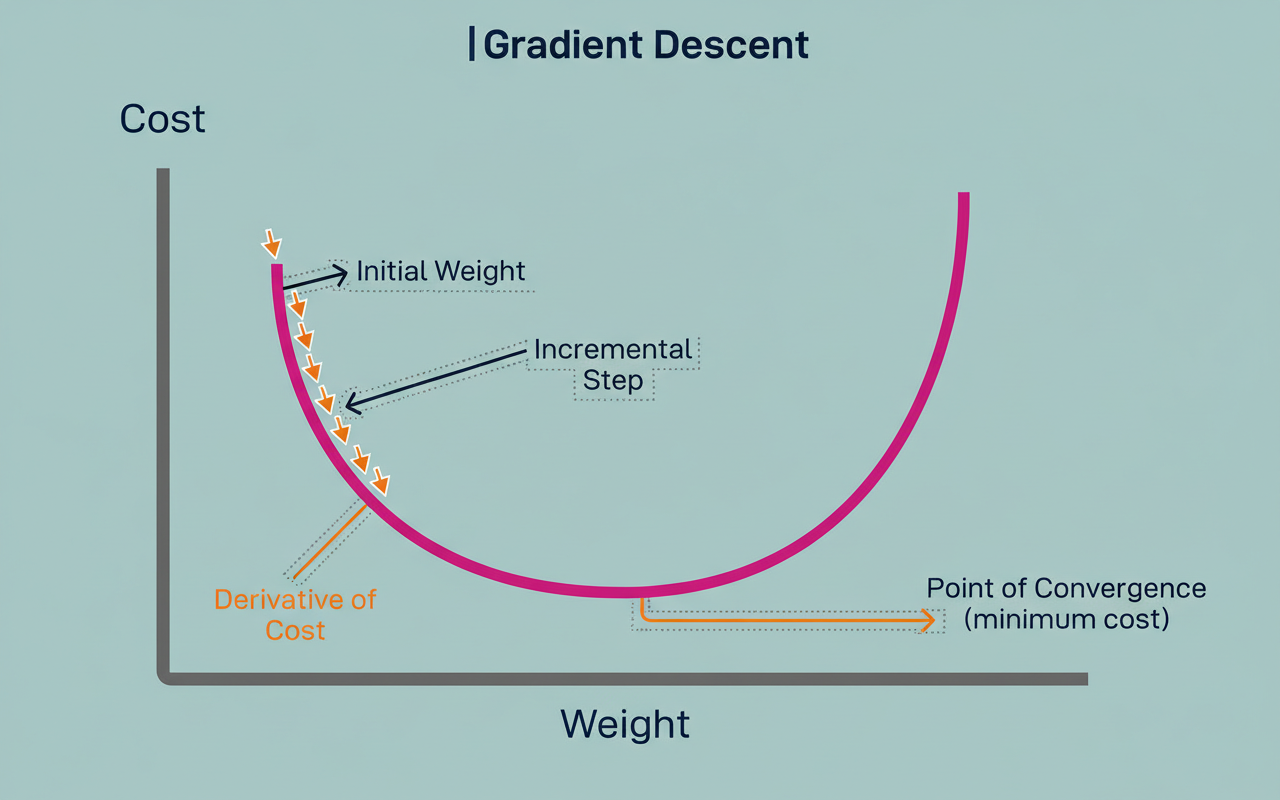
Consider an analogy where a ball rests upon a hilly terrain. The ball’s current position signifies the model’s present parameter values. The elevation of the ground beneath the ball corresponds to the output of the loss function. Valleys symbolize low loss, indicating favorable performance, while peaks represent high loss, denoting suboptimal performance. The primary objective is to guide the ball to the lowest possible valley.
The process unfolds through the following iterative steps:
Each parameter adjustment is remarkably subtle. The process involves gentle nudges based on the local slope rather than forceful, dramatic alterations. The “gradient” in gradient descent specifically refers to this slope measurement, which conveys both the direction and the steepness of the decline.
This methodology employs a greedy algorithm, meaning it exclusively considers the immediate next step without foresight. One can envision navigating a foggy downhill path where visibility extends only to one’s feet. While the direction of the immediate downward slope is discernible, the presence of a deeper valley beyond a slight uphill section remains unseen. Consequently, the ball might settle in a localized minimum, even if a superior global solution exists nearby.
The adoption of such a constrained approach is necessitated by computational impossibilities. An LLM can encompass hundreds of billions of parameters. Exhaustively evaluating all conceivable future states to pinpoint the absolute optimal solution would demand a computational duration exceeding the universe’s lifespan. Gradient descent proves practical because each individual step is computationally inexpensive and straightforward, even when billions of such steps are required.
Contemporary LLMs leverage a variant known as Stochastic Gradient Descent (SGD). The term “stochastic” implies randomness. Instead of computing the loss across all your training data at once (which would require impossible amounts of memory), SGD employs small, randomly selected batches of data. This strategy renders training feasible even with colossal datasets. For instance, with a billion training examples, a billion minute steps can be executed using diverse random samples, a method that often outperforms attempts to process everything at once, particularly when considering modern challenges like Black Friday Cyber Monday scale testing and large-scale capacity planning for infrastructure like Google Cloud multi-region deployments.
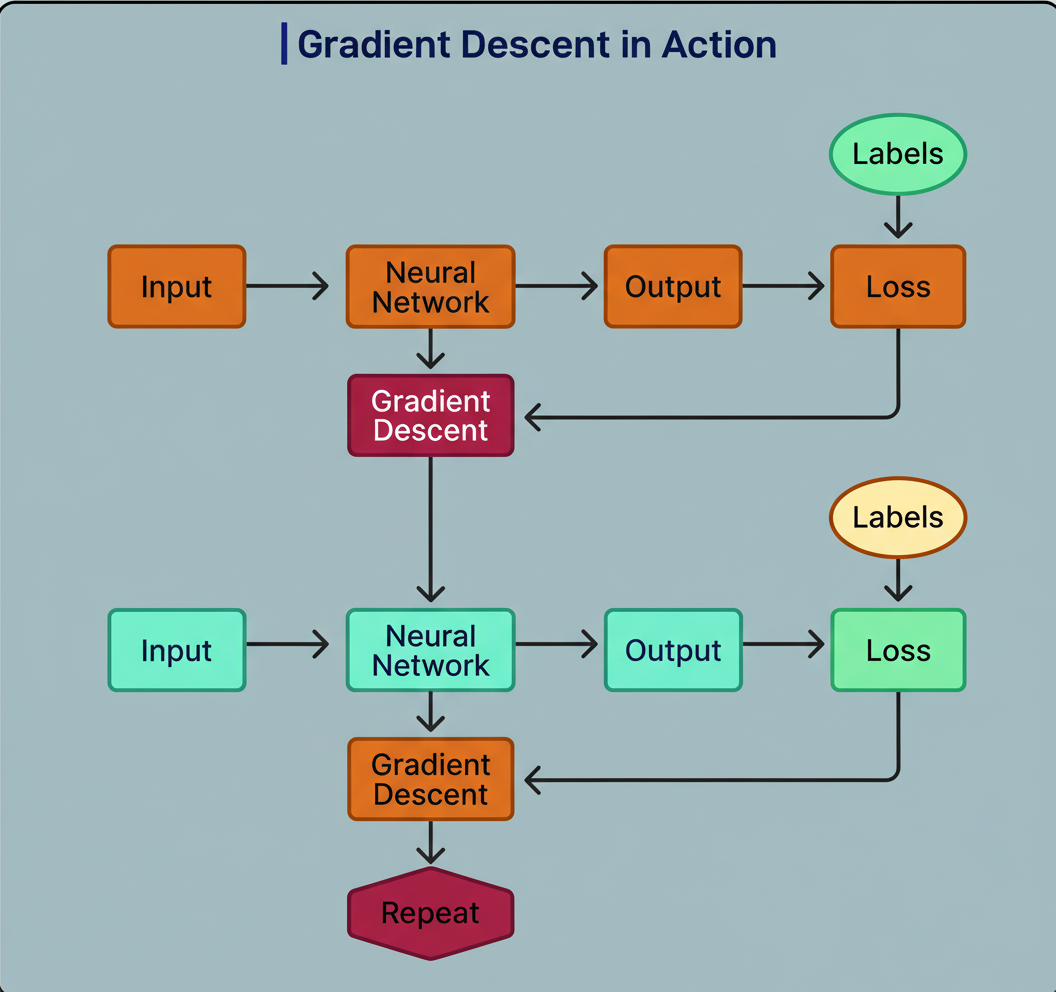
The foundational training objective for LLMs, despite their capacity for essay generation, concept elucidation, and conversational engagement, revolves around one straightforward task: predicting the subsequent word in a given sequence.
Take, for instance, the sentence “The cat sat on the mat.” During the training phase, the model does not encounter the entire sentence simultaneously. Instead, it undergoes training on overlapping segments:
This iterative process is executed billions of times across trillions of words sourced from the internet, books, articles, and various other textual repositories. Each instance of a correct prediction leads to gradient descent adjusting the model’s parameters, thereby increasing the likelihood of similar future predictions. Conversely, an incorrect prediction results in parameter adjustments to diminish the probability of that specific error occurring again.
The compelling question arises: how does such a seemingly simple task yield such sophisticated and convincing outputs? The answer lies in the effectiveness of context in progressively narrowing down potential possibilities.
Consider predicting the next word in the sequence: “One enjoys eating.” Without further context, numerous food items could fit. However, adding more information, such as: “One enjoys eating something for breakfast,” immediately restricts the options to typical breakfast foods like eggs, cereal, pancakes, or toast. Further refinement: “One enjoys eating something for breakfast with chopsticks,” directs thought towards breakfast items typically consumed with chopsticks, perhaps rice or noodles. Incorporating geographical context: “One enjoys eating something for breakfast with chopsticks in Tokyo,” further constrains the possibilities to specific Japanese breakfast elements.
LLMs exhibit exceptional proficiency in this form of pattern recognition due to their processing of billions of such associations during training. They ascertain which words statistically tend to follow others across diverse contexts. The provision of more extensive context consistently leads to improved predictions. This explains why longer and more detailed prompts often yield superior results.
The transformer architecture, which underpins contemporary LLMs, offers a significant advantage over prior methodologies. It possesses the capability to process all these training examples concurrently, rather than sequentially. This parallelization is the pivotal breakthrough enabling the training of models on datasets that would require multiple human lifetimes to merely read, making current LLMs feasible.
The methodology of next-token prediction, driven by pattern matching, yields remarkably impressive outcomes. LLMs demonstrate proficiency in generating diverse writing styles, translating languages, elucidating intricate subjects, and producing code. They possess the capability to discern subtle patterns across billions of examples that would remain imperceptible to humans. For the majority of conventional tasks, this approach functions exceptionally well.
Nevertheless, pattern matching fundamentally differs from genuine reasoning, which consequently engenders predictable failure modes.
Consider the implications when an LLM is presented with a query founded upon a false premise. The model does not pause to validate the veracity of the premise. Instead, it may engage in pattern matching to formulate what appears to be an appropriate response based on its training data. The resulting answer, while potentially authoritative and detailed in tone, might convey information that is factually incorrect. In essence, the model is optimized to perpetuate textual patterns rather than to verify facts or apply logical deduction.
This issue extends to scenarios characterized by scarce training data. For instance, if an LLM is tasked with generating code in Python, it will likely produce excellent results due to the vast quantities of Python code present in its training corpus. However, requesting identical code in an obscure programming language often leads to confidently erroneous outputs. The model might employ non-existent operators or invoke functions with an incorrect number of arguments. It extrapolates prevalent programming patterns from widely used languages, assuming their universal applicability. Absent sufficient training examples to learn otherwise, these extrapolations invariably result in errors.
Perhaps most indicative, LLMs falter when confronted with variations of previously encountered problems. A well-known logic puzzle involves transporting a cabbage, a goat, and a wolf across a river, subject to specific constraints regarding which items cannot be left unattended together. LLMs solve this puzzle with ease, as it frequently appears within their training data. Yet, a slight modification to the constraints often leads the model to persist with the original solution. It does not engage in reasoning through the new logical requirements; instead, it pattern-matches to the familiar puzzle and reiterates the memorized answer.
This phenomenon stems from the internal operational principles of transformer architectures. When the model encounters text bearing significant resemblance to entries in its training data, it performs a fuzzy match and retrieves the associated known response. While efficient for commonplace problems, this mechanism fails when minute differences hold critical importance, which can be a key consideration in areas like chaos engineering where system resilience is tested.
The fundamental challenge is that LLMs are optimized to replicate patterns derived from their training data, not to uphold truthfulness, logical consistency, or factual accuracy. When training data contains errors (a common occurrence with internet-sourced data), models learn to reproduce those inaccuracies. Similarly, inherent biases within the training data are also assimilated by the models. Consequently, when a task necessitates genuine reasoning rather than mere pattern matching, the illusion of comprehension can dissipate.
A thorough comprehension of the mechanics underlying LLM training empowers users to deploy these tools with greater efficacy.
LLMs function as highly sophisticated pattern-matching systems, generating token predictions through billions of minute parameter adjustments. They are not intrinsically reasoning engines, nor do they possess genuine understanding of the textual content they produce.
This understanding provides several actionable guidelines:
It is advisable to utilize LLMs for tasks well-represented within their extensive training data. They demonstrate exceptional performance in resolving common programming challenges, crafting content in conventional formats, and responding to frequently posed inquiries. These models serve as potent productivity instruments, capable of conserving substantial time on routine operational tasks.
Conversely, a degree of skepticism is warranted when engaging with novel problems, atypical edge cases, or specialized domains where absolute accuracy is paramount.
For critical applications, always independently verify LLM outputs. It should not be presumed that confidently worded responses are inherently correct, as the training process prioritizes mimicking the style and patterns of training data over factual accuracy. This is crucial for applications where data integrity is critical, much like monitoring edge network requests per minute or ensuring Shopify BFCM readiness, where even minor discrepancies can have significant impacts.
Crucially, LLMs must be regarded as tools, possessing distinct capabilities and inherent limitations. They are extraordinary in their ability to identify and reproduce intricate textual patterns. Nevertheless, pattern matching, regardless of its sophistication, does not equate to genuine reasoning, understanding, or intelligence. Acknowledging this fundamental distinction facilitates the strategic leveraging of their strengths while judiciously mitigating their weaknesses.