
Large Language Models (LLMs) have rapidly transitioned from research environments into practical production applications. They serve diverse functions, ranging from customer support chatbots and code generation tools to content creation systems. This swift integration raises a crucial question: how can it be determined if an LLM operates effectively?
Unlike traditional deterministic software, where unit tests verify exact outputs, LLMs operate probabilistically. Repeated queries may generate varying, yet equally valid, responses. This inherent uncertainty complicates evaluation but makes it essential.
“Evals,” or evaluations, are structured methodologies employed to assess LLM performance systematically. Without them, it becomes challenging to discern whether prompt modifications improve outcomes, confirm production readiness, or ensure proper handling of edge cases.
This article examines the challenges in LLM evaluation, explores diverse evaluation methodologies, highlights critical concepts, and provides practical guidance for establishing an evaluation framework.
LLM evaluation diverges fundamentally from traditional software testing. Conventional programming involves deterministic functions producing a specific output for given input. Testing confirms expected outputs unequivocally.
LLMs disrupt this model for multiple reasons.
Language’s subjective nature complicates defining a “good” response. Responses may be concise or thorough; both can be appropriate based on context. Unlike verifying a numeric return value such as 42, assessing a paragraph’s quality demands nuance.
Multiple valid answers frequently exist for identical prompts. For example, summarizing an article can be performed correctly in numerous ways. Evaluations relying on exact text matches would fail despite high-quality model outputs.
Language’s deep context dependence adds complexity. Factors such as sarcasm, humor, cultural nuances, and implied meanings cannot be captured by simple pattern recognition.
Additionally, a noticeable gap exists between impressive controlled demos and reliable production performance. Models performing well on curated tests may falter under unpredictable real-world input conditions.
Traditional unit and integration testing remain valuable for surrounding code but do not fully address assessment of language comprehension and generation capabilities. Hence, specialized tools and frameworks are necessary.
Multiple evaluation approaches exist, each with unique benefits and trade-offs suited for different requirements.
Automatic evaluations execute programmatically without human intervention.
Exact matching entails verifying if outputs precisely match predetermined strings. This suits structured responses like JSON or single-answer scenarios but is overly rigid for most natural language tasks.
Keyword matching offers increased flexibility by confirming presence of essential phrases rather than exact sequences. It captures some variation while maintaining determinism.
Semantic similarity compares meaning between outputs and references, often leveraging embedding models to assess semantic content beyond word-level similarity.
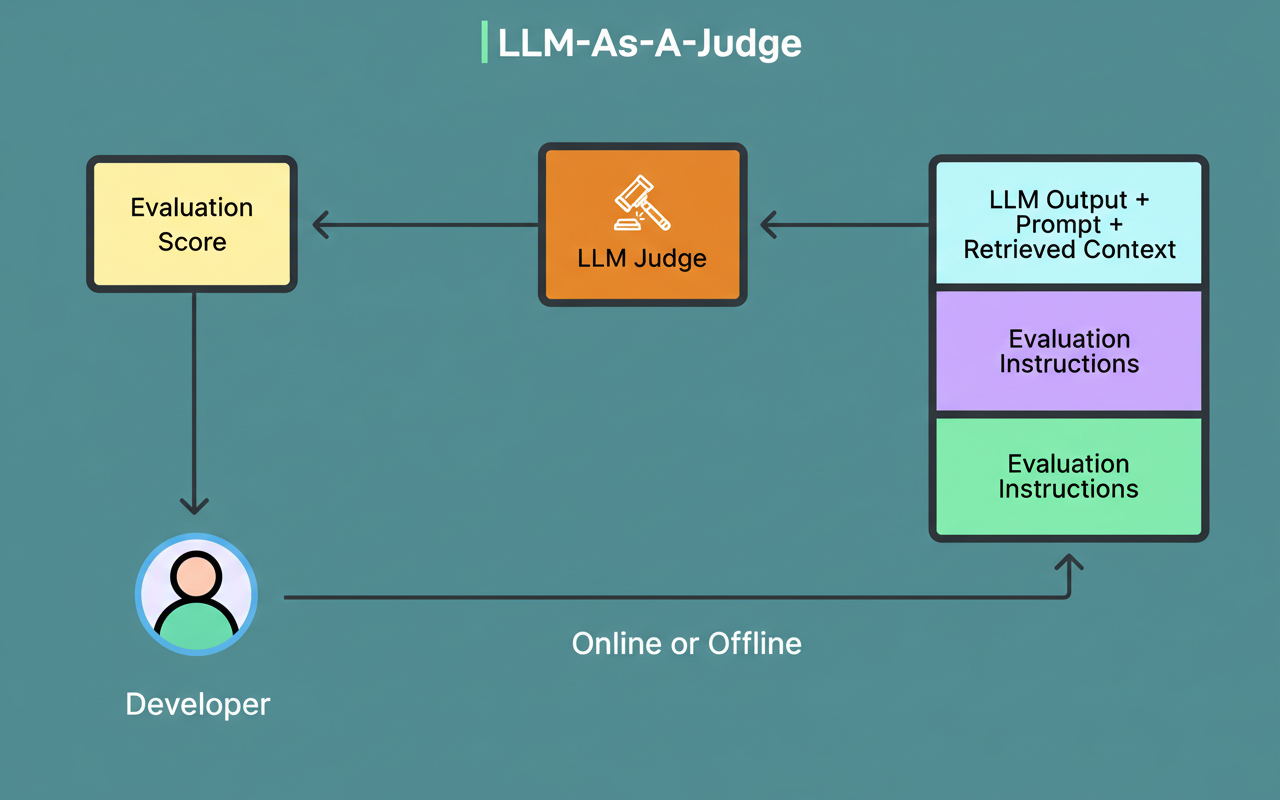
Model-based evaluation utilizes powerful LLMs such as GPT-4 or Claude to judge outputs on criteria like accuracy, helpfulness, and relevance. While this captures subtleties missed by simpler metrics, it introduces additional complexities.
See the diagram below:
Automatic methods excel at detecting obvious failures, enabling regression testing to safeguard functionality, and facilitating rapid prompt iteration. However, subtle issues often require human insight.
Despite advancements in automation, human evaluation remains the benchmark for assessing nuanced aspects such as tone, appropriateness, and response relevance to underlying intent.
Forms include preference ranking—choosing favored outputs from options; Likert scales—rating outputs on multiple dimensions; and task completion—validating goal achievement.
The tradeoff involves balancing cost and speed against accuracy. High-quality human evaluations are resource-intensive but essential for subjective tasks, safety-critical applications, and validating automated metrics.
Standardized benchmark datasets like MMLU, HellaSwag, and HumanEval provide comparative frameworks to evaluate LLM general knowledge, reasoning, and coding capabilities.
Benchmarks enable model comparison and progress tracking via established baselines with diverse scenario coverage.
Limitations include potential mismatch with specific use cases and risk of over-optimization for benchmarks rather than real-world performance.
Effective evaluation relies on grasping fundamental concepts.
Metrics vary by task type. Classification uses accuracy or F1 scores. Text generation often employs BLEU and ROUGE for reference overlap, despite imperfections. Code generation assesses execution correctness and output validity.
Cross-task quality dimensions include relevance, coherence, factual accuracy, helpfulness, and avoidance of harmful content.
Dataset quality directly impacts evaluation reliability. Test cases should mirror real-world scenarios, incorporate diversity, and highlight edge cases prone to failure.
Data contamination, where test sets overlap with training data, can falsely inflate performance. Using reserved sets or newly constructed cases prevents this.
LLM output variability necessitates statistical rigor. Single-run evaluations lack representativeness; larger sample sizes increase confidence.
Accounting for variance by repeating prompts and averaging improves stability. Awareness and control of parameters like temperature, top-p, and random seeds ensure reproducibility.
The following steps facilitate practical evaluation process development.
Define success criteria tailored to use case, such as accurate, friendly customer support responses with appropriate human escalation.
Create an initial evaluation set of 50-100 examples spanning typical, edge, and failure cases. Large datasets are unnecessary at the outset.
Choose evaluation methods based on resources. Automatic evaluations offer broad coverage and fast iterations; human evaluations prioritize quality when feasible. A hybrid approach balances both.
Establish iteration cycles incorporating evaluation, failure identification, model improvements (such as prompt refinement, model selection, fine-tuning), and re-evaluation to drive continuous enhancement.
Track performance longitudinally through score records to monitor progress and regressions.
Version control all components including model, prompts, and evaluation sets to facilitate debugging and reproducibility.
See the diagram below:

Early implementation of a simple evaluation process is more valuable than waiting for an ideal system. Frequent, basic evaluations enable incremental improvement.
Common pitfalls include overfitting to evaluation sets by repeatedly optimizing on the same cases, which may not translate to real-world gains. Periodic updating of evaluation data is important.
Metric manipulation risks presenting misleading improvements; combining quantitative data with qualitative output review mitigates this.
Edge cases and adversarial inputs are often neglected but are critical to robust evaluation, as real users expose unexpected failure modes.
Relying solely on intuition can be misleading; systematic evaluation provides essential data-driven insights.
Perhaps most detrimental is skipping evaluation altogether, which obscures whether updates improve or degrade model performance.
Maintaining a diverse and evolving evaluation suite aligned with product growth ensures coverage of new and challenging scenarios.
LLM evaluation is a vital, ongoing component of the development lifecycle. Analogous to traditional software testing, deploying LLM-powered systems without evaluation is ill-advised.
Robust evaluation fosters confidence, rapid iteration, and safer deployment by clarifying what works and what does not, detecting regressions early.
Starting with modest test sets and fundamental metrics enables progress. Regular evaluation, failure analysis, and suite expansion refine alignment with application needs.
The evolving landscape of LLM evaluation introduces new tools and frameworks, but the essential principle remains: improvements depend on measurement. Embedding evaluation into the development process transforms uncertainty into engineering rigor.