
Users often seek specific information within an application, yet the desired answer can frequently be obscured amidst numerous reviews, photos, and structured data points. While contemporary content platforms are rich with information, extracting direct answers often presents a significant challenge. Yelp business pages exemplify this situation. Consider a scenario where a user, when deciding on a venue, inquires, “Is the patio heated?”. The answer might exist across several reviews, a photo caption, or an attribute field, necessitating a scan through multiple sections to consolidate the information.
A prevalent solution involves integrating an AI assistant directly into the application. Such an assistant system retrieves pertinent evidence and synthesizes it into a concise, direct answer, complete with citations referencing the supporting snippets.
Figure 1: AI Assistant in Yelp business pages
This article explores the complexities involved in deploying a production-ready AI assistant, utilizing the Yelp Assistant on business pages as a practical case study. It delves into the engineering challenges, architectural trade-offs, and valuable lessons derived from the development of the Yelp Assistant.
This article was developed in collaboration with Yelp. The Yelp team provided detailed information and reviewed the final publication.
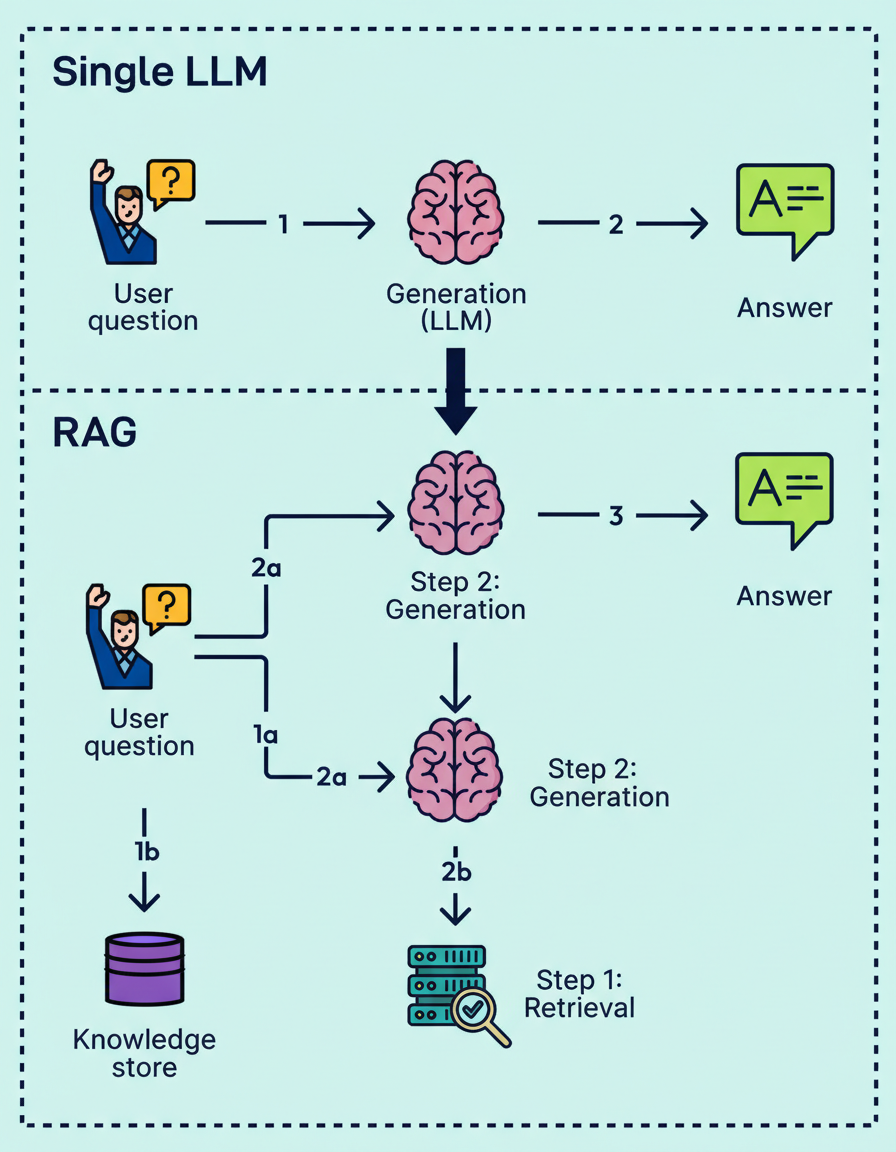
To deliver answers that are both accurate and cited, reliance solely on an LLM’s internal knowledge is insufficient. Instead, Retrieval-Augmented Generation (RAG) is employed.
RAG separates the problem into two distinct phases: retrieval and generation. This is supported by an offline indexing pipeline responsible for preparing the knowledge store.
The implementation of a RAG system commences with an indexing pipeline, which constructs a knowledge store from raw data in an offline process. Upon receiving a user query, the retrieval system scans this store using both lexical search for keywords and semantic search for intent to pinpoint the most relevant snippets. Subsequently, the generation phase supplies these snippets to the LLM with explicit instructions to formulate an answer strictly based on the provided evidence and to cite specific sources.
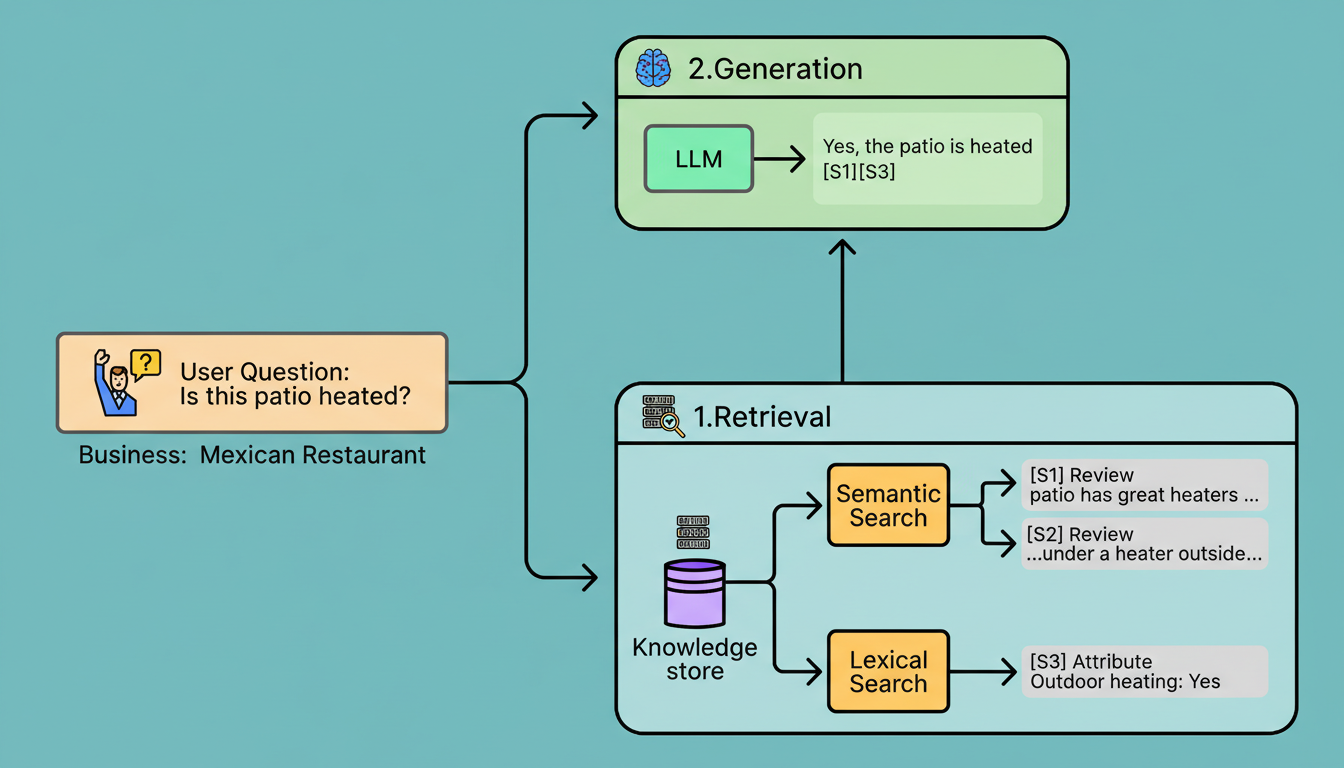
Citations are typically generated by having the model produce citation markers that correspond to specific snippets. For instance, if the prompt incorporates snippets identified as S1, S2, and S3, the model might produce “Yes, the patio is heated” and append markers such as [S1] and [S3]. A subsequent citation resolution step then maps these markers back to their original sources, such as a particular review excerpt, photo caption, or attribute field, before formatting them for the user interface. Finally, citations undergo verification to confirm that every emitted citation corresponds to authentic, retrievable content.
While this system architecture suffices for a prototype, a production system mandates additional layers to ensure reliability, safety, and optimal performance. The subsequent sections of this article utilize the Yelp Assistant as a case study to investigate the practical engineering challenges inherent in building such a system at scale and the strategies implemented to address them.
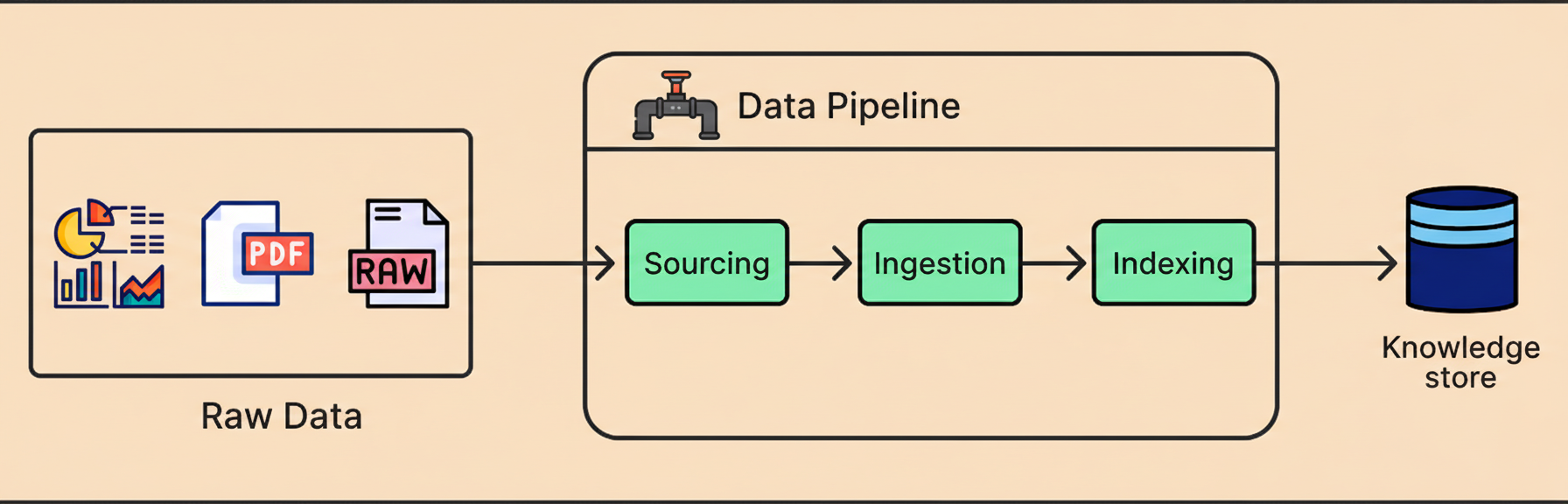
A robust data strategy dictates the content an assistant can retrieve and its update velocity. The typical pipeline encompasses three stages: data sourcing, where essential inputs like reviews or business hours are chosen and update contracts are defined; ingestion, which cleanses and transforms raw data feeds into a reliable canonical format; and finally, indexing, which converts these records into retrieval-optimized documents using keyword or vector search signals to allow the system to narrow down to the correct business scope.
Establishing a data pipeline for a demonstration is generally straightforward. For instance, Yelp’s initial prototype leveraged ad hoc batch dumps loaded into a Redis snapshot, effectively treating each business as a static content bundle.
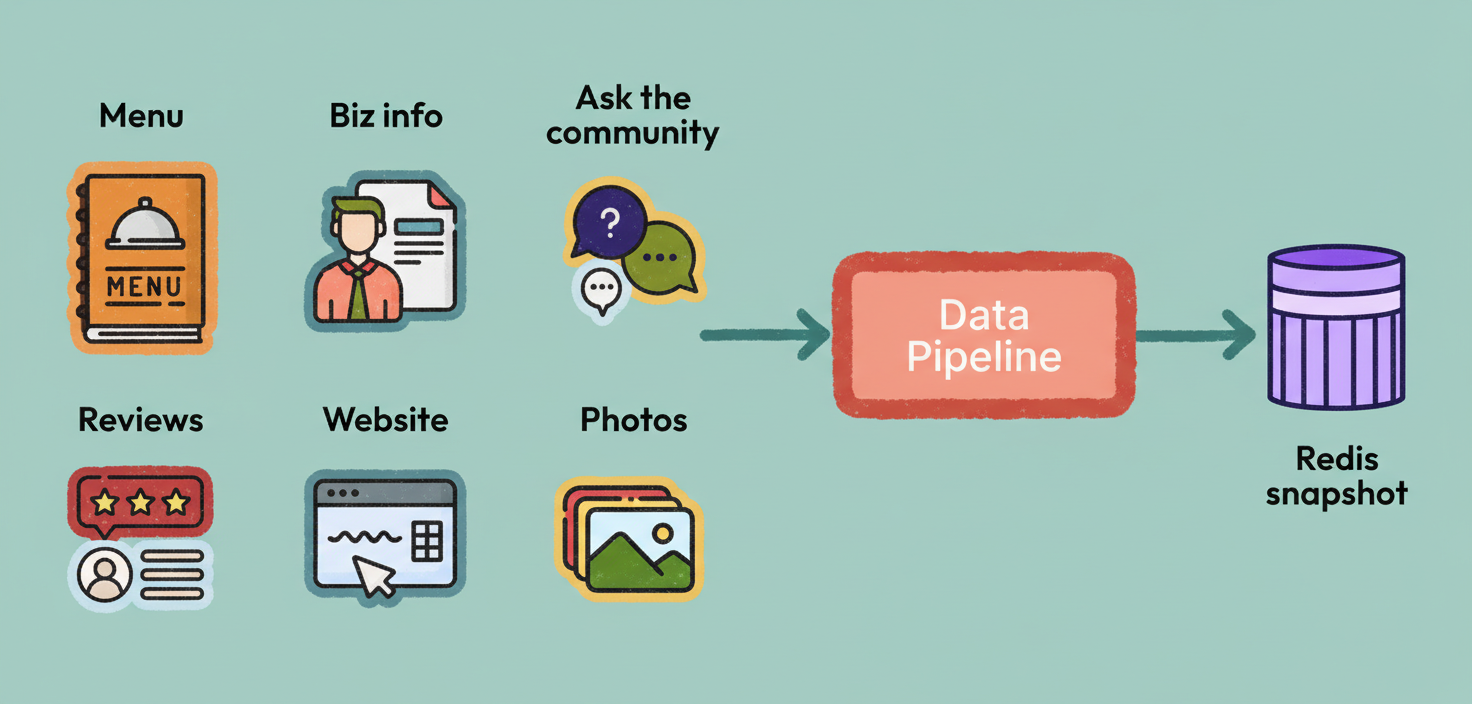
However, in a production environment, this method becomes unfeasible due to continuous content changes and an ever-expanding corpus. A dated answer concerning operating hours is more detrimental than no answer, and a singular generic index struggles to pinpoint specific, critical facts as data volume escalates. To address the requirements of high query volume and near real-time freshness, Yelp refined its data strategy through four significant architectural transformations.
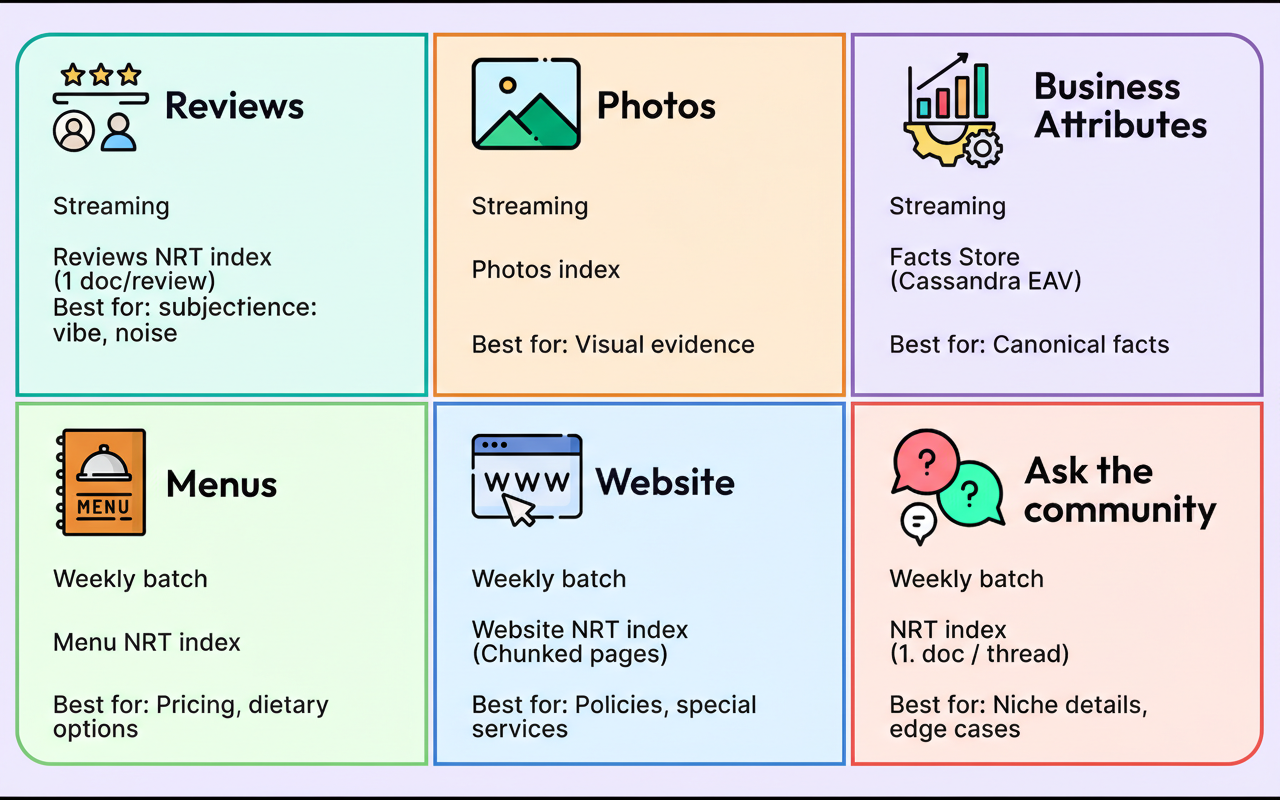
Processing every data source in real-time incurs high operational costs for ingestion, whereas treating all data as a weekly batch leads to outdated answers. Yelp established precise freshness targets contingent on the content type. The platform implemented streaming ingestion for high-velocity data, such as reviews and business attributes, guaranteeing updates within 10 minutes. Conversely, a weekly batch pipeline was employed for slower-moving sources, including menus and website text. This hybrid methodology ensures that a user inquiring “Is it open?” receives the most current status without expending resources on streaming static content.
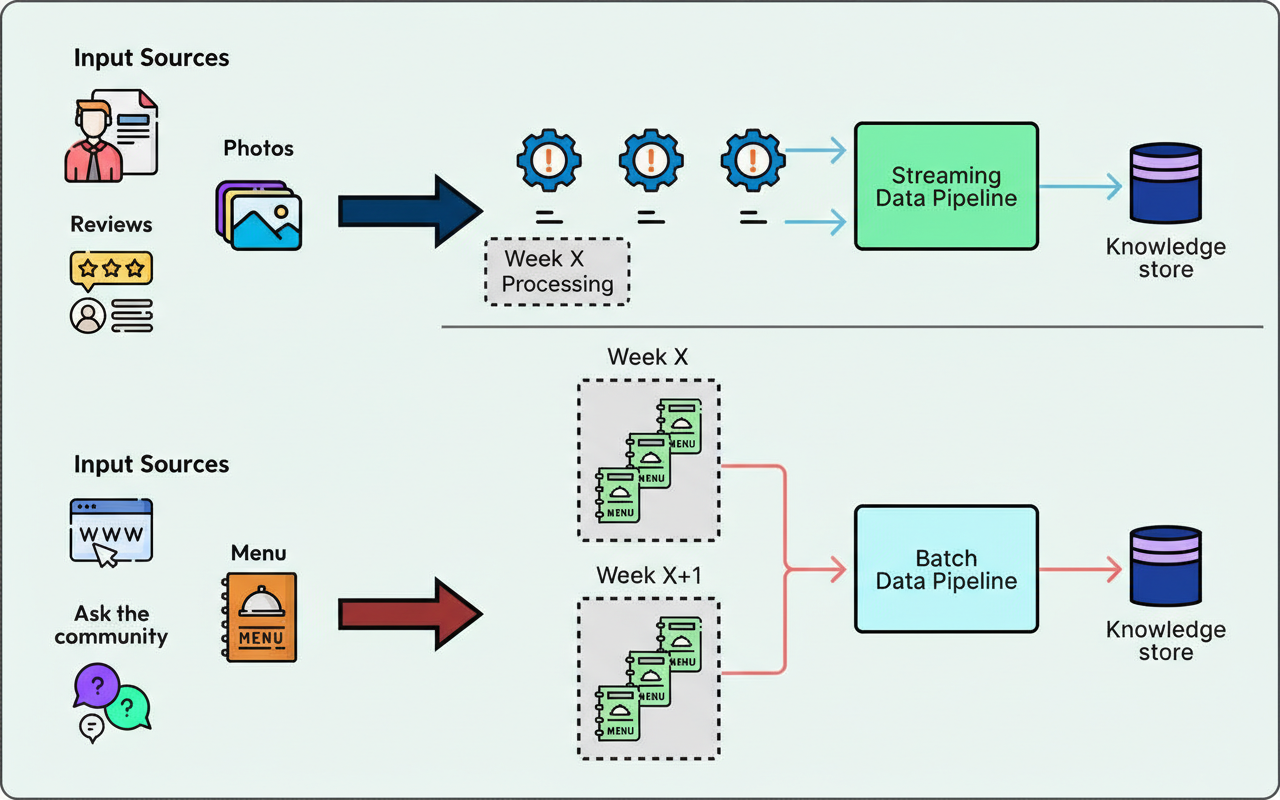
Not all queries necessitate an identical answering approach. Some demand searching through unstructured, often noisy text, while others require a singular, precise factual response. Treating all information as generic text compromises retrieval reliability, potentially allowing anecdotal details from reviews to supersede authoritative fields like operating hours.
Yelp replaced the monolithic prototype Redis snapshot with two distinct production-grade data stores. Unstructured content, including reviews and photos, is served via search indices to optimize relevance. Conversely, structured facts, such as amenities and business hours, reside within a Cassandra database, utilizing an Entity-Attribute-Value schema.
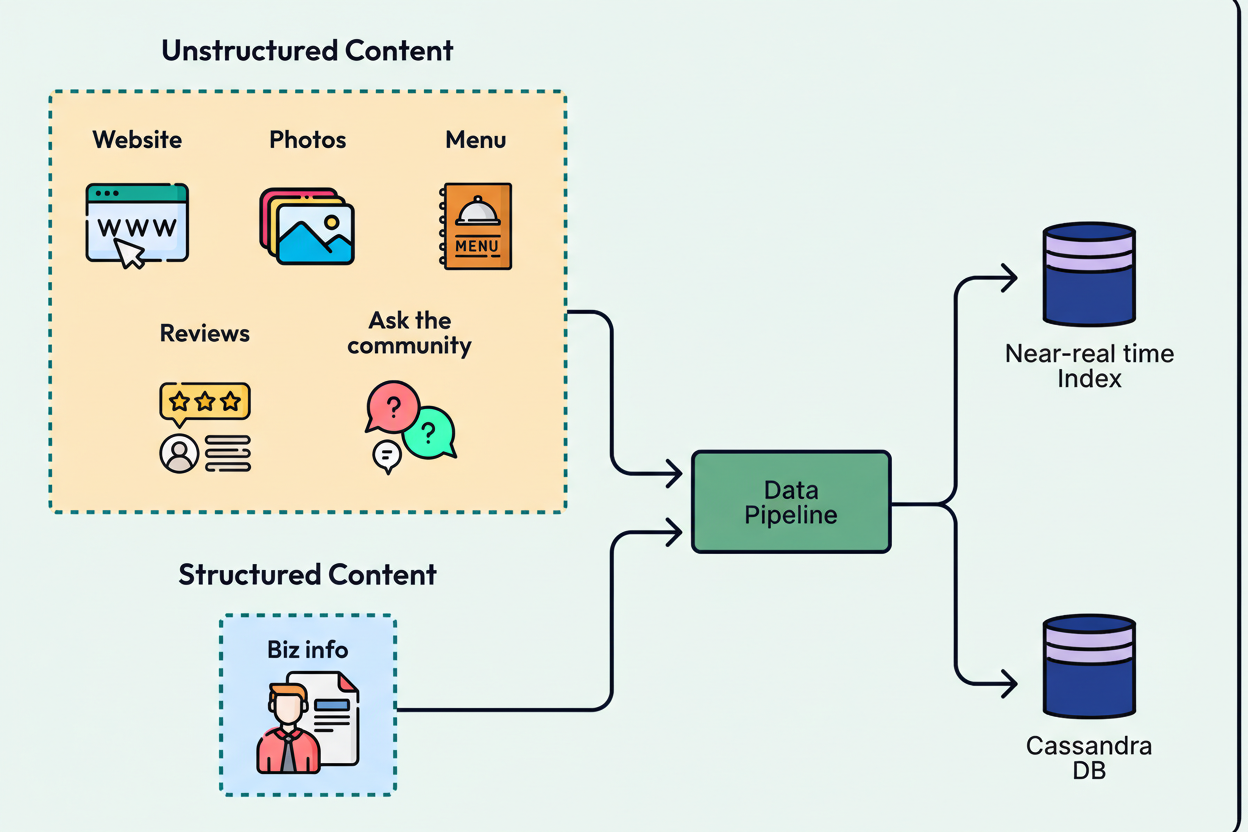
This architectural separation mitigates the generation of fabricated facts and substantially simplifies schema evolution. Engineers are thus able to incorporate new attributes, such as EV charging availability, without the necessity of executing database migrations.
Photo retrieval can be accomplished exclusively through captions, solely via image embeddings, or through a synergistic combination of both methods. Retrieval based solely on captions becomes ineffective when captions are absent, excessively brief, or phrased divergently from the user’s query. Conversely, embedding-only retrieval may overlook literal constraints, such as exact menu item names or specific terminology a user anticipates matching.
Yelp addressed this disparity by deploying a hybrid retrieval mechanism. The system ranks photographs using both textual matches from captions and similarity derived from image embeddings. Consequently, if a user inquires about a heated patio, the system can effectively retrieve pertinent visual evidence, irrespective of whether the concept is explicitly stated as “heaters” in the caption or merely discernable as a heat lamp within the image itself.
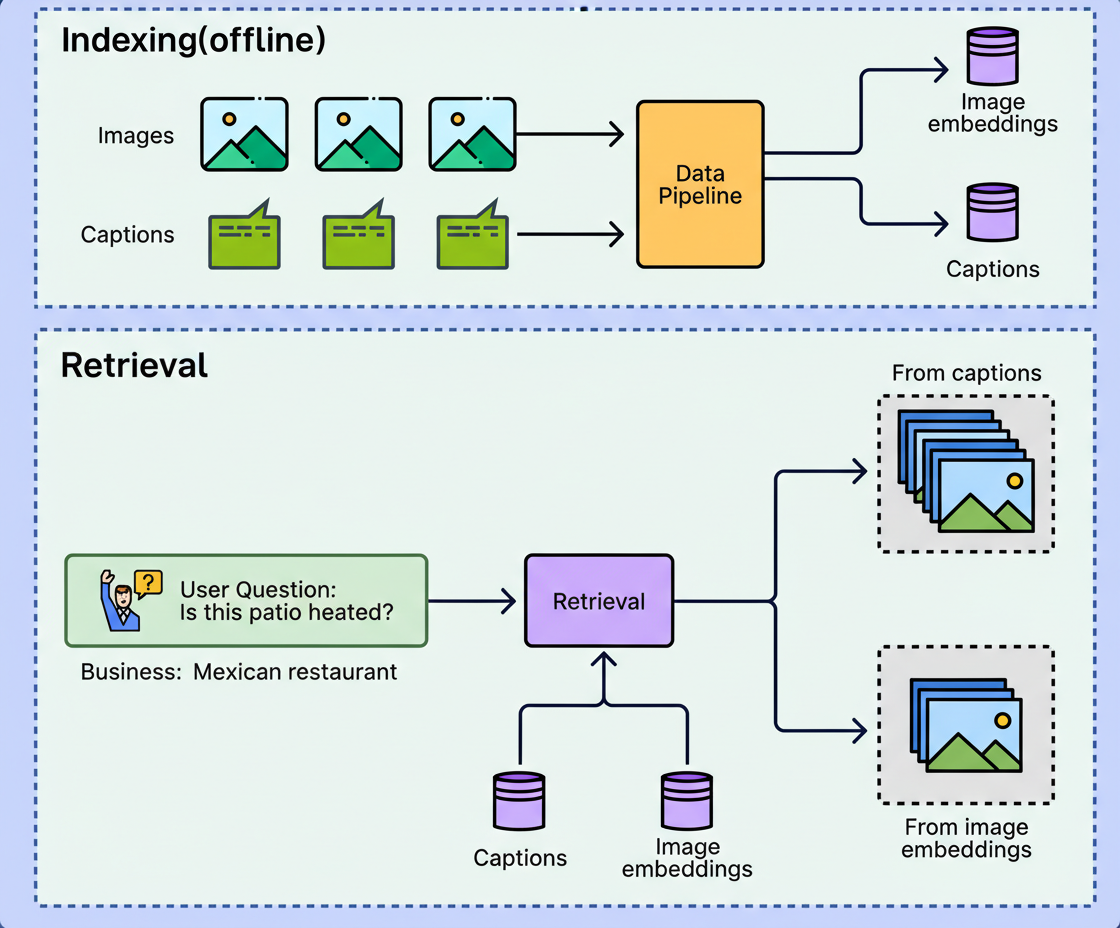
While distributing data across various search indices and databases enhances data quality, it can adversely impact latency. A singular answer might necessitate multiple operations: a read for operating hours, a query for reviews, and an additional query for photos. These distinct network calls accumulate, compelling the assistant’s logic to manage intricate data retrieval processes.
Yelp resolved this challenge by implementing a Content Fetching API positioned in front of all retrieval stores. This abstraction layer manages the complexities of parallelizing backend read operations and enforcing strict latency budgets. The outcome is a standardized response format that maintains the 95th percentile latency below 100 milliseconds, thereby decoupling the assistant’s core logic from the intricacies of the underlying storage mechanisms. The subsequent illustration provides a summary of the data sources and their respective specialized handling.
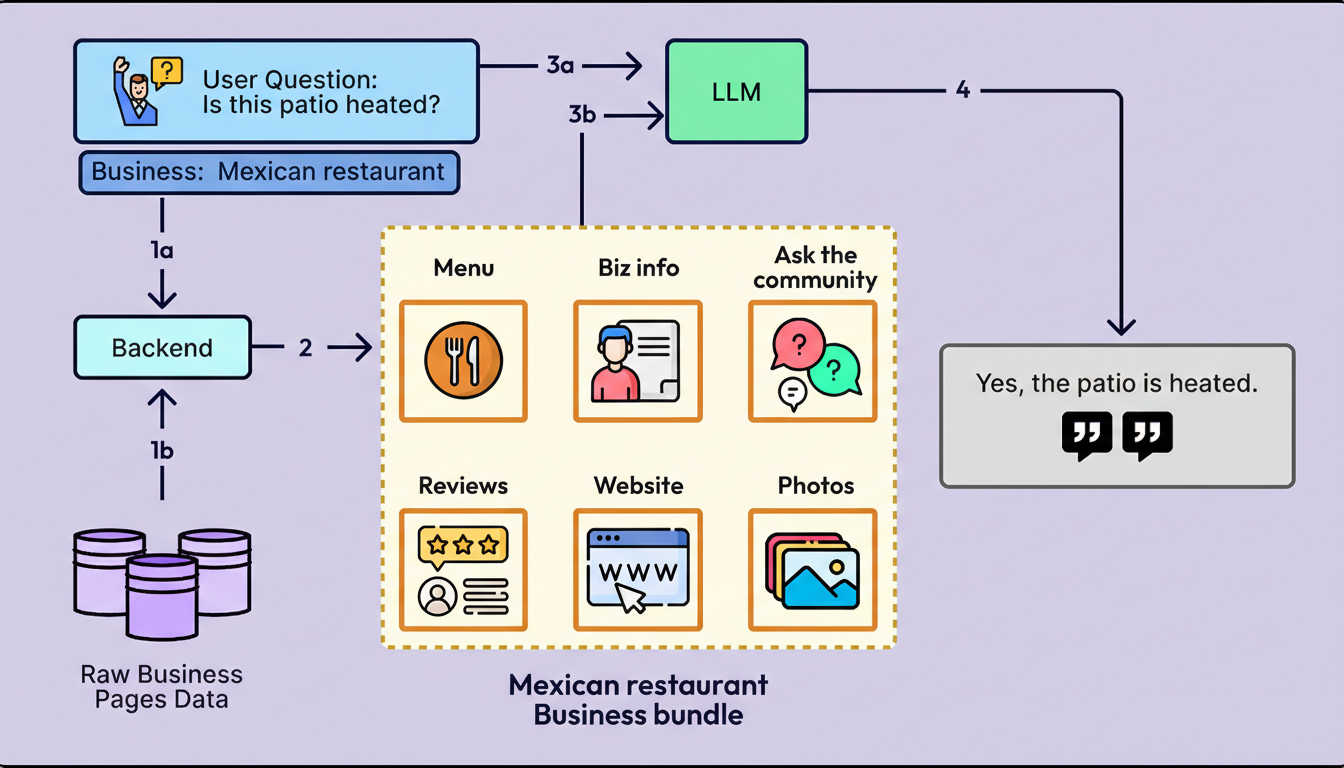
Prototypes frequently prioritize simplicity by depending on a singular, large model for all functionalities. The backend typically injects all available content, such as menus and reviews, into one extensive prompt, compelling the model to operate as a slow and costly retrieval engine. Yelp adopted this approach in its initial demonstrations. If a user inquired, “Is the patio heated?”, the model was required to process the entire business content bundle to locate any mention of heaters.
While this method proves viable for a demonstration, it becomes unsustainable under actual traffic loads. Excessive context leads to less pertinent answers and increased latency, while the absence of robust guardrails leaves the system susceptible to adversarial attacks and irrelevant queries, thereby consuming expensive computational resources unnecessarily.
To transition from a fragile prototype to a resilient production system, Yelp modularized the monolithic LLM into several specialized models. This strategic decomposition aimed to bolster system safety and enhance retrieval accuracy.
<0>
Yelp delineated the processes of “evidence discovery” and “answer formulation.” Rather than transmitting the complete business content bundle to the model, the system queries near real-time indices to retrieve only the pertinent snippets. For an inquiry such as “Is the patio heated?”, the system fetches specific reviews that mention “heaters” along with the outdoor seating attribute. The LLM subsequently generates a concise response based exclusively on this evidence, providing citations to its sources.
<1>
Retrieval by itself is insufficient if every source is searched indiscriminately. Querying menus for questions concerning “ambiance” or examining reviews for “opening hours” introduces irrelevant noise that can confound the model.
Yelp addressed this issue by implementing a specialized selector. A Content Source Selector analyzes the user’s intent and directs the query to only the relevant data stores. This mechanism allows the system to route inputs like “What are the hours?” to structured factual data and “What is the vibe?” to reviews.
<2>
This routing also functions as a conflict resolution mechanism when data sources provide conflicting information. Yelp determined that it is most effective to default to authoritative sources, such as business attributes or website information, for objective facts, while deferring to reviews for subjective, experience-based inquiries.
Users infrequently employ search-optimized keywords. They often pose incomplete questions, such as “vibe?” or “good for kids?”, which are ineffective against exact-match indices.
Yelp implemented a Keyword Generator, which is a fine-tuned GPT-4.1-nano model. This model translates user queries into precise search terms. For instance, the query “vegan options” might generate keywords such as “plant-based” or “dairy-free”. When a user’s prompt is broad, the Keyword Generator is specifically trained to produce no keywords, thereby preventing the generation of potentially misleading terms.
<3>
Prior to any retrieval operation, the system must ascertain whether a response should be provided. Yelp employs two classifiers: Trust & Safety, designed to obstruct adversarial inputs, and Inquiry Type, which redirects out-of-scope questions such as “Change my password” to appropriate support channels.
<4>
Constructing this pipeline necessitated a modification in the training methodology. While prompt engineering a singular large model is effective for prototypes, it proved excessively fragile for production traffic where user phrasing exhibits significant variability. Yelp implemented a hybrid strategy:
<5>
Prototypes typically manage each request as a singular synchronous blocking call. The system retrieves content, constructs a prompt, awaits complete model generation, and subsequently returns a single response payload. While this workflow is straightforward, it is generally not optimized for either latency or cost, leading to slow and expensive operations at scale.
<6>
Yelp implemented serving optimizations to decrease latency from over 10 seconds in prototype stages to under 3 seconds in production. Key techniques employed include:
Collectively, these techniques facilitated Yelp in constructing a faster and more responsive system. At the p50 percentile, the latency breakdown is observed as:
<7>
Within a prototype environment, evaluation is typically informal; developers test a limited set of questions and iteratively adjust prompts until the output appears satisfactory. This methodology is inherently fragile, as it only assesses anticipated scenarios and frequently overlooks the diverse and ambiguous phrasing employed by actual users. In a production setting, failures manifest as confidently asserted hallucinations or technically accurate but ultimately unhelpful responses. Yelp directly observed this issue when the early prototype’s conversational tone fluctuated unpredictably between excessively formal and casual based on minor alterations in wording.
<8>
An effective evaluation system must disaggregate quality into distinct, independently scoreable dimensions. Yelp established six primary dimensions for this purpose. The organization employs an LLM-as-a-judge system, wherein a specialized grader assesses a single dimension against a rigorous rubric. For instance, the Correctness grader scrutinizes the answer in comparison to retrieved snippets and assigns labels such as “Correct” or “Unverifiable”.
A crucial insight gained by Yelp is the inherent difficulty in reliably automating the evaluation of subjective dimensions, such as Tone and Style. While objective metrics like Correctness are readily judged against factual evidence, tone represents an evolving implicit agreement between the brand and its users. Rather than prematurely implementing an unreliable automated judge, Yelp addressed this by collaboratively defining principles with its marketing team and enforcing these principles through carefully selected few-shot examples embedded within the prompt.
Most development teams can successfully create a grounded assistant for demonstration purposes. The more arduous task lies in engineering a system that maintains freshness, speed, safety, and efficiency under actual user traffic. The following points summarize the pivotal lessons derived from the journey to a production-ready system.
The Yelp Assistant deployed on business pages is architected as a multi-stage, evidence-grounded system, diverging from the design of a monolithic chatbot. The principal insight derived from this development is that the chasm between a functional prototype and a production-ready assistant is considerable. Bridging this gap necessitates more than merely a powerful underlying model; it demands a comprehensive engineering system capable of ensuring data freshness, maintaining grounded answers, and guaranteeing safe operational behavior.
For future enhancements, Yelp is concentrating on robust context retention within extended multi-turn conversations, facilitating improved business-to-business comparisons, and leveraging visual language models more profoundly to directly interpret and reason over photographic content.