
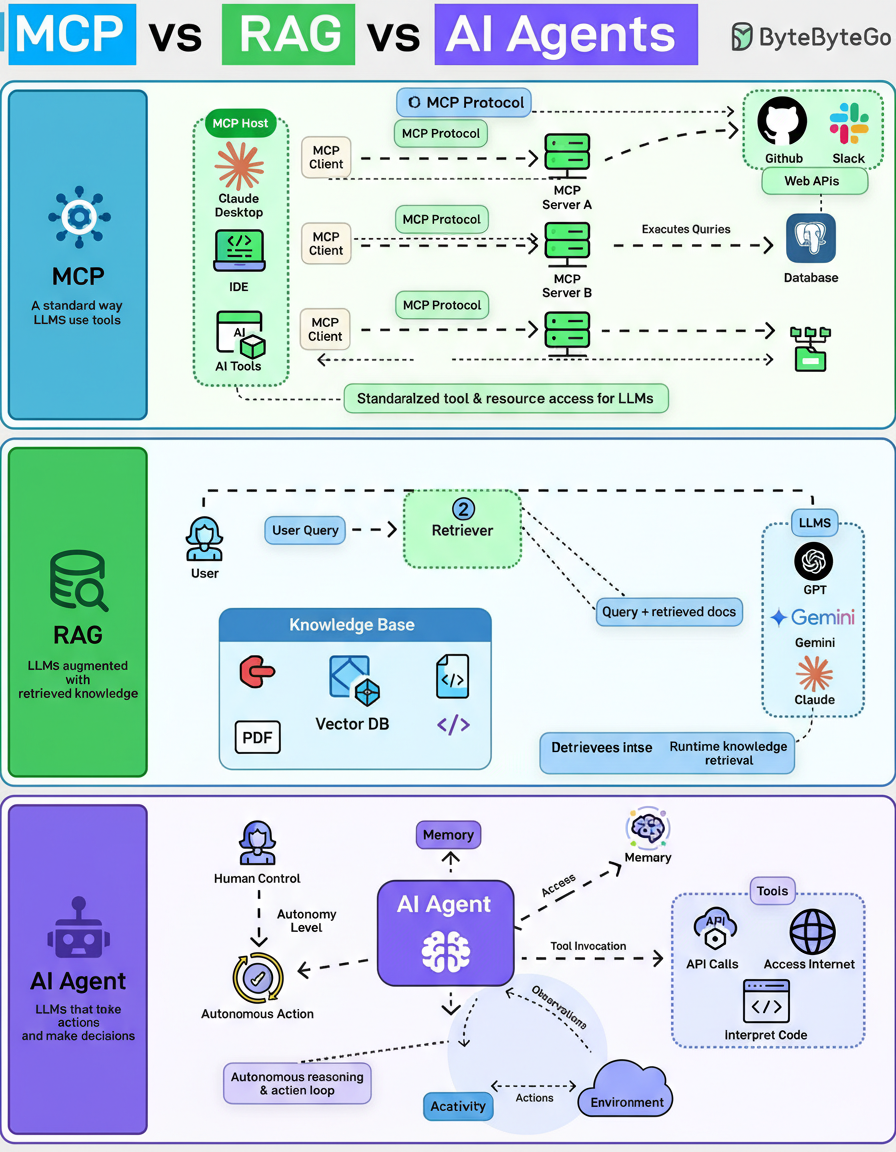
Discussions around Model Context Protocol (MCP), Retrieval-Augmented Generation (RAG), and AI Agents are prevalent. Often, these concepts are mistakenly conflated. However, they do not represent competing ideas; instead, they address distinct challenges at various levels of the technical stack.
The Model Context Protocol (MCP) defines the mechanism through which Large Language Models (LLMs) interact with tools. It functions as a standardized interface facilitating communication between an LLM and external systems, such as databases, file systems, GitHub, Slack, and internal APIs.
Rather than requiring each application to develop custom integration code, MCP establishes a consistent methodology for models to identify and invoke tools, subsequently receiving structured outputs. MCP’s role is not to dictate actions but to standardize the exposure of these tools.
Retrieval-Augmented Generation (RAG) concerns the information accessible to a model during runtime. The base model remains static, without requiring retraining. Upon a user’s query, a retriever component retrieves pertinent documents—such as PDFs, code snippets, or data from vector databases—and injects this information directly into the prompt.
RAG proves highly effective for:
However, RAG does not initiate actions; its primary function is to enhance the quality of generated answers.
AI Agents are designed to perform actions. An agent operates through a cycle of observation, reasoning, decision-making, action, and repetition. Capabilities include invoking tools, generating code, browsing the internet, managing memory, delegating assignments, and functioning with varying degrees of autonomy.
GPT-5 represents not a singular model but a unified system comprising multiple models, integrated safeguards, and a real-time router. The information presented herein, along with the accompanying diagram, is derived from current understandings of the GPT-5 system card. When a query is submitted, the chosen mode dictates which model is utilized and the extent of processing performed by the system.
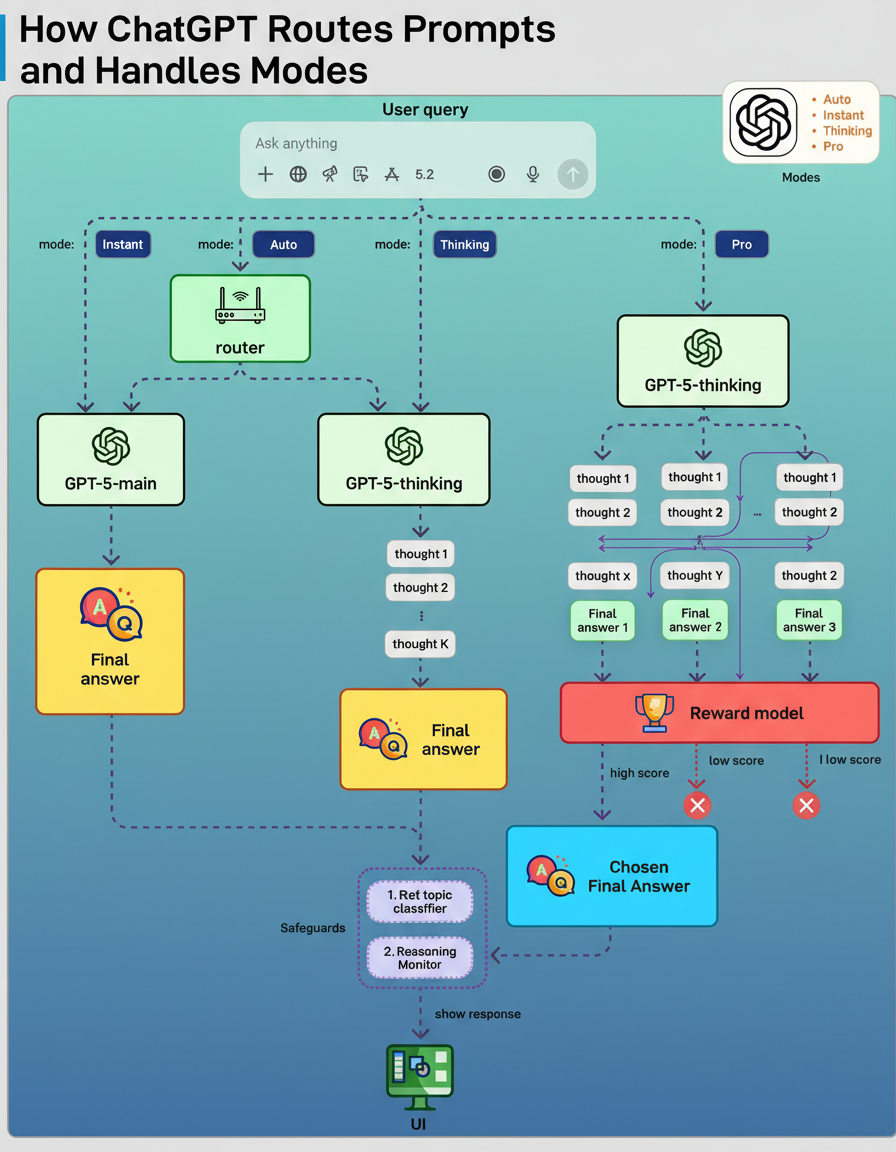
Instant mode directs the query immediately to GPT-5-main, a rapid, non-reasoning model. This mode prioritizes low latency and is applied to straightforward or low-risk tasks, such as generating brief explanations or performing text rewrites.
Thinking mode employs GPT-5-thinking, a reasoning model that executes several internal processing steps prior to formulating the final response. This approach enhances accuracy for intricate tasks, including mathematical computations or strategic planning.
Auto mode incorporates a real-time router. A lightweight classifier analyzes the query to determine whether to utilize GPT-5-main or GPT-5-thinking, particularly when more profound reasoning capabilities are required.
Pro mode operates without a distinct model. Instead, it leverages GPT-5-thinking but performs multiple reasoning attempts and selects the optimal output by employing a reward model.
Throughout all operational modes, safeguards function concurrently at different stages. A rapid topic classifier assesses whether the subject matter carries a high risk, succeeded by a reasoning monitor that enforces more rigorous evaluations to prevent the generation of unsafe responses.
The necessity for Agent Skills stems from the observation that extensive prompts can degrade agent performance. Rather than relying on a single, voluminous prompt, agents maintain a curated catalog of skills, which are essentially reusable playbooks containing precise instructions, loaded into context solely when required.
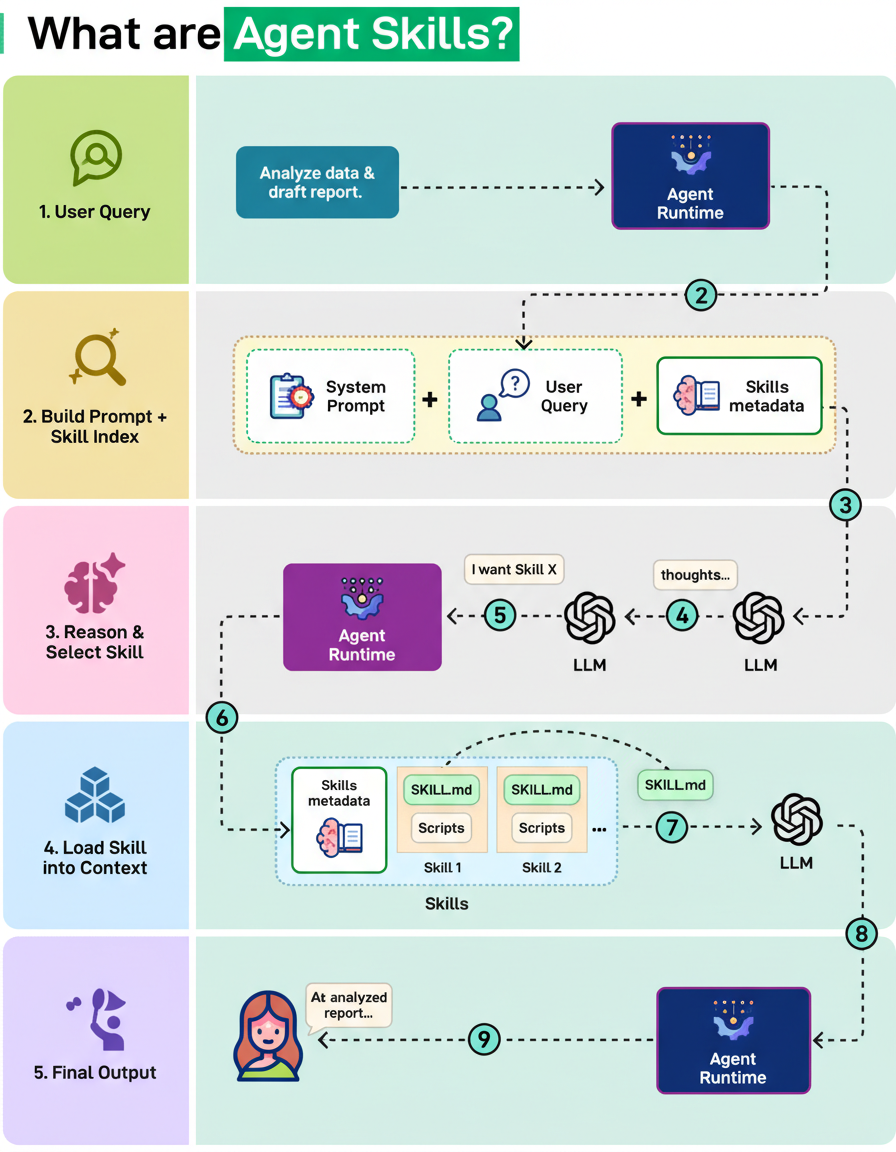
The workflow for Agent Skills typically involves the following steps:
The dynamic loading of skills, only as they become necessary, ensures that Agent Skills maintain a compact context size and contribute to consistent LLM behavior.

The deployment or upgrading of services inherently involves risks. This discussion explores various strategies for risk mitigation, with the accompanying diagram illustrating common approaches.
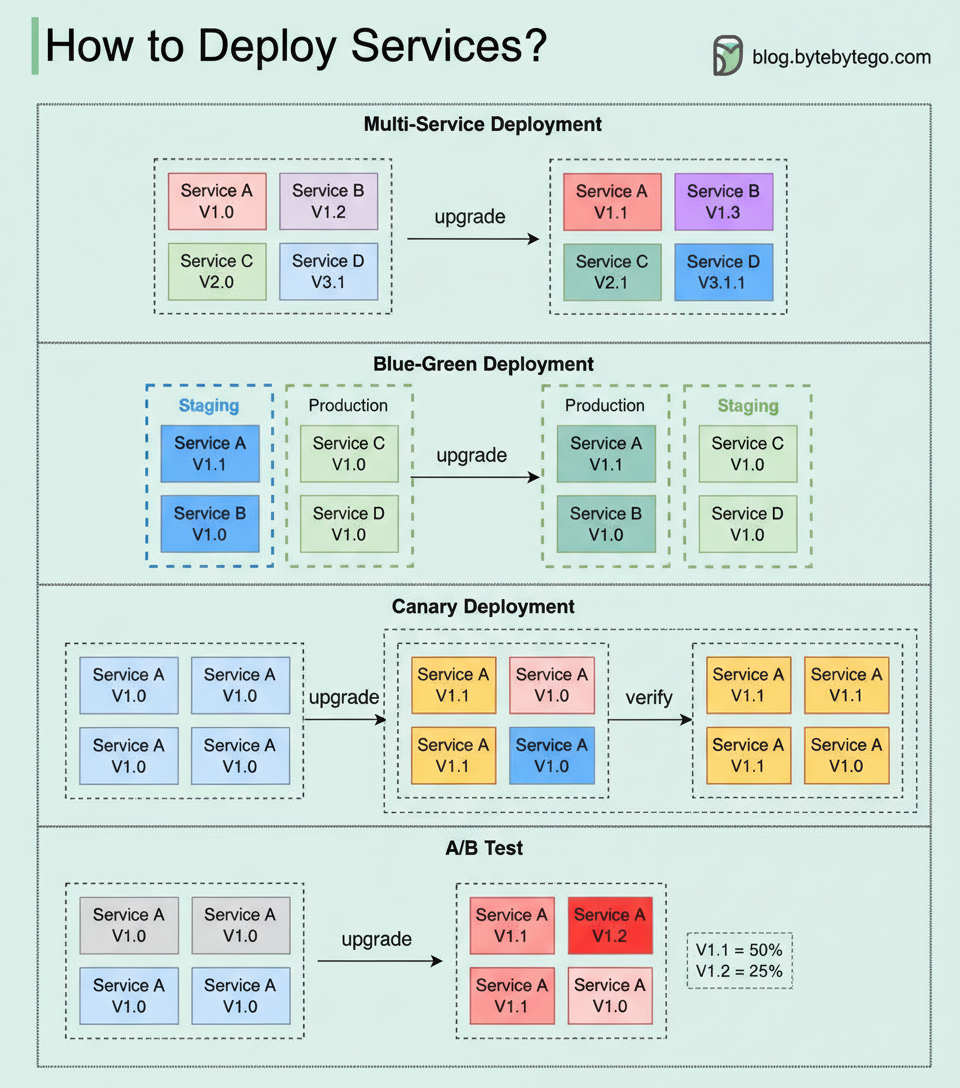
Multi-Service Deployment: In this model, new changes are deployed to multiple services concurrently. While this approach offers ease of implementation, the simultaneous upgrade of all services complicates dependency management and testing. Furthermore, safe rollbacks can be challenging.
Blue-Green Deployment: This strategy involves maintaining two identical environments: a staging environment (blue) and a production environment (green). The blue environment typically runs a version ahead of the green. After testing is completed in the staging environment, user traffic is re-routed to it, effectively promoting the blue environment to production. While this deployment strategy simplifies rollbacks, the overhead of maintaining two production-quality environments can be costly.
Canary Deployment: A canary deployment facilitates the gradual upgrade of services, rolling out changes to a subset of users incrementally. This method is generally more cost-effective than blue-green deployment and allows for straightforward rollbacks. However, the absence of a dedicated staging environment necessitates testing directly in production. This process introduces complexity, requiring careful monitoring of the canary version while progressively shifting more user traffic away from the older version.
A/B Test: During an A/B test, distinct versions of services operate concurrently within the production environment. Each version conducts an “experiment” for a specific subset of users. A/B testing offers an economical approach for evaluating new features in production. However, meticulous control over the deployment process is essential to prevent unintended exposure of features to users.