

When requesting a ride on Lyft, a multitude of machine learning models activate behind the scenes. One model calculates the trip price, another allocates driver incentives, a fraud detection model scrutinizes the transaction for anomalies, and an ETA prediction model estimates arrival time. This entire process executes within milliseconds and happens millions of times daily.
The challenge of serving machine learning models at such scale is substantial. Lyft addressed this challenge by developing a platform called LyftLearn Serving, designed to simplify these tasks for developers. This article examines the platform’s architecture and design.
Lyft identified two primary planes of complexity in machine learning model serving. The first, the data plane, involves operations during steady-state processing when the system actively handles requests. This includes network traffic, CPU, memory utilization, model loading, and inference execution speed. These runtime concerns determine whether the system can support production loads.
The second plane is the control plane, which manages change over time. This encompasses deploying and undeploying models, retraining on fresh data, maintaining versioning, conducting experiments for new model testing, and ensuring backward compatibility to prevent breaking existing functionality.
Lyft needed to excel simultaneously in managing both planes while supporting a diverse array of requirements across multiple teams.
The wide diversity of requirements at Lyft made developing a one-size-fits-all solution impractical. Different teams prioritized vastly different system characteristics, creating a complex operating environment.
Some teams demanded extremely low latency, with predictions delivered within single-digit milliseconds to maintain user experience quality. Others required high throughput capable of processing over a million requests per second during peak periods. Additional teams preferred specialized machine learning libraries that lacked broad support, while some needed continual learning capabilities to update models in real-time based on new input.
See the diagram below:
Source: Lyft Engineering Blog
Complicating matters further, Lyft operated a legacy monolithic serving system. Although functional for some uses, its monolithic design presented challenges. All teams shared one codebase, necessitating consensus on library versions. A deployment by one team could inadvertently disrupt others. During incidents, identifying the team responsible for a specific system component was often unclear, leading to deployment bottlenecks.
Lyft opted to build LyftLearn Serving leveraging a microservices architecture, wherein small, independent services are responsible for specific functions. This approach aligned with the firm’s broader software development practices and enabled utilizing existing testing, networking, and operational tools.
See the diagram below:
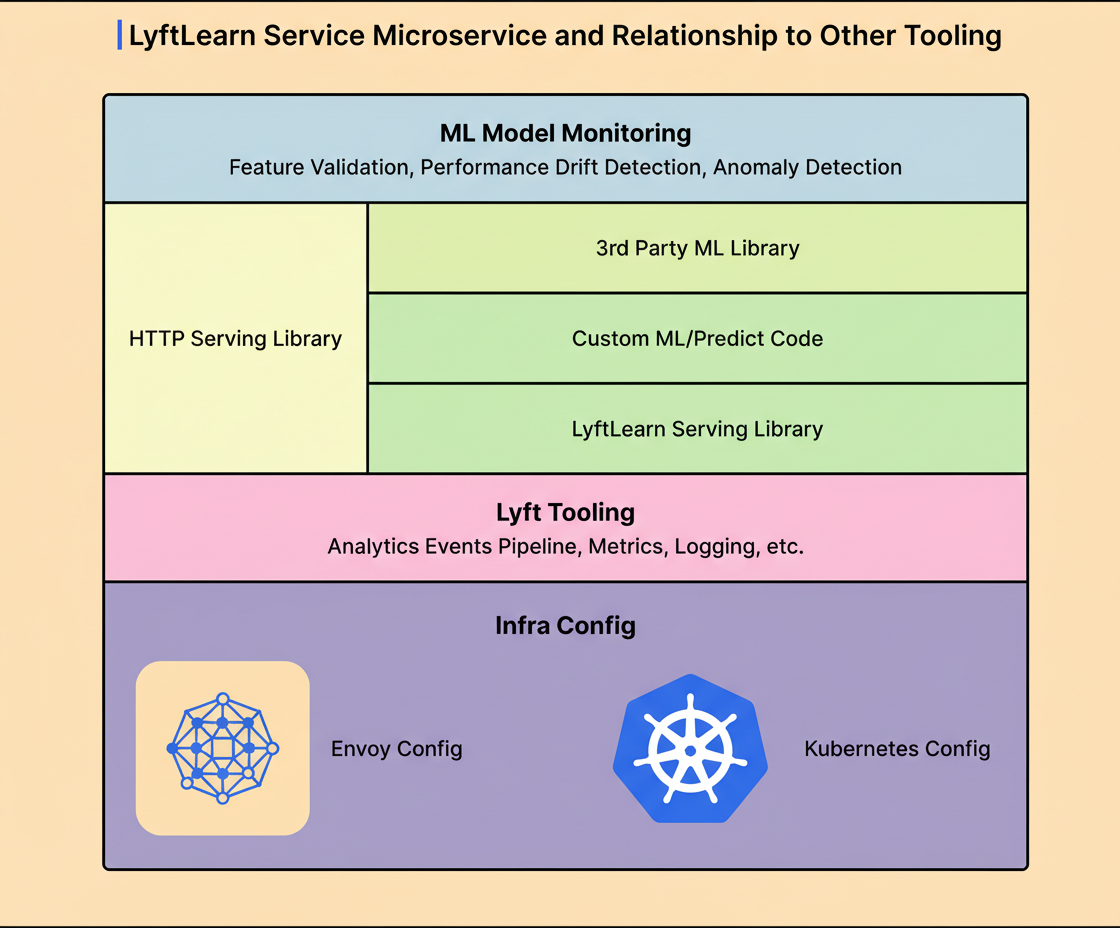
However, Lyft advanced beyond typical microservices use by generating fully independent microservices for each team rather than one shared service. When a team intends to serve machine learning models, a configuration generator creates a unique GitHub repository containing all necessary code and configuration for that team’s dedicated microservice. For instance, the Pricing and Fraud Detection teams each manage separate repositories and services.
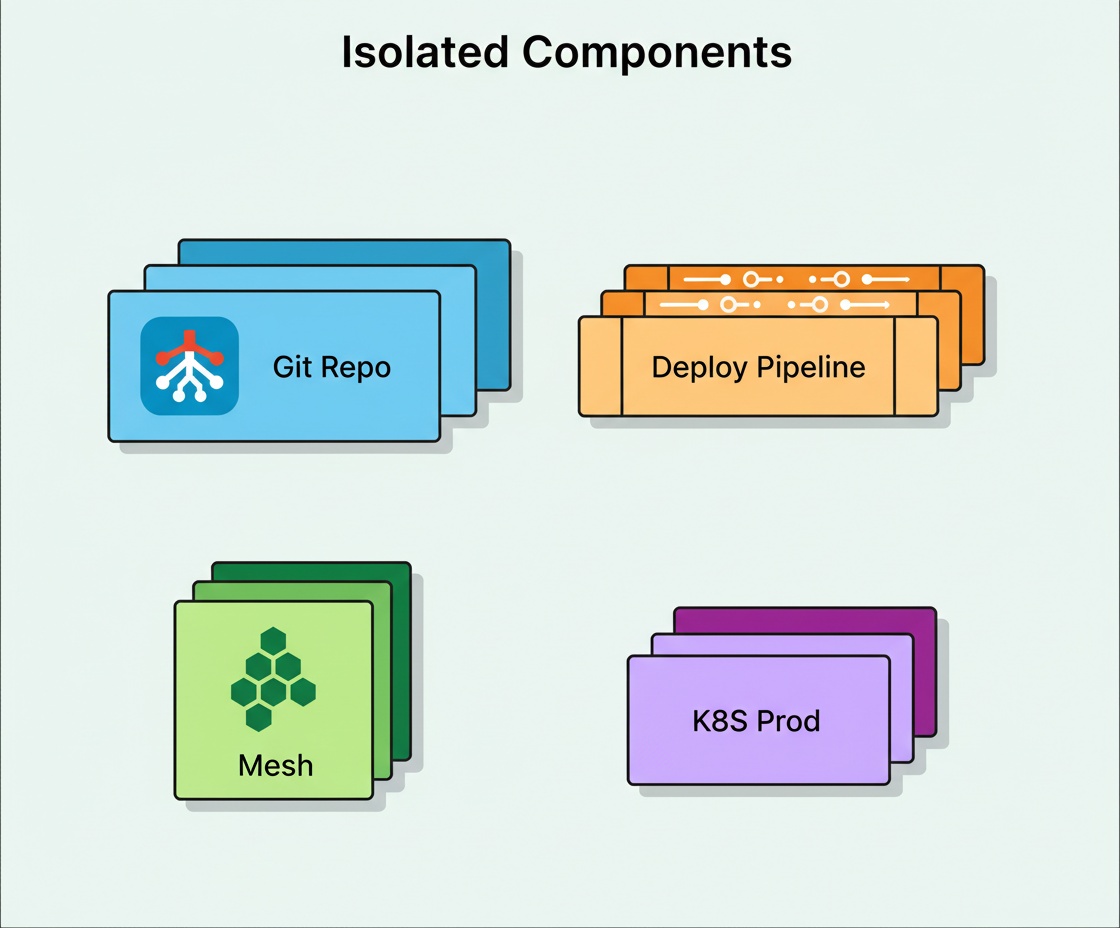
Although underlying components are shared, these microservices operate autonomously. Each team manages its deployment pipeline independently, selecting deployment timing, and utilizing specific versions of ML libraries like TensorFlow, PyTorch, or others as needed—avoiding conflicts. Services run in isolated containers with dedicated CPU and memory allocations, preventing cascading failures.
This approach resolved legacy system ownership conflicts by ensuring each microservice repository clearly identifies team ownership. On-call escalation paths became distinct, library updates affected individual teams only, and deployment efforts were decoupled.
See the diagram below:
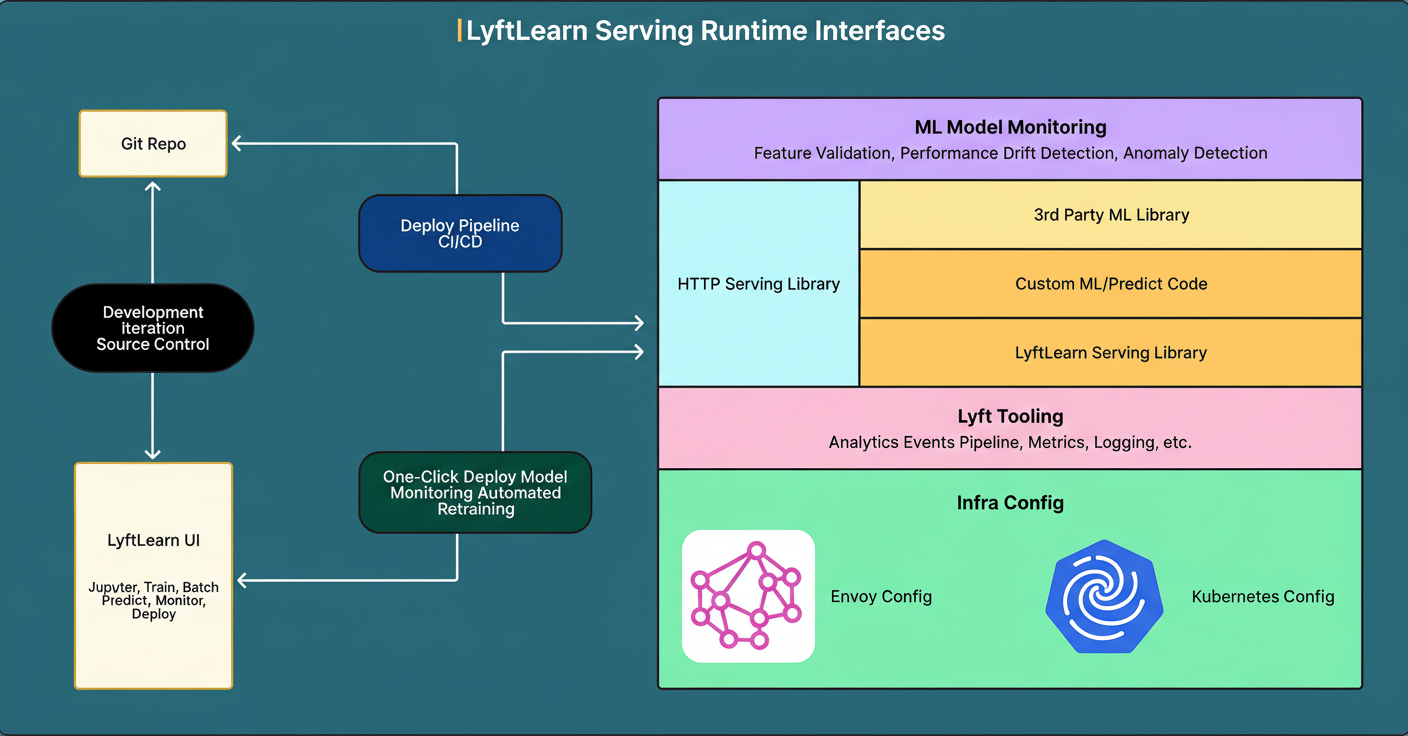
Examining the runtime components of a LyftLearn Serving microservice reveals a layered architecture. The outer layer handles HTTP serving using Flask, a Python web framework, running atop Gunicorn to manage multiple worker processes for concurrency. Envoy load balancer distributes incoming requests across instances. Custom optimizations improve Flask’s integration with Envoy and Gunicorn.
Below this is the Core LyftLearn Serving Library, which encapsulates the platform’s business logic. Responsibilities include model loading and unloading, version management, inference request processing, shadowing new models alongside production for safe testing, performance monitoring, and prediction logging.
ML engineers inject custom code via two key functions: a load function to deserialize models from disk to memory, and a predict function that preprocesses input features and executes the model prediction.
At the foundation are third-party ML libraries such as TensorFlow, PyTorch, LightGBM, and XGBoost, all supported provided they expose Python interfaces, affording diverse team preferences.
The entire stack operates on Lyft’s infrastructure, leveraging Kubernetes for container orchestration and Envoy for service mesh networking. The runtime also delivers integrated metrics, logging, tracing, and analytics interfacing with Lyft’s monitoring systems.
Onboarding new teams to LyftLearn Serving requires managing complex configurations spanning Kubernetes YAML, Terraform cloud infrastructure, Envoy networking, database connections, security credentials, monitoring setups, and deployment pipelines.
To lower this barrier, Lyft developed a configuration generator using Yeoman, a scaffolding tool.
See the diagram below:
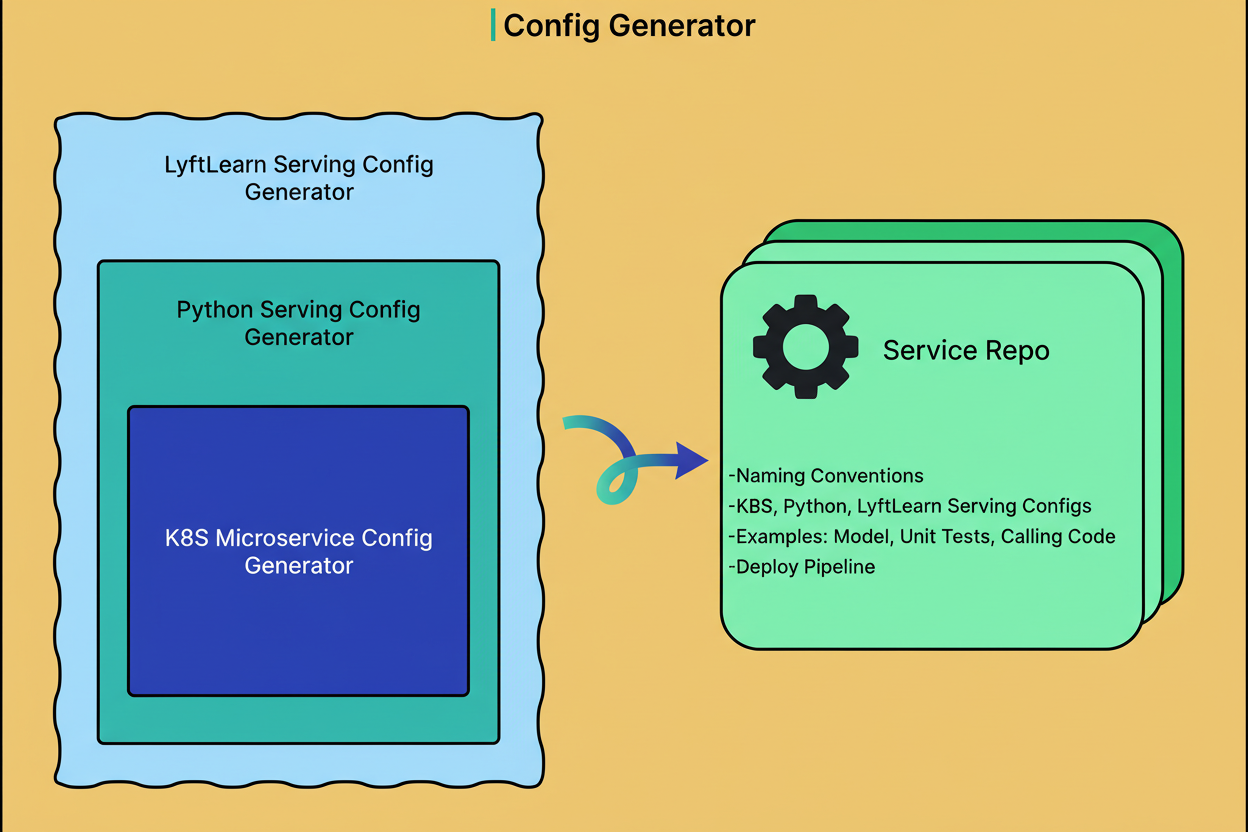
The generator prompts ML engineers with a streamlined question-and-answer workflow covering service name, ownership, and essential details. It then produces a fully formed GitHub repository complete with configuration files, example code for model loading and prediction, unit test templates, a configured CI/CD pipeline, and documentation.
The outputted repository is immediately deployable, enabling teams to self-onboard efficiently. This scalability has facilitated adoption by over 40 teams using LyftLearn Serving.
Lyft implemented model self-tests to ensure ongoing model correctness during platform evolution. Engineers define test data encompassing sample inputs with expected outputs, stored alongside the model binaries.
The system automatically runs these tests when loading models into memory and during pull request validations in continuous integration. This process ensures any compatibility or behavioral regressions are detected early, providing confidence in model reliability without manual checks.
A typical prediction request flow illustrates LyftLearn Serving’s operation. For example, a driver incentive prediction request reaches the /infer endpoint as an HTTP POST containing model ID and JSON-formatted input features.
The Flask server routes the request to the Core LyftLearn Serving Library handler, which retrieves the model from memory and validates input schemas. If configured, requests can be routed simultaneously to multiple model versions for shadow testing.
The custom predict function then processes input features and invokes the relevant ML library for prediction.
Afterwards, platform logic collects latency metrics, logs, and generates analytics events for performance monitoring, returning predictions as JSON responses.
See the diagram below:
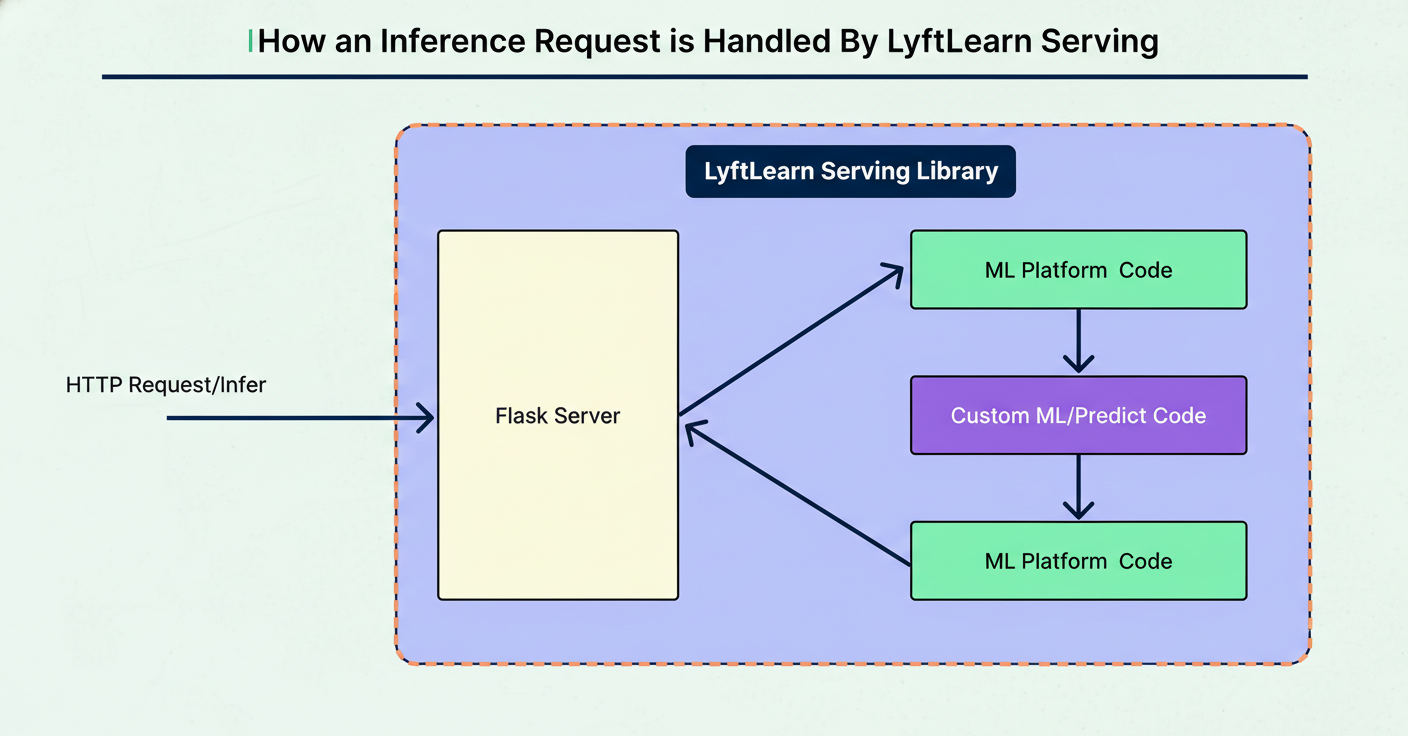
This entire processing flow completes within milliseconds. The separation between platform and custom code enables enhancing platform capabilities independently from team-specific prediction logic.
The Lyft team recognized the need for different user interfaces. Software engineers benefit from full control through code repositories, managing deployment pipelines, CI/CD configurations, and custom inference logic under version control.
Data scientists access LyftLearn UI, a web application providing one-click model deployment, performance dashboards, and training job management without scripting infrastructure.
See the diagram below:
Documentation is structured using the Diátaxis framework, encompassing tutorials for beginners, how-to guides for common tasks, detailed technical references, and conceptual discussions explaining design decisions.
The Lyft engineering team emphasizes several key lessons from developing LyftLearn Serving. Precise definition of terms is critical, given the varied meanings of “model” spanning source code, trained weights, binaries, or in-memory objects.
Models in production serve traffic indefinitely, necessitating extreme stability and rigorous backward compatibility.
Comprehensive documentation enables self-onboarding and reduces platform support efforts.
Trade-offs between user experience and flexibility are unavoidable, requiring constant balancing.
Aligning platform vision with power users’ priorities—stability, performance, and flexibility—yields benefits for all stakeholders.
Adopting proven, stable technologies such as Flask, Kubernetes, and Python offers strong community support, easier hiring, and fewer unexpected issues.
Lyft released LyftLearn Serving internally in March 2022, migrating all models from the legacy monolithic system. Currently, over 40 teams utilize LyftLearn Serving, generating hundreds of millions of predictions daily.