
Prompt engineering involves meticulously designing instructions that direct AI language models toward generating specific, desired outputs. Initially, this discipline may appear uncomplicated; one might assume that merely stating a request to an AI would suffice. However, practitioners quickly learn that formulating truly effective prompts presents a significant challenge.
The apparent simplicity of initiating prompt engineering can often be deceptive. While the act of constructing a prompt is universally accessible, achieving consistently high-quality outcomes necessitates a deeper understanding. This distinction parallels the difference between merely conveying information and communicating with precision and impact. The foundational concepts are readily graspable, yet genuine proficiency demands consistent practice, iterative experimentation, and a thorough comprehension of how these models interpret and process information.
This article delves into the foundational techniques and established best practices for prompt engineering. It will explore diverse prompting methodologies, ranging from straightforward zero-shot instructions to sophisticated chain-of-thought reasoning.
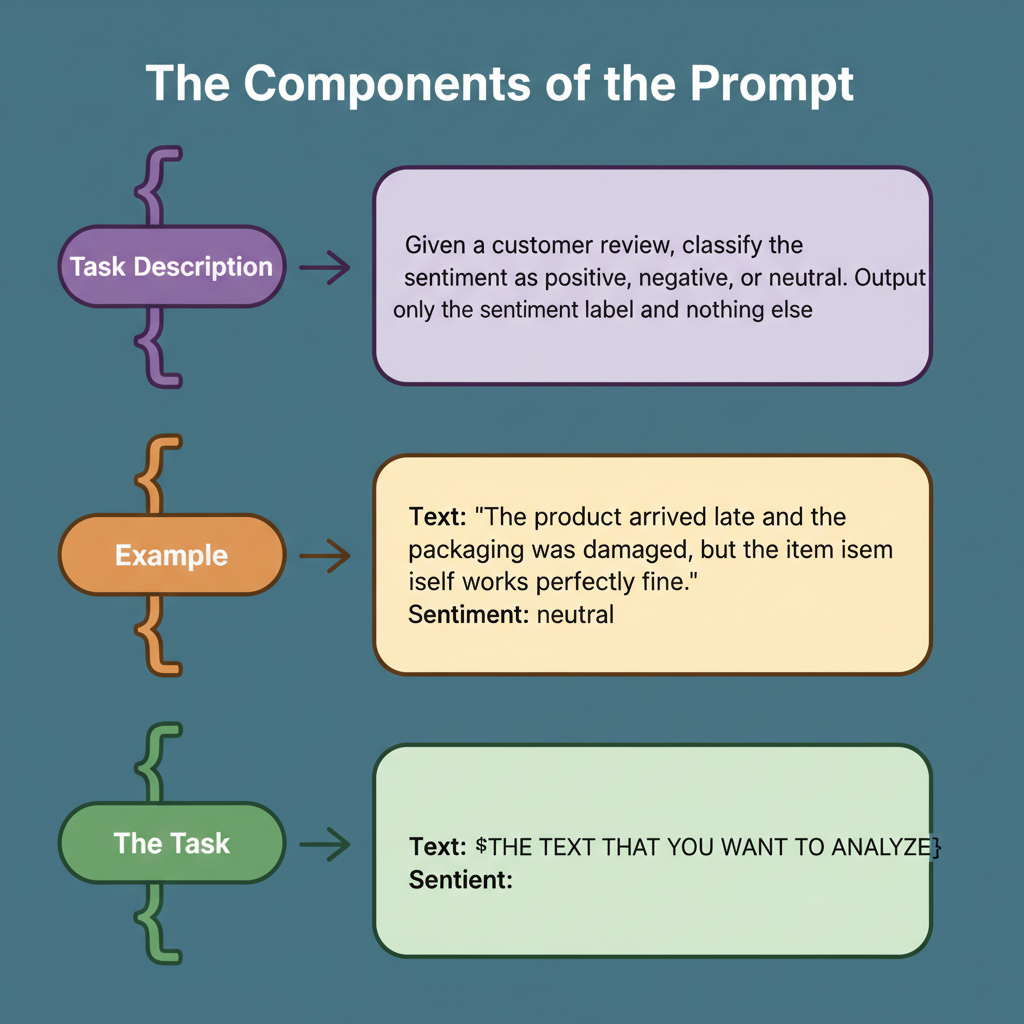
A well-constructed prompt typically comprises several distinct elements.
The task description delineates the desired action from the model, including any specific role or persona it should adopt.
Context furnishes essential background information, while examples serve to illustrate the intended behavior or output format.
Finally, the concrete task represents the precise query to be addressed or the action to be executed.
(URL: https://substackcdn.com/image/fetch/$s_!m8zA!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc2e29c35-4357-4259-a7f2-d33d2cc57399_3086x1854.png)
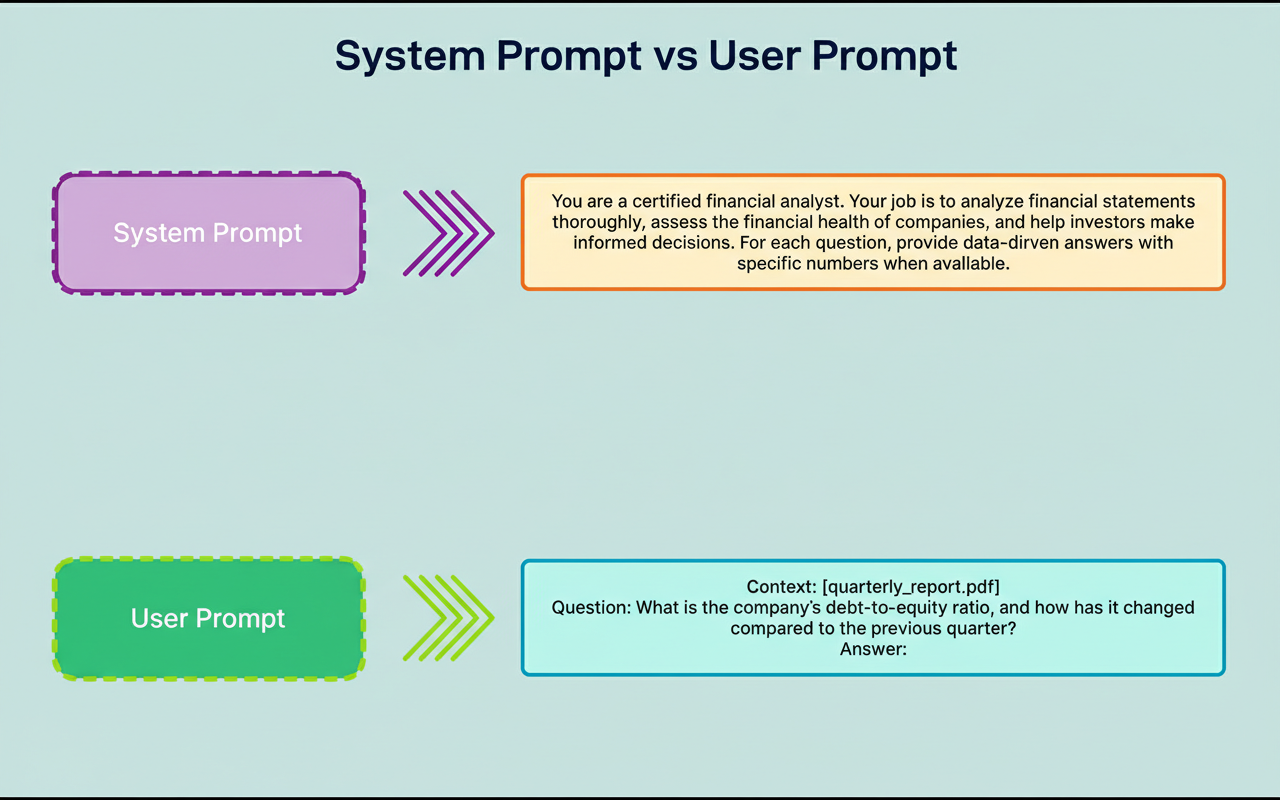
Many model APIs facilitate the division of prompts into system prompts and user prompts.
System prompts typically encapsulate task definitions and role-playing directives that define the model’s behavior throughout an interaction.
Conversely, user prompts articulate the actual task or question. For instance, in developing a chatbot to assist buyers with property disclosures, a system prompt might instruct the model to operate as an experienced real estate agent, whereas the user prompt would contain the specific inquiry regarding a property.
The following diagram illustrates this concept:
 (URL: https://substackcdn.com/image/fetch/$s_!r8S6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0e8adb37-e5b7-49b5-ae0c-b6b91d488e45a_3086x1854.png)
(URL: https://substackcdn.com/image/fetch/$s_!r8S6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0e8adb37-e5b7-49b5-ae0c-b6b91d488e45a_3086x1854.png)
Clarity stands as a paramount factor for effective prompting. Just as lucid human communication ensures mutual understanding, precise and unambiguous instructions guide AI models toward generating appropriate responses. Prompt engineers must articulate requirements explicitly, define any expected scoring systems or output formats, and avoid making assumptions about the model’s pre-existing knowledge.
Context holds comparable significance. Providing relevant information enables models to perform optimally and mitigates the incidence of hallucinations. For example, if a model is intended to answer questions about a research paper, embedding that paper within the context will substantially enhance the quality of its responses. Without adequate context, the model is compelled to rely on its inherent knowledge, which may be outdated or erroneous.
In-context learning constitutes the foundational mechanism underpinning successful prompt engineering.
This concept denotes a model’s inherent capacity to acquire new behaviors from examples supplied directly within the prompt, without necessitating any alterations to the model’s internal weights. When a model is presented with instances demonstrating a task, it can then modify its subsequent responses to conform to the established pattern.
Models generally exhibit superior comprehension of instructions positioned at the beginning and end of prompts, as opposed to those situated in the middle. This phenomenon, often termed the “needle in a haystack” problem, underscores the importance of strategically placing crucial information within prompts.
The requisite number of examples is contingent upon both the model’s inherent capabilities and the complexity of the specific task. More robust models typically demand fewer examples to grasp the intended objective. For less intricate tasks, highly capable models might not necessitate any examples whatsoever. However, for highly specialized applications or scenarios demanding complex output formatting, supplying several illustrative examples can yield substantial improvements.
Several essential prompting techniques are examined below:
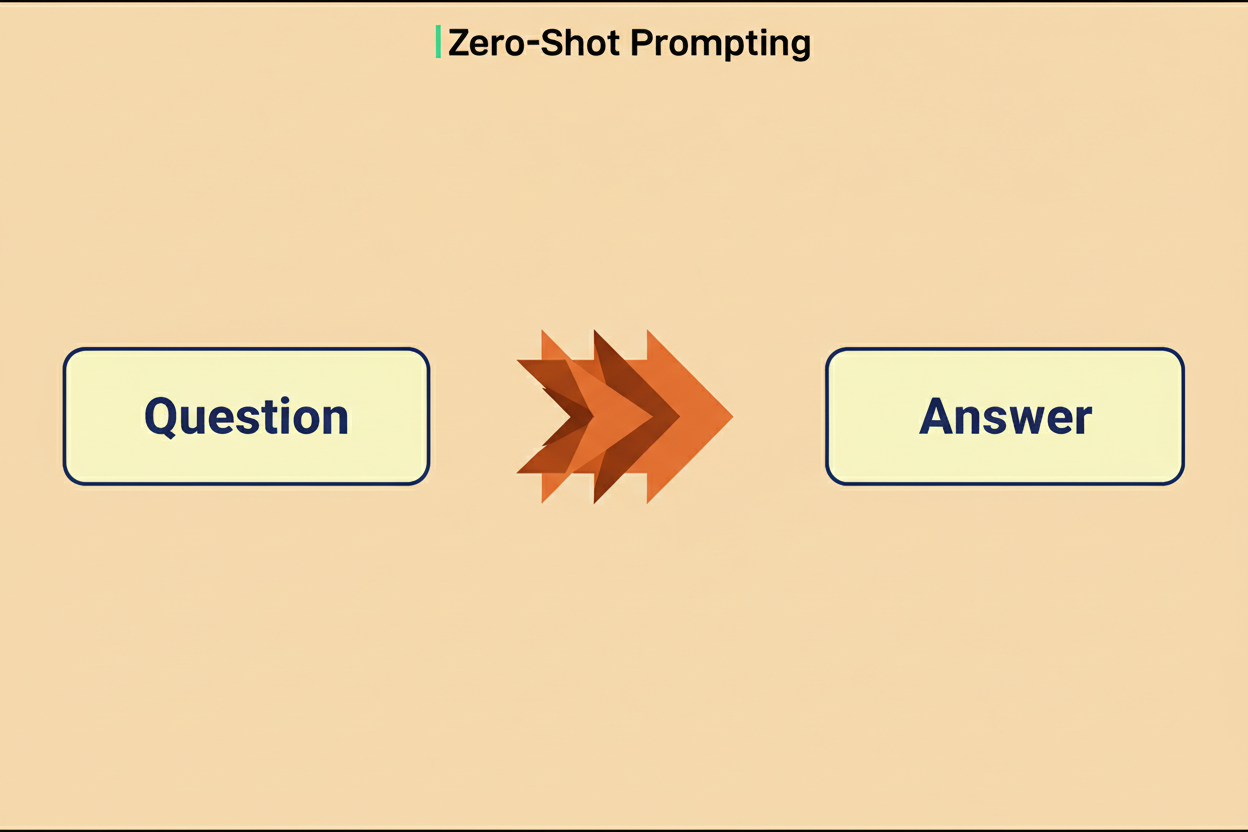
Zero-shot prompting involves presenting instructions to the model without including any illustrative examples. In this methodology, the desired outcome is merely described, and the model endeavors to satisfy the request utilizing its pre-existing training.
 (URL: https://substackcdn.com/image/fetch/$s_!DBiE!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F6bca809b-4432-4675-830c-b1dea92680f6_3356x2190.png)
(URL: https://substackcdn.com/image/fetch/$s_!DBiE!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F6bca809b-4432-4675-830c-b1dea92680f6_3356x2190.png)
This technique proves most effective for uncomplicated tasks where the intended output is self-evident from the instructions themselves. For instance, directives such as “Translate the following text to French” or “Summarize this article in three sentences” both exemplify effective zero-shot prompts.
The primary benefit of zero-shot prompting lies in its efficiency. It consumes fewer tokens, thereby decreasing computational costs and reducing latency. Furthermore, these prompts are simpler to compose and manage. Nevertheless, zero-shot prompting possesses limitations. When specific formatting or behavior deviating from the model’s default responses is required, zero-shot prompts might prove inadequate.
Optimal practices for zero-shot prompting necessitate maximum explicitness regarding the desired outcome, clear specification of the output format, and upfront declaration of any constraints or prerequisites. If the model’s initial response fails to meet expectations, prompt engineers should refine the prompt by incorporating additional detail rather than immediately resorting to few-shot examples. This approach supports efficient capacity planning for AI inference.
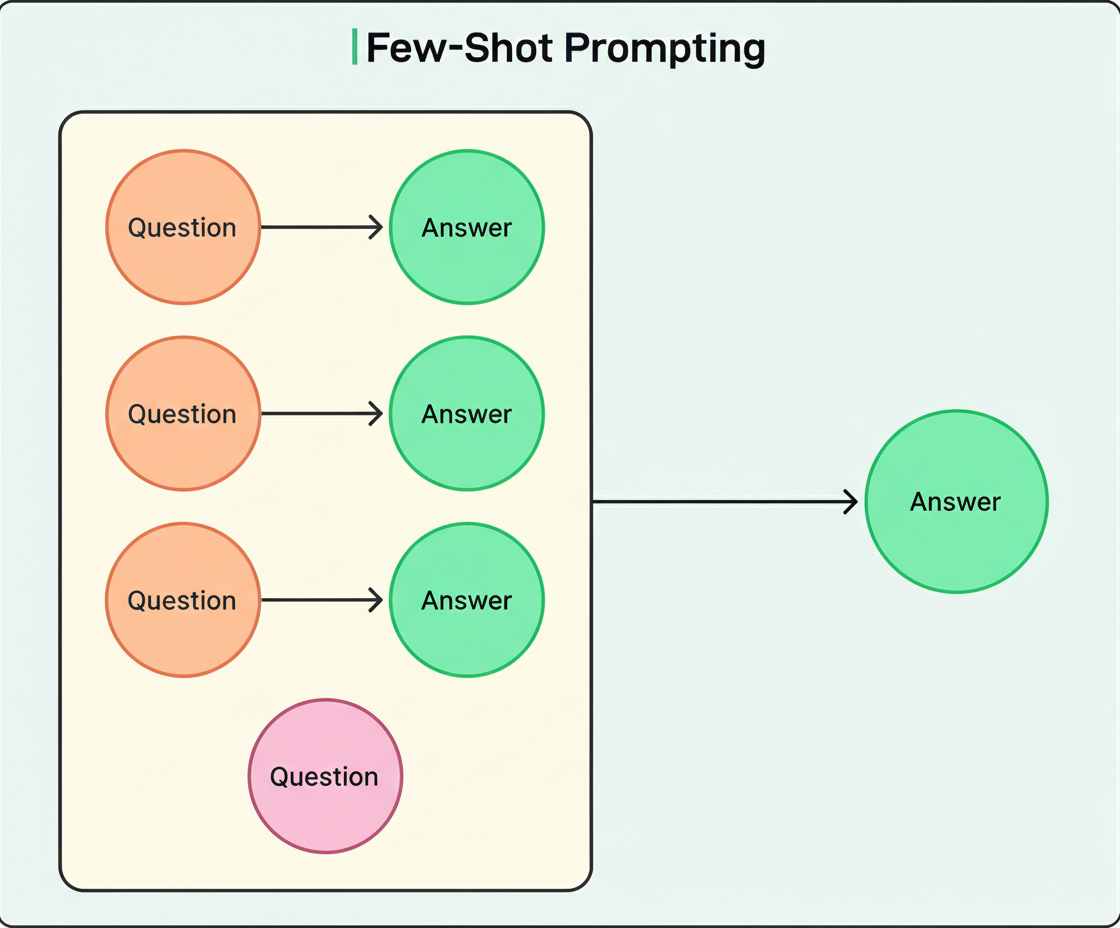
Few-shot prompting entails supplying examples that illustrate the desired model response. One-shot prompting utilizes a singular example, whereas few-shot generally denotes two to five or more examples.
 (URL: https://substackcdn.com/image/fetch/$s_!0zTh!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe0754b84-f1a7-4880-89de-ca30820fc79d_2660x2190.png)
(URL: https://substackcdn.com/image/fetch/$s_!0zTh!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe0754b84-f1a7-4880-89de-ca30820fc79d_2660x2190.png)
This methodology proves invaluable when precise formatting is required, or when the intended behavior might be unclear from instructions alone. For example, when developing a bot for interacting with young children, aiming for a specific response style to questions about fictional characters, an illustrative example aids the model in comprehending the desired tone and approach.
Consider a comparative scenario: Without an example, if a child inquires, “Will Santa bring me presents on Christmas?”, a model might respond by explaining Santa Claus’s fictional nature. However, by providing an example such as “Q: Is the tooth fairy real? A: Of course! Put your tooth under your pillow tonight,” the model learns to sustain a magical perspective suitable for young audiences.
The quantity of examples significantly impacts performance. A greater number of examples typically yields superior results, though limitations exist concerning context length and associated costs. For the majority of applications, three to five examples often strike an effective balance. Experimentation is recommended to determine the optimal count for a specific use case, mirroring the iterative approach in Black Friday Cyber Monday scale testing.
When structuring examples, token efficiency can be achieved through streamlined formats. For instance, “pizza -> edible” consumes fewer tokens than “Input: pizza, Output: edible” while conveying identical information. Such minor optimizations accumulate, particularly when managing numerous examples, a principle also vital in optimizing edge network requests per minute during peak loads like Shopify BFCM readiness.
Chain-of-Thought (CoT) prompting instructs the model to explicitly delineate its reasoning process step by step prior to furnishing an answer. This methodology fosters systematic problem-solving and has demonstrated substantial performance enhancements on intricate reasoning tasks.
The most straightforward implementation involves incorporating phrases such as “think step by step” or “explain your reasoning” into the prompts. The model subsequently addresses the problem methodically, illustrating its thought process before reaching a conclusion.
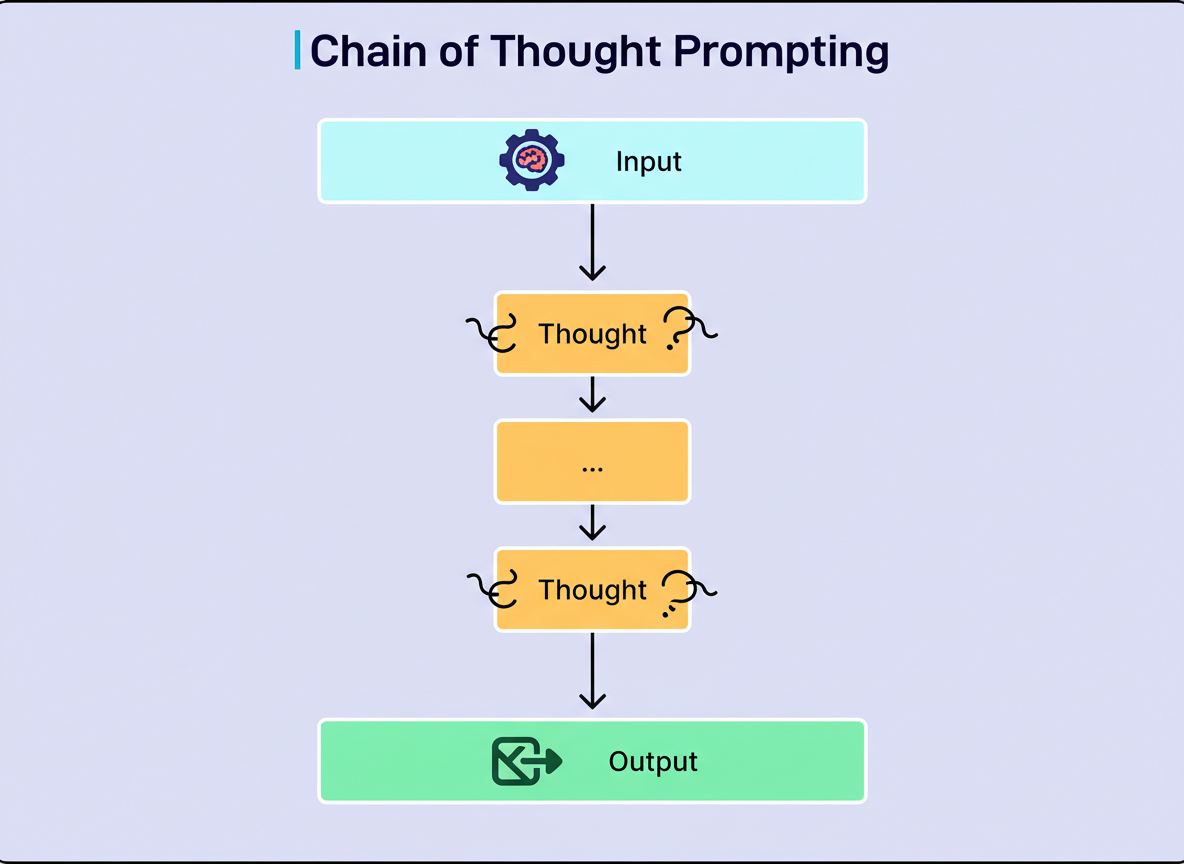 (URL: https://substackcdn.com/image/fetch/$s_!eEa-!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F003d2ad0-9467-459d-982b-1ac9c5bb339c_2660x1904.png)
(URL: https://substackcdn.com/image/fetch/$s_!eEa-!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F003d2ad0-9467-459d-982b-1ac9c5bb339c_2660x1904.png)
CoT frequently elevates model performance across a spectrum of benchmarks, particularly for mathematical challenges, logic puzzles, and multi-step inference problems. Furthermore, CoT aids in diminishing hallucinations by requiring the model to substantiate its responses with explicit reasoning stages.
CoT can be deployed through various methods. Zero-shot CoT simply appends a reasoning instruction to the prompt. Alternatively, specific steps for the model to follow can be outlined, or examples showcasing the reasoning process can be provided. The choice of variation depends on the particular application and the desired degree of control over the reasoning framework.
The inherent trade-off with CoT lies in increased latency and operational cost. The model generates a greater volume of tokens as it progresses through its reasoning, which consequently prolongs processing time and elevates API expenses. For complex tasks where precision is paramount, this compromise is typically justifiable.
Role prompting involves assigning a specific persona or domain of expertise to the model. By instructing the model to embody a particular role, prompt engineers can influence the perspective and stylistic nuances of its generated responses.
For instance, if a model is tasked with scoring a basic essay such as “Summer is the best season. The sun is warm. I go swimming. Ice cream tastes good in summer,” it might yield a low score based on conventional writing metrics. However, if the model is first directed to adopt the persona of a first-grade teacher, it will assess the essay from that viewpoint, likely conferring a higher, more fitting score.
Role prompting demonstrates significant efficacy in customer service applications, educational material generation, creative writing, and any context where specific domain expertise or contextual understanding is crucial. The model can adapt its lexicon, level of granularity, and overall approach according to the designated role.
When employing role prompting, it is essential to be precise regarding the assigned role and any pertinent attributes. Instead of a general instruction like “act as a teacher,” a more refined directive might be “act as an encouraging first-grade teacher who focuses on effort and improvement.” Greater specificity enables the model to more accurately internalize and express that perspective.
Prompt chaining involves segmenting intricate tasks into smaller, more manageable subtasks, each addressed by its own distinct prompt. Rather than processing an entire complex request within a single, expansive prompt, a sequence of simpler prompts is created and linked cohesively.
Consider the operational flow of a customer support chatbot. The procedure for responding to a customer inquiry can be logically broken down into two principal stages:
The initial prompt is dedicated exclusively to ascertaining whether the customer requires assistance with billing, technical support, account management, or general information. Following this classification, a subsequent, specialized prompt is then employed to formulate the actual response.
This methodology presents several advantages. Each individual prompt is simpler to compose and sustain. Monitoring and debugging can be conducted independently for each step. Furthermore, different models can be leveraged for various stages, potentially utilizing a faster, more cost-effective model for intent classification and a more robust model for response generation. Independent steps can also be executed in parallel when feasible, akin to optimizing distributed systems in Google Cloud multi-region deployments.
The primary disadvantage manifests as increased perceived latency for end users. The sequential nature of multiple steps means users experience a longer wait for the final output. Nevertheless, for sophisticated applications, the enhanced reliability and ease of maintenance frequently eclipse this particular concern. This technique can also be used in chaos engineering scenarios to isolate and test specific components of a system.
Several optimal practices for constructing effective prompts are outlined below:
Be Clear and Specific: Ambiguity is antithetical to effective prompting. All uncertainty regarding the model’s intended action must be eradicated. If a model is required to grade essays, the scoring scale must be precisely defined. Should it employ a 1 to 5 or 1 to 10 range? Are fractional scores permissible? What action should the model take in cases of scoring uncertainty?
Provide Sufficient Context: Adequate context empowers models to generate precise and pertinent responses. When a model is expected to answer questions pertaining to a document, embedding that document within the prompt is indispensable. Without it, the model must exclusively depend on its training data, which might yield obsolete or inaccurate information.
Specify Output Format: It is crucial to explicitly dictate the desired response format from the model. Is a concise answer preferred, or a comprehensive explanation? Should the output adhere to JSON, a bulleted list, or a standard paragraph structure? Should the model include introductory remarks, or proceed directly to the core information?
Use Examples Strategically: Examples serve as potent instruments for mitigating ambiguity, albeit at the expense of tokens and context length. Examples should be furnished when the desired format or behavioral pattern is not self-evident from instructions alone. For uncomplicated tasks, examples may be superfluous.
Iterate and Experiment: Prompt engineering is inherently an iterative discipline. Rarely does one formulate the perfect prompt on the initial attempt. A prudent approach involves commencing with a fundamental prompt, rigorously testing it, observing the outcomes, and refining it based on the insights gained.
Versioning Prompts: Implementing a versioning system for prompts allows for tracking modifications over time. Employing consistent evaluation datasets facilitates objective comparisons between different prompt iterations. Prompts should be validated not merely in isolation but within the broader context of the entire system to ensure that enhancements in one domain do not inadvertently introduce issues elsewhere.
Several prevalent pitfalls to be circumvented during prompt composition include:
Being Too Vague: A frequent error involves presuming the model comprehends the prompt engineer’s intent without explicit elucidation. Ambiguous prompts, such as “write something about climate change,” leave excessive room for interpretation. Is a scientific explanation, a persuasive essay, a news article, or a social media post desired? What is the preferred length? What perspective should be adopted? The model will exercise its own discretion, which may not align with the actual requirements.
Overcomplicating Prompts: While clarity and detailed instruction are paramount, an overabundance can be counterproductive. Excessively complex prompts, replete with superfluous instructions, an excessive number of examples, or convoluted logic, can confound the model rather than assist it. The objective should be the simplest prompt capable of achieving the desired outcome. If a zero-shot prompt performs adequately, the inclusion of examples is unnecessary. If three examples suffice, five may not yield improved results.
Ignoring Output Format: Neglecting to specify the output format can precipitate issues, particularly when model outputs serve as inputs for subsequent systems. If structured data is required but not explicitly requested, the model might generate unstructured text necessitating additional parsing or cleaning. This introduces complexity and potential points of failure within the application.
Not Testing Sufficiently: A singular successful output does not guarantee prompt reliability. Prompts must be rigorously tested with diverse inputs, encompassing edge cases and atypical scenarios. Functionality observed in typical cases may falter when inputs are marginally different or entirely unforeseen. Constructing a modest evaluation dataset and conducting systematic testing aids in identifying vulnerabilities before they manifest as production issues. This rigor is reminiscent of thorough chaos engineering practices.
Effective prompt engineering is characterized by the synergy of lucid communication, judicious application of examples, and systematic experimentation.
The fundamental techniques examined herein—including zero-shot prompting, few-shot prompting, chain-of-thought reasoning, role prompting, and prompt chaining—establish a robust framework for interacting with AI language models.
The paramount principles remain uniform across diverse models and applications: