
The information presented in this post is derived from details publicly shared by the Meta Engineering Team, to whom all technical credit is attributed. Original articles and sources are listed in the references section. An analysis of these details is provided; any inaccuracies or omissions can be brought to attention for correction.
In Q2 2025, Meta announced that its new Generative Ads Model (GEM) had resulted in a 5% increase in ad conversions on Instagram and a 3% increase on Facebook Feed. While these figures might appear modest in isolation, their impact at Meta’s immense scale translates into billions of dollars of additional revenue, signifying a profound evolution in AI-driven advertising.
GEM stands as the largest foundation model ever constructed for recommendation systems, with training conducted at a scale typically associated with large language models such as GPT-4 or Claude. Nevertheless, a key challenge emerged: GEM’s inherent power and computational intensity preclude its direct application in serving ads to users.
To address this, Meta engineered a teacher-student architecture. This design enables smaller, more agile models to leverage GEM’s advanced intelligence without incurring its substantial computational overhead. This article delves into the methodologies employed by the Meta engineering team in building GEM and examines the complexities successfully navigated throughout its development.
Billions of users navigate Facebook, Instagram, and other Meta platforms daily, generating trillions of potential ad impression opportunities. Each impression signifies a critical decision point: determining which advertisement, from a vast pool of millions, should be presented to a particular user at a precise moment. Incorrect ad placement results in inefficient advertiser spending on irrelevant ads and a diminished user experience. Conversely, accurate targeting fosters value for all stakeholders.
Previous ad recommendation systems encountered several difficulties. Some implementations managed each platform independently, preventing user behavior insights from Instagram from informing Facebook predictions. This compartmentalized strategy overlooked valuable cross-platform trends. Other systems attempted to apply identical approaches across all platforms, disregarding the distinct ways individuals interact with Instagram Stories versus Facebook Feed. Neither method proved optimal.
The complexity of data further intensifies these challenges, manifesting in the following aspects:
The objective of GEM was to establish a singular, cohesive intelligence capable of comprehending users comprehensively throughout Meta’s expansive ecosystem. This involved assimilating extensive behavioral histories and intricate cross-platform patterns while retaining the specificity required to optimize for each distinct surface and objective.
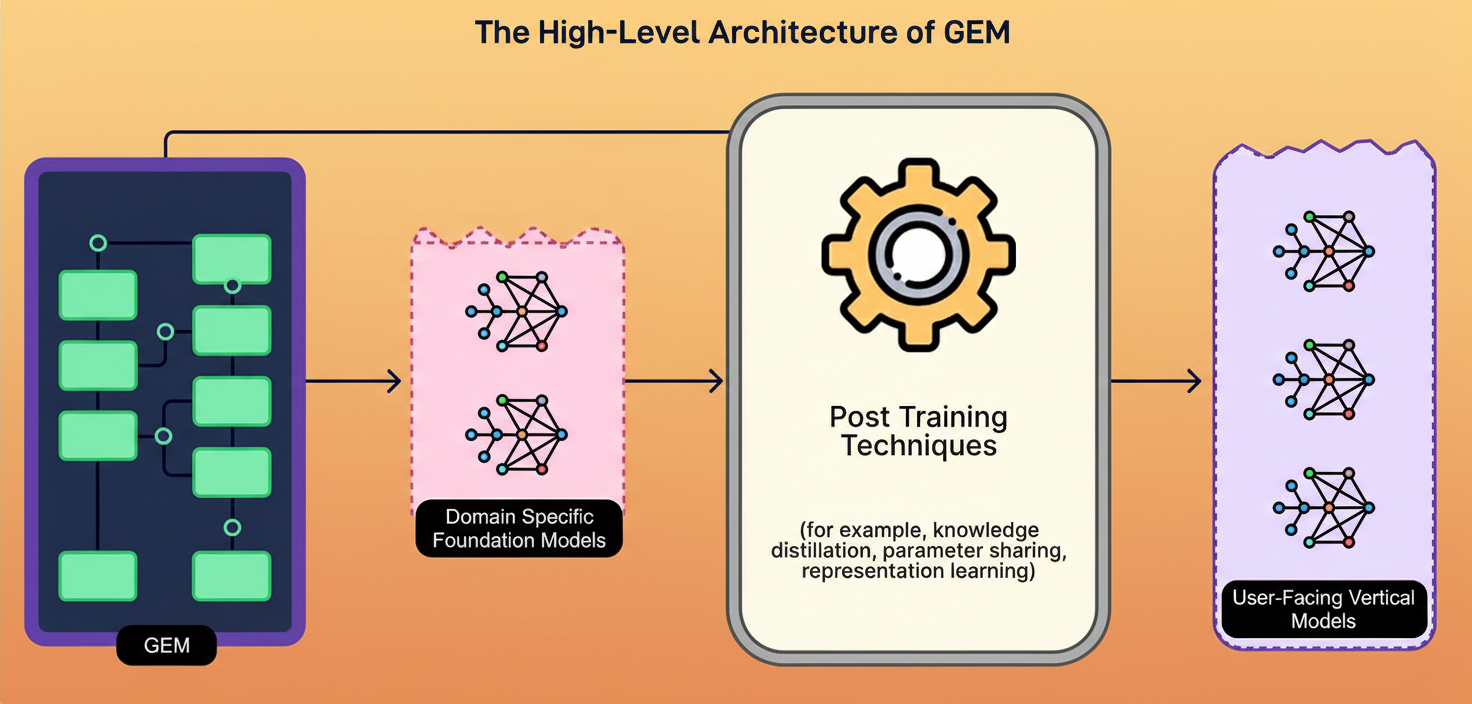
GEM’s architecture facilitates the processing of user and ad information through three interconnected systems, each addressing a distinct facet of the prediction challenge.
The initial system manages what Meta categorizes as non-sequence features, essentially comprising static attributes and their various combinations. These encompass user demographics such as age and location, user interests, ad characteristics like format and creative content, and the specific objectives of advertisers.
The complexity in this area lies not merely in identifying individual features, but in comprehending their intricate interactions. For instance, a 25-year-old technology professional exhibits markedly different purchasing behaviors compared to a 25-year-old educator, even if they share certain interests. The system is designed to ascertain which combinations of features hold genuine predictive significance.
GEM incorporates an enhanced iteration of the Wukong architecture, employing stackable factorization machines engineered for scalable operations. This scalability applies both vertically, for deeper interaction analysis, and horizontally, for broader feature coverage. The architecture functions through multiple stacked layers, with each successive layer assimilating increasingly complex patterns derived from the simpler patterns identified by preceding layers. For example, an initial layer might ascertain the fundamental trend that young professionals respond positively to technology product advertisements. A subsequent, deeper layer within the stack refines this by learning that young professionals in urban environments who demonstrate an interest in fitness react particularly well to smart wearable ads. An even more profound layer might further specify that this combination yields optimal results when such advertisements emphasize data tracking functionalities rather than purely aesthetic elements.
The second system addresses sequence features, which chronicle the chronological progression of user behavior. User actions are not isolated events; they collectively narrate a story characterized by order and meaning. An individual who clicks on home workout content, subsequently searches for nearby gyms, then views several gym websites, and later researches membership costs is demonstrably on a specific journey. Prior architectures struggled with the efficient processing of extended sequences due to the rapid escalation of computational costs with increasing sequence length.
GEM mitigates this challenge through a pyramid-parallel structure. This approach can be conceptualized as processing segments of behavioral history at a foundational level, then integrating these segments into broader patterns at intermediate levels, and ultimately synthesizing all information into a comprehensive understanding of the complete user journey at the apex. The simultaneous processing of multiple segments, rather than sequential handling, substantially enhances efficiency.
The pivotal advancement here resides in scale. GEM can now analyze thousands of past user actions, a significant expansion beyond the limited handful previously considered. This extended perspective uncovers patterns that shorter observational windows simply cannot capture, such as the evolution from a casual interest to a serious purchase intent that may unfold over several months. To illustrate this process, refer to the diagram below:
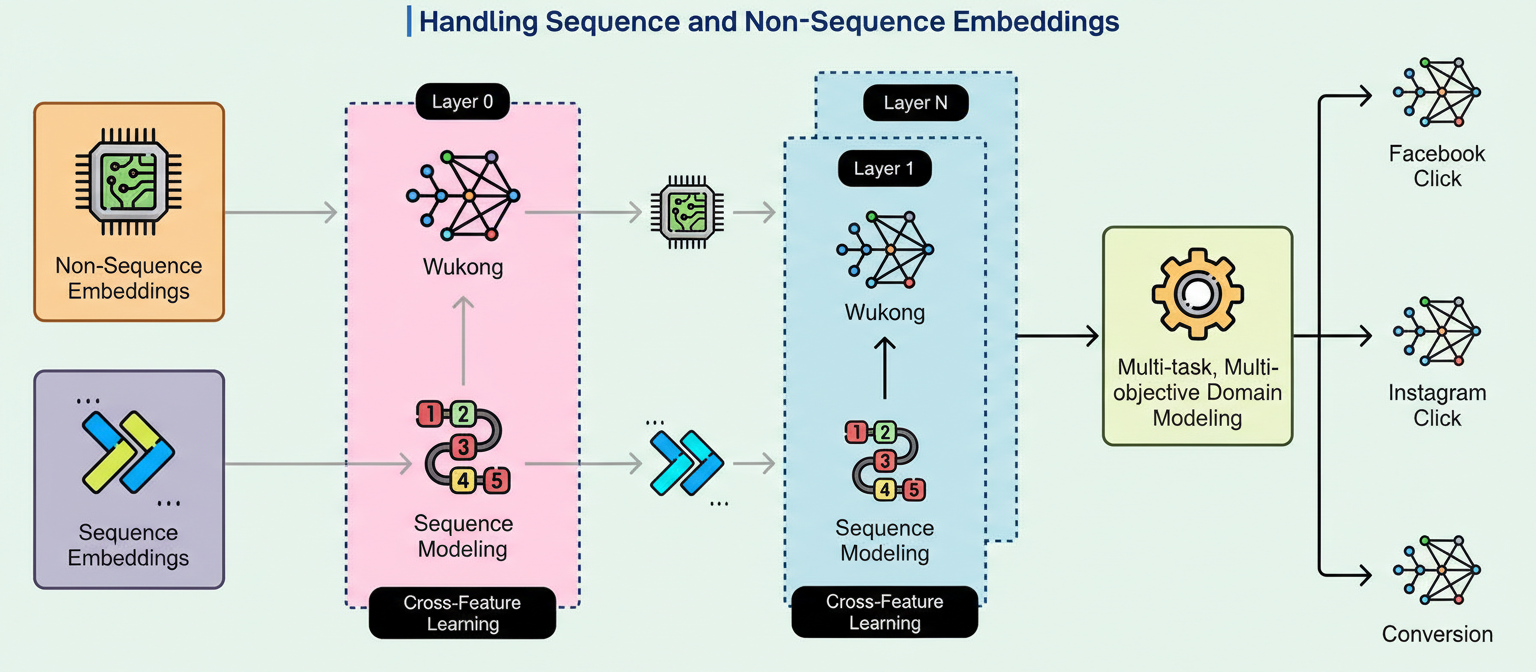
The third system, known as InterFormer, facilitates cross-feature learning by forging connections between a user’s static profile and their behavioral timeline. This component truly highlights GEM’s sophisticated intelligence. Conventional methodologies often compressed an entire behavioral history into a concise summary vector, akin to condensing a complete novel into a single rating. Such compression invariably led to the loss of crucial details concerning the user’s journey.
InterFormer adopts a distinct strategy through an interleaving structure. It alternates between layers primarily dedicated to comprehending the behavioral sequence and layers that establish linkages between those behaviors and the user’s profile attributes.
This alternating process persists through multiple layers, with each cycle refining understanding while retaining access to the comprehensive behavioral record.
Despite GEM’s inherent capabilities, Meta encountered a fundamental engineering hurdle in its operational deployment.
GEM’s immense scale, resulting from training across thousands of GPUs over extended durations, rendered its direct application for every ad prediction impractically slow and costly. When a user navigates platforms like Instagram, the system mandates ad decisions within tens of milliseconds. GEM, therefore, cannot achieve this speed while simultaneously catering to billions of users.
Meta’s resolution involved a teacher-student architecture, where GEM assumes the role of a primary instructor, educating hundreds of smaller, swifter Vertical Models (VMs) responsible for actual ad serving in production environments. These VMs are meticulously specialized for particular contexts, such as Instagram Stories click prediction or Facebook Feed conversion prediction. Each VM is sufficiently lightweight to execute predictions in milliseconds; however, their intelligence surpasses what independent training would yield, owing to their learning directly from GEM.
Knowledge transfer is facilitated through two primary strategies. Direct transfer is applicable when a VM operates within the same domain as GEM’s training, sharing comparable data and objectives. In such instances, GEM can directly instruct these models. Hierarchical transfer is utilized when VMs function in specialized domains considerably divergent from GEM’s training scope. Here, GEM initially educates medium-sized, domain-specific foundation models for areas like Instagram or Facebook Marketplace. These domain models subsequently instruct the even smaller VMs, ensuring knowledge propagates through various levels, adapting and specializing at each stage.
Meta employs three advanced techniques to optimize transfer efficiency:
Collectively, these three methodologies achieve a two-fold increase in effectiveness compared to standard knowledge distillation alone. The continuous improvement cycle operates as follows:
This iterative cycle persists continuously, ensuring GEM consistently advances in intelligence and VMs receive regular updates to their knowledge base.
The development of GEM necessitated a comprehensive reconstruction of Meta’s training infrastructure.
The primary challenge involved training a model at a scale comparable to large language models (LLMs), yet for the distinct application of recommendation rather than language generation. The company successfully achieved a 23x increase in effective training throughput, concurrently employing 16x more GPUs and enhancing hardware efficiency by 1.43x.
This endeavor mandated innovations across multiple domains. Multi-dimensional parallelism meticulously coordinates the collaborative operation of thousands of GPUs, segmenting the model’s dense components via techniques such as Hybrid Sharded Distributed Parallel. Sparse components, including embedding tables, are managed through a combination of data and model parallelism. The overarching objective was to ensure continuous GPU activity, minimizing idle periods attributable to inter-GPU communication delays.
System-level optimizations further elevated GPU utilization:
The efficiency enhancements extended beyond mere raw training speed.
Meta achieved a 5x reduction in job startup time through optimizations in trainer initialization, data reader setup, and checkpointing procedures. PyTorch 2.0 compilation time was decreased by 7x by leveraging intelligent caching strategies. While these might appear as minor refinements, in the context of training models demanding millions of dollars in computational resources, every incremental percentage point of efficiency yields substantial value.
The outcome is a robust training system capable of rapid iteration on GEM, seamlessly integrating new data and architectural improvements at a pace previously unattainable with legacy infrastructure. This empowers Meta to maintain GEM at the forefront of recommendation AI, while concurrently managing costs sufficiently to justify the substantial investment.
Meta’s strategic trajectory for GEM extends significantly beyond its current operational capabilities.
The forthcoming major evolution encompasses genuine multimodal learning, wherein GEM will process text, images, audio, and video in an integrated manner, rather than as discrete input streams. This advancement will facilitate an even deeper comprehension of both user preferences and the efficacy of ad creatives across all content modalities. The company is also investigating inference-time scaling, a mechanism that would permit the system to dynamically allocate greater computational resources to complex predictions while processing more straightforward cases with enhanced efficiency.
Perhaps the most ambitious vision entails a unified engagement model that leverages the same underlying intelligence to rank both organic content and advertisements. This paradigm shift would fundamentally transform the integration of advertising within social feeds, potentially cultivating more fluid user experiences where ads are perceived as organic content recommendations rather than intrusive interruptions. From the advertiser’s perspective, GEM’s advanced intelligence is poised to enable more sophisticated agentic automation, empowering AI systems to manage and optimize campaigns with minimal human oversight, thereby achieving superior outcomes.