
In December 2024, DeepSeek launched V3, declaring the training of a frontier-class model at a cost of $5.576 million. This model incorporated a Multi-Head Latent Attention mechanism that significantly reduced memory consumption. An expert routing strategy effectively averted typical performance drawbacks. Additionally, aggressive FP8 precision training further lowered expenses.
Within a few months, the Moonshot AI team working on the Kimi K2 model publicly adopted DeepSeek’s architecture as a foundation, scaling it to a trillion parameters. They innovated a new optimizer addressing stability challenges encountered at this scale and competed with it extensively across prominent benchmarks.
By February 2026, Zhipu AI’s GLM-5 incorporated DeepSeek’s sparse attention technique into its own architecture while introducing a novel reinforcement learning framework.
This collaborative ecosystem demonstrates the open-weight model community’s modus operandi: teams build upon public innovations, accelerating collective advancement. To fully comprehend this progress, an examination of the underlying architecture is essential.
This article examines several open-source models alongside the engineering strategies shaping each design.
All leading open-weight large language models (LLMs) unveiled on the frontier in 2025 and 2026 utilize a Mixture-of-Experts (MoE) transformer architecture.
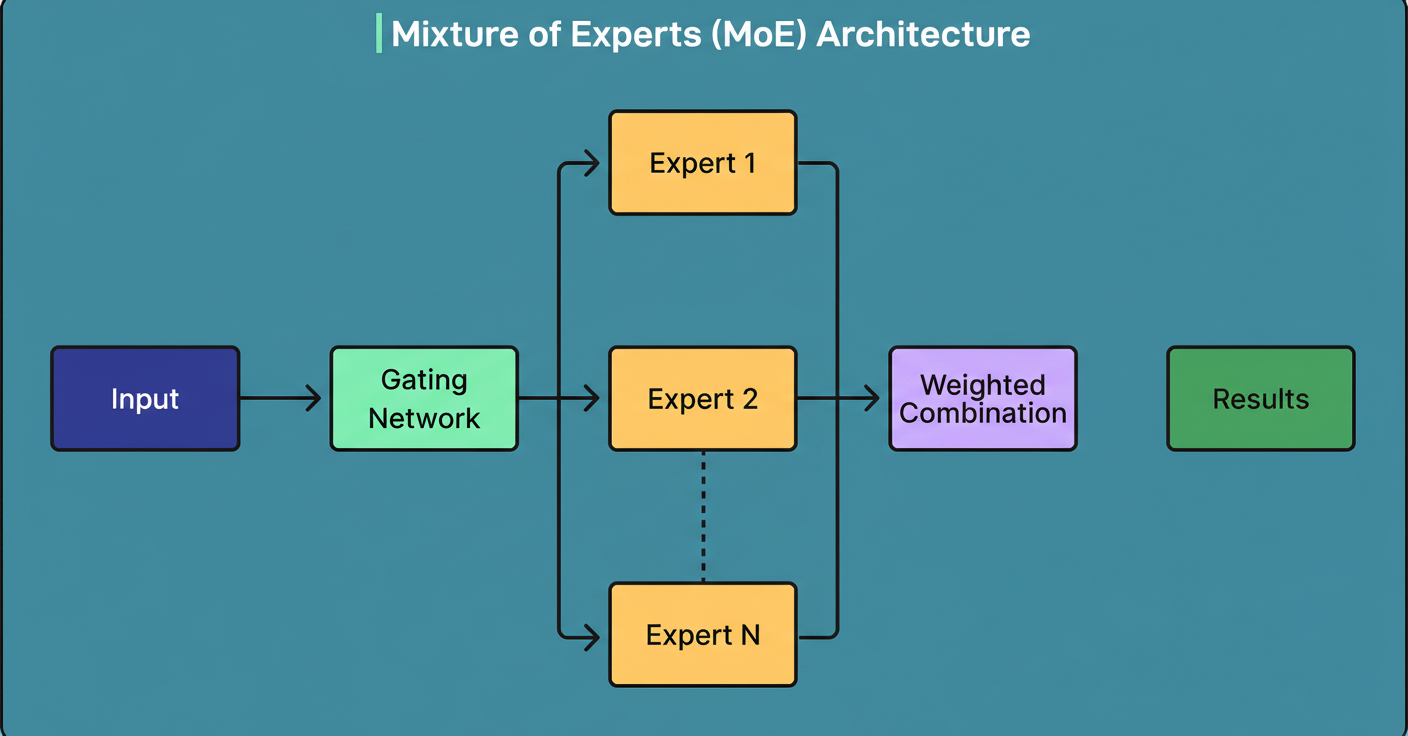
Refer to the diagram below illustrating the MoE architectural concept:
This design choice addresses the inefficiency inherent in dense transformers, which activate all parameters per token. Scaling up parameter counts in dense models results in linear growth in computational costs, becoming impractical at hundreds of billions of parameters.
MoE mitigates this by substituting the monolithic feed-forward layer in transformer blocks with multiple smaller “expert” networks managed by a learned router that selects which experts process each token. Consequently, a model may house 671 billion parameters yet only activate 37 billion per token.
Hence, two metrics are pivotal for every model:
An analogy equates this to a specialist hospital with 384 doctors available but only 8 attending any patient simultaneously, with a triage nurse directing the appropriate specialists.
This explains why models with vastly different total sizes, such as trillion-parameter and 235-billion-parameter models, can entail similar per-query costs. For instance, Kimi K2 activates 32 billion parameters per token, whereas Qwen3 activates 22 billion, focusing on active parameters instead of total counts.
Most models labeled as “open source” are technically open weight, meaning their trained parameters are accessible but their training data and full training code are often unavailable. In traditional open-source software, the code is available for modification and redistribution.
Practically, all six models discussed may be downloaded, fine-tuned, and commercially deployed. However, their training data remains undisclosed, and replicating their training runs from inception is unfeasible. For many engineering teams, accessible weights suffice, though understanding this distinction is important.
Licensing varies across these models: DeepSeek V3 and GLM-5 adopt the MIT license; Qwen3 and Mistral Large 3 use Apache 2.0, both fully permissive commercially. Kimi K2 applies a modified MIT license, whereas Llama 4 employs a custom community license that restricts use by companies exceeding 700 million monthly users and disallows training competing models.
Transparency levels differ, with some teams releasing comprehensive technical documentation, including architecture diagrams, ablation studies, and hyperparameters, while others provide weights accompanied by less detailed blog posts. Enhanced transparency fosters the “borrow and build” dynamic critical to the ecosystem’s success.
Each token generation requires recalling keys and values for prior tokens in a conversation, stored in a KV-cache that grows linearly with sequence length, posing a memory bottleneck for extended contexts. Models adopt one of three strategies to manage this challenge.
Grouped-Query Attention (GQA) shares key-value pairs across multiple query heads, representing the industry standard with straightforward implementation and moderate memory efficiency. Both Qwen3 and Llama 4 utilize GQA.
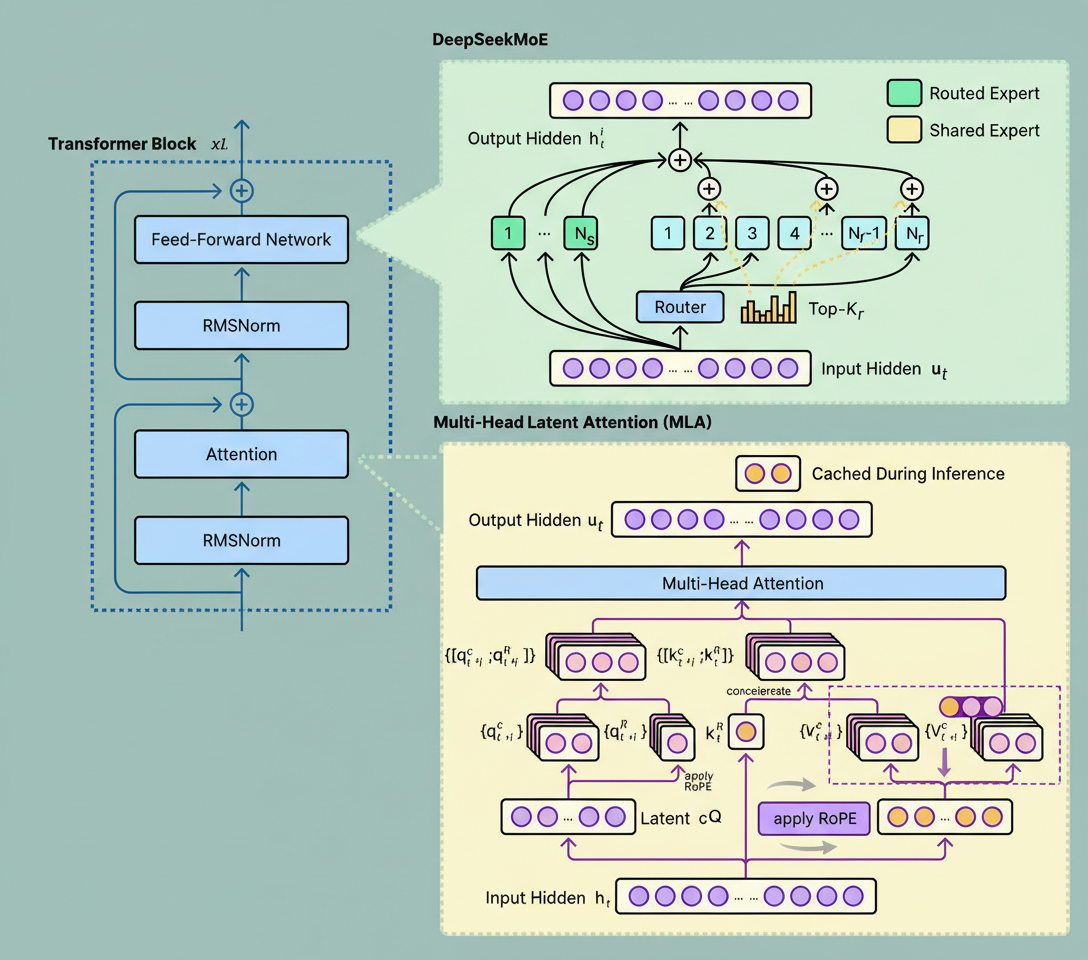
Multi-Head Latent Attention (MLA) compresses key-value pairs into a low-dimensional latent space for caching then decompresses them as needed. Introduced in DeepSeek V2 and employed in DeepSeek V3 and Kimi K2, MLA offers superior memory savings relative to GQA but incurs computational overhead from compression and decompression.
Sparse Attention selectively attends to only the most relevant previous tokens rather than all. Introduced in DeepSeek’s V3.2 as DeepSeek Sparse Attention (DSA), it was subsequently adopted by GLM-5. Sparse attention optimizes the attention mechanism while MoE improves feed-forward layers, making their combination beneficial for GLM-5.
A diagram below depicts DeepSeek’s Multi-Head Latent Attention methodology:
The choice of attention strategy depends on deployment priorities. GQA prioritizes simplicity and reliability; MLA offers enhanced memory efficiency at the cost of engineering complexity; and sparse attention reduces compute for long sequences but demands careful design to capture crucial tokens. The decision hinges on whether memory, computation, or context length forms the primary bottleneck.
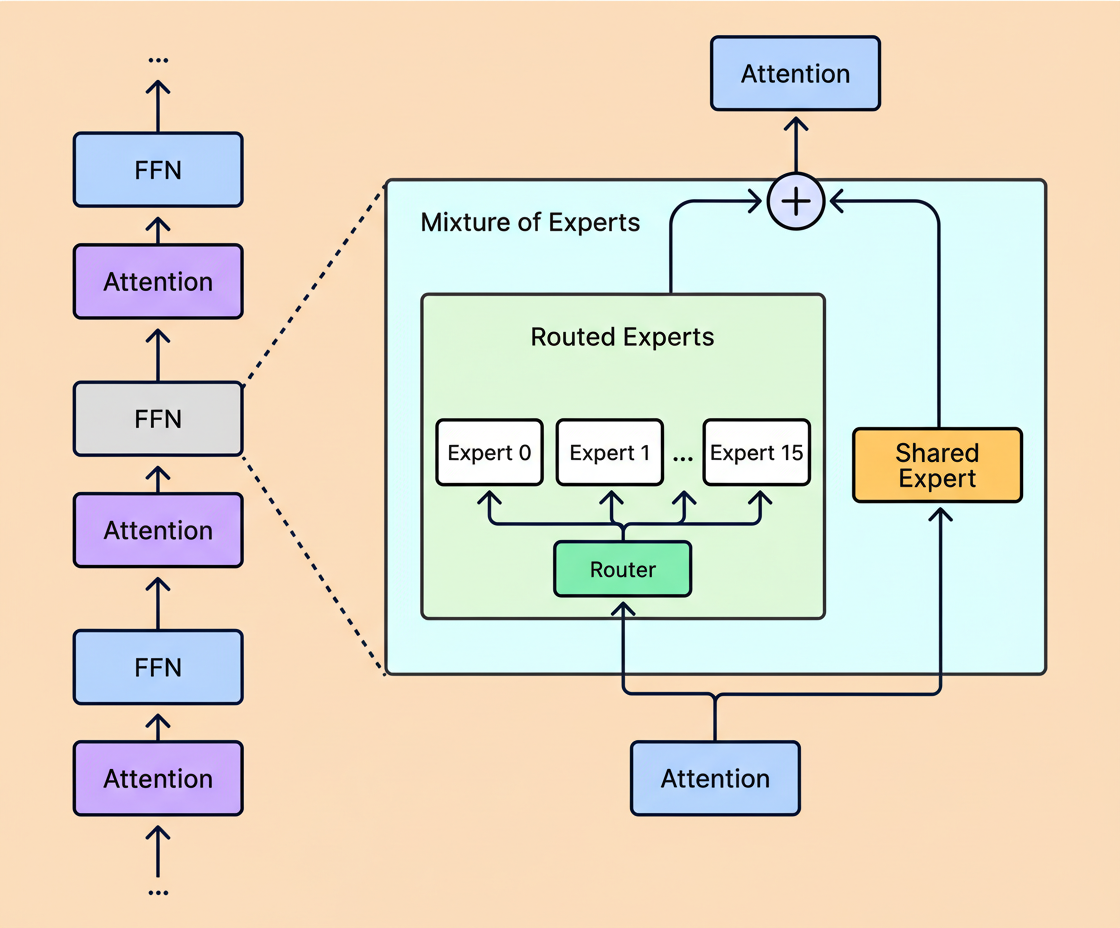
The six models encompass a range of 16 to 384 experts, reflecting differing opinions on sparsity’s extent.
With fixed compute resources, increasing expert count can improve training and validation losses but also amplifies infrastructure complexity. More experts entail larger cumulative parameter storage. For example, Kimi K2’s trillion-parameter scale necessitates a multi-GPU cluster regardless of expert activation per token, contrasting with Llama 4 Scout’s 109 billion parameters that fit on a single high-memory server.
Two design decisions are noteworthy:
See the diagram below illustrating Llama’s method:
While architecture establishes capacity, the training regimen shapes the model’s functional capabilities.
Pre-training teaches the model to predict subsequent tokens across trillions of tokens, imparting foundational knowledge. Token counts range from 14.8 trillion for DeepSeek V3 up to 36 trillion in Qwen3, with similar approaches.
Models diverge chiefly in post-training methods, now the key differentiator.
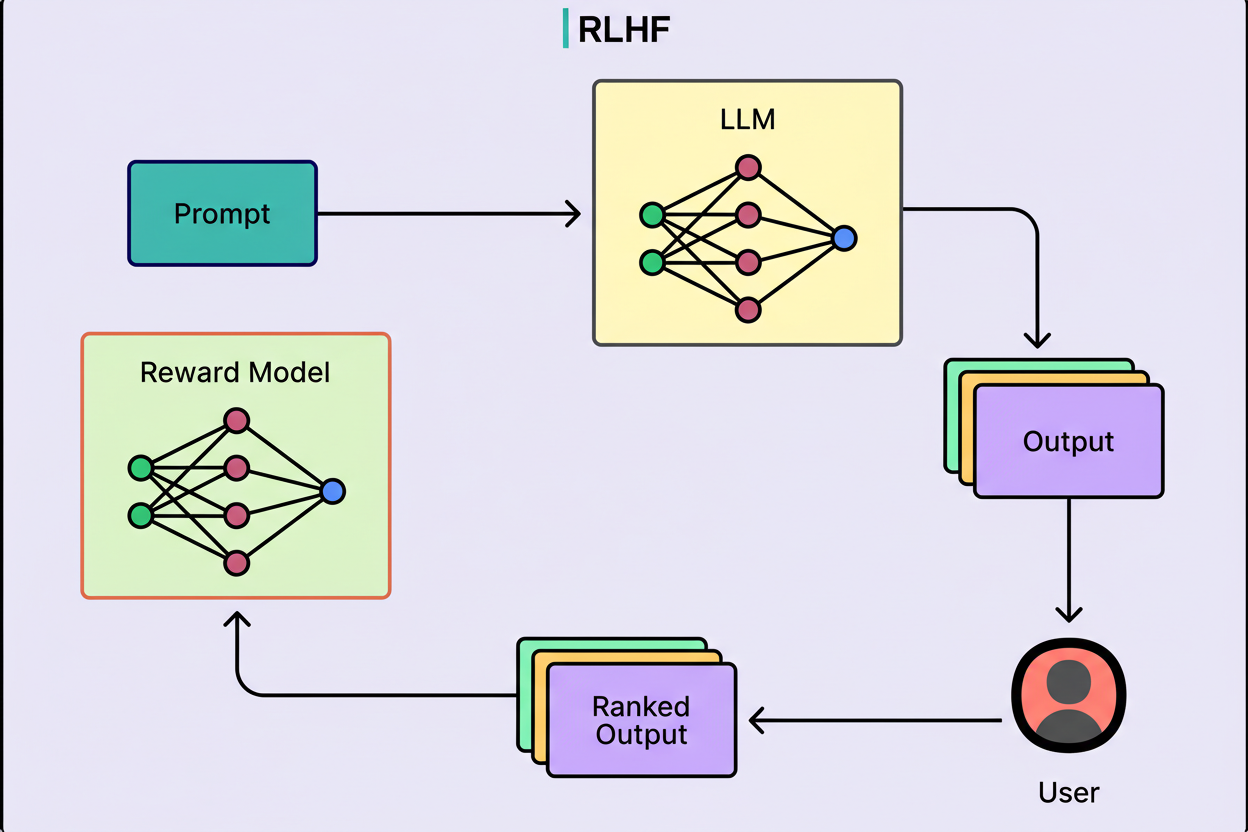
Reinforcement learning with verifiable rewards evaluates whether outputs are objectively correct, rewarding accurate results and penalizing errors. This concept was pivotal for DeepSeek R1 and influenced DeepSeek V3.
Diagram here illustrates this evaluation process:
Distillation leverages larger “teacher” models training smaller models using their outputs. Llama 4 was co-distilled from Behemoth, a 2-trillion-parameter model, during pre-training. Qwen3 similarly distills from its flagship to smaller family members.
The chart below displays Qwen’s post-training pipeline:
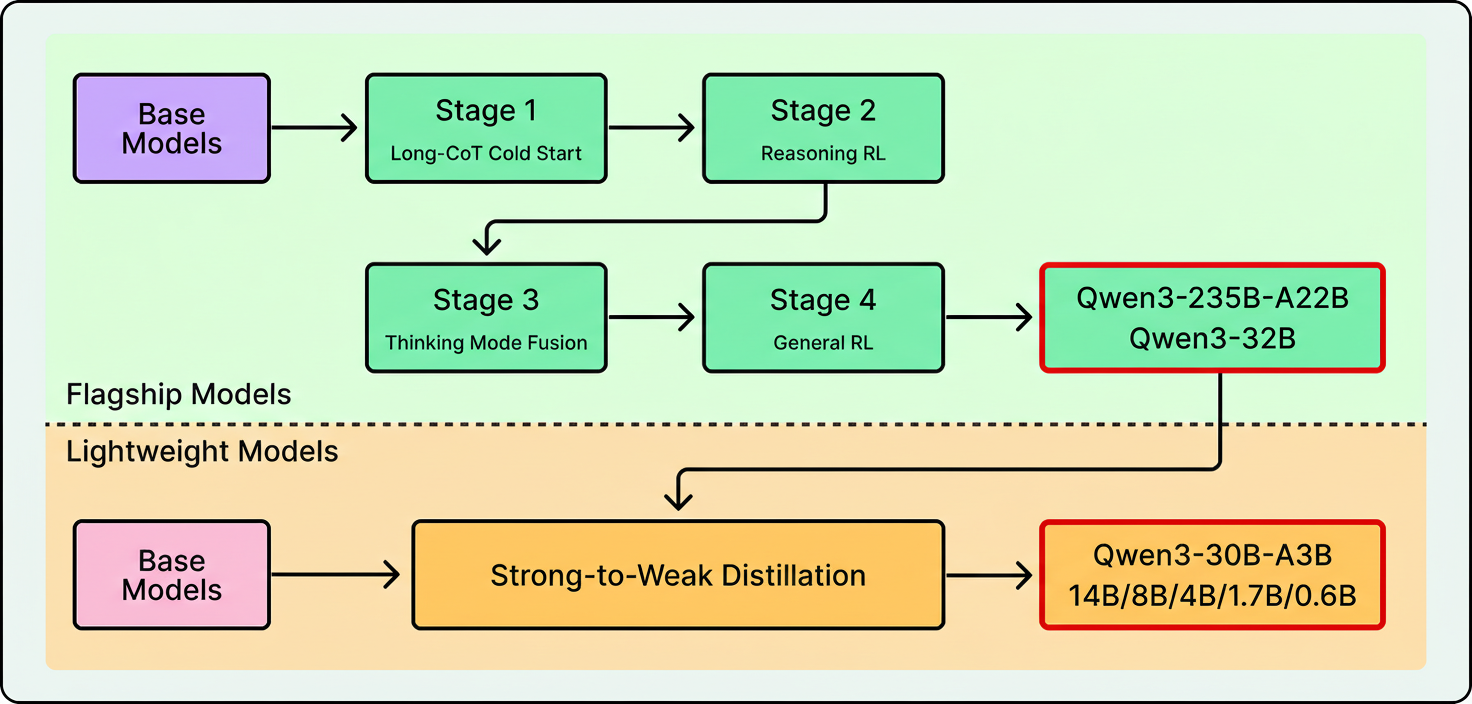
Synthetic agentic data involves simulated environments embedded with actual tools like APIs, shells, and databases to reward task completions. Kimi K2 details a system generating tool-use demonstrations across simulated and real settings.
Novel reinforcement learning infrastructures are also significant contributions. GLM-5 created “Slime,” an asynchronous reinforcement learning framework enhancing post-training throughput for more iterations within fixed compute budgets.
Training stability is crucial at this scale. Single failures can waste significant GPU time. Kimi K2 developed the MuonClip optimizer to prevent exploding attention logits, achieving training on 15.5 trillion tokens without loss spikes. DeepSeek V3 similarly reported uninterrupted training runs. These engineering advancements may have broader applicability than particular architectural choices.
Architectural trends reveal convergence on MoE transformers, while training strategies diverge with varied emphasis on reinforcement learning, distillation, synthetic data, and optimizer innovations.
Models featured here will likely be surpassed soon, yet the evaluation framework remains consistent.
Key considerations include active parameter counts over totals, attention strategies suited to context lengths, expert activation per token relative to infrastructure capacity, post-training methodologies aligned with applications, and licensing terms.
References: