
Pinterest’s engineering team initially developed Pinlater, an asynchronous job processing platform, to manage background tasks at scale. This platform successfully processed billions of jobs daily, supporting diverse functions such as Pin saves, notification deliveries, and image and video processing.
However, Pinterest’s continuous expansion eventually revealed significant limitations within Pinlater’s architecture.
Consequently, Pinterest undertook a comprehensive architectural redesign of its job processing system, resulting in the creation of Pacer. This article examines the development and operational principles of the Pacer system.
Before analyzing the challenges encountered with Pinlater and how Pacer addressed them, it is essential to comprehend the functionality of these systems.
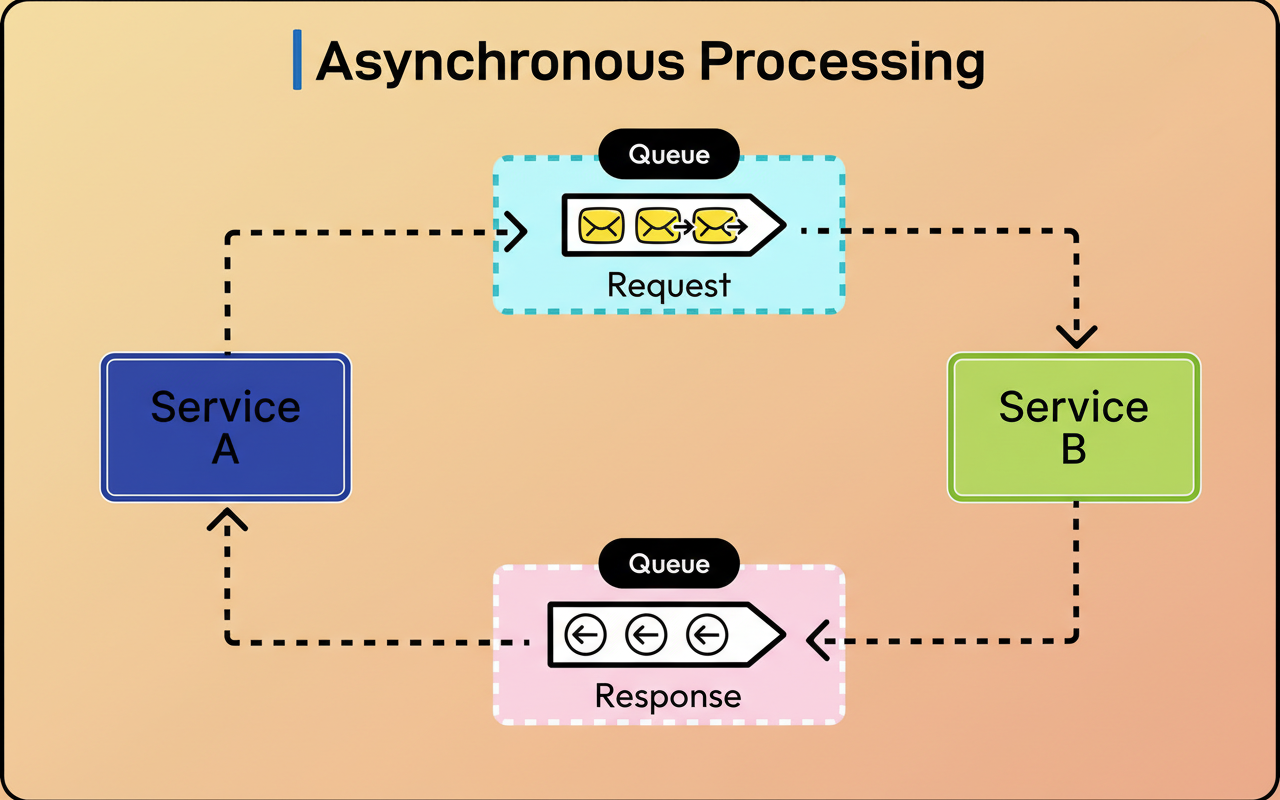
Upon saving a Pin on Pinterest, a series of operations are initiated. These operations include adding the Pin to a user’s board, potentially notifying other users, processing the associated image, and updating analytics. Not all of these tasks necessitate instantaneous completion; some can tolerate delays of several seconds or even minutes without impacting user experience.
This is the fundamental principle of asynchronous job processing. When a user initiates a save action, Pinterest provides immediate confirmation, while the underlying work is appended to a queue for subsequent processing. This methodology ensures a responsive user interface while guaranteeing the eventual completion of all required tasks. The diagram below illustrates a high-level asynchronous processing approach:
The robustness of the job queue system relies on its ability to reliably store these tasks, efficiently distribute them to worker machines for execution, and gracefully manage failures. At Pinterest’s operational scale, this entails overseeing billions of jobs traversing the system daily.
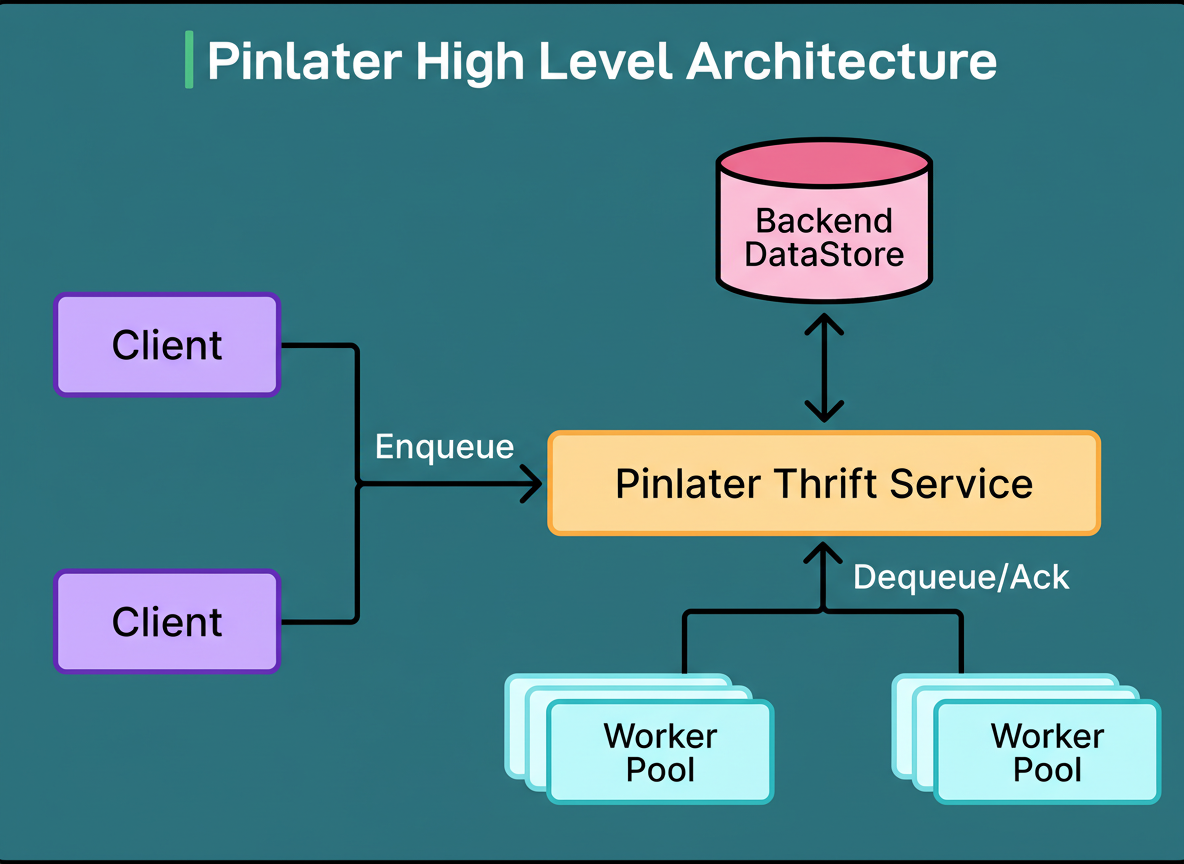
The Pinlater architecture developed by the Pinterest engineering team comprised three primary components.
A stateless Thrift service served as the entry point, responsible for accepting job submissions and orchestrating their retrieval.
A backend datastore, inferred to be MySQL-based, ensured the persistence of all job data.
Worker pools continuously retrieved jobs from the system, executed them, and reported their success or failure status.
The diagram below illustrates this architecture:
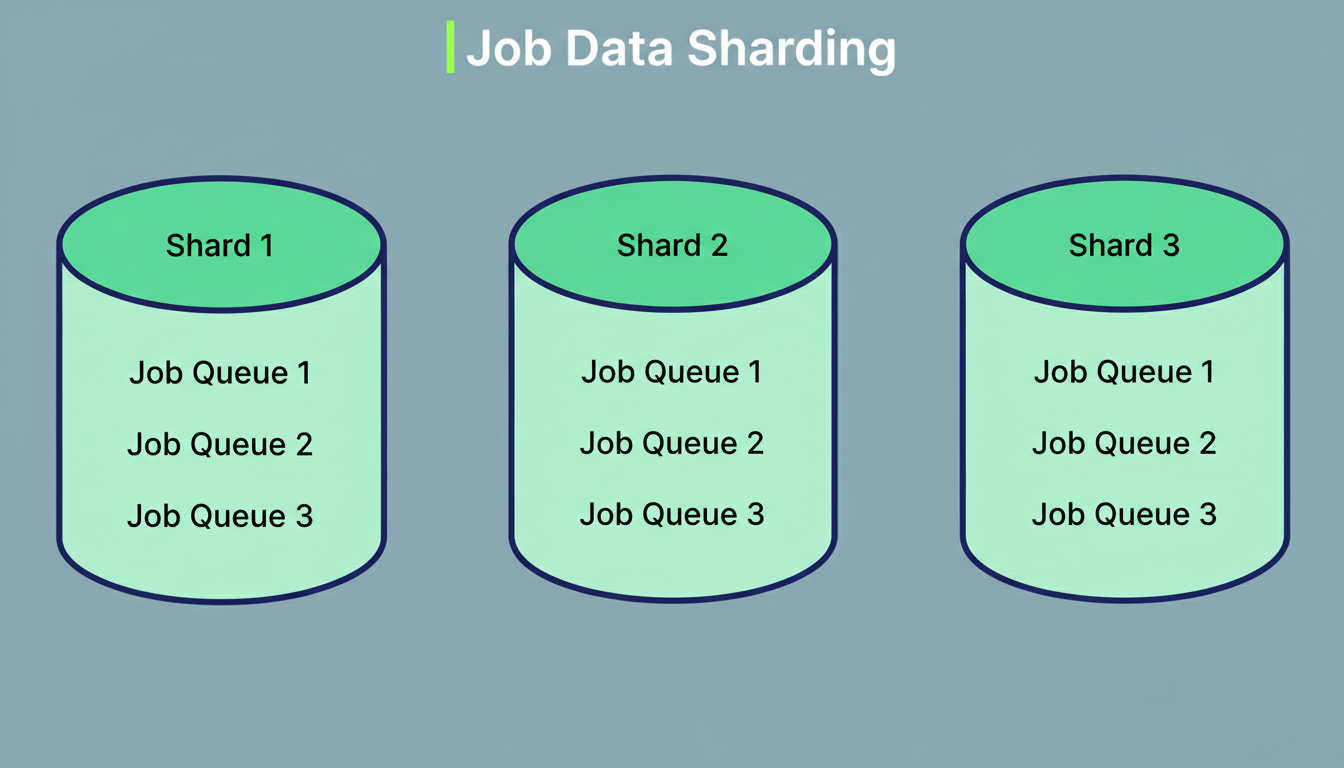
While this architecture initially performed effectively, several challenges arose as Pinterest’s traffic escalated. The most critical problem identified was database lock contention. Pinterest had implemented database sharding across multiple servers to manage the increasing data volume. However, upon the creation of a new job queue, Pinlater established a partition for that queue within every database shard. Consequently, a system with ten database shards would see each queue possessing ten partitions distributed across them.
When worker processes required jobs for execution, the Thrift service was compelled to concurrently scan all shards due to its lack of prior knowledge regarding which shards contained ready jobs. This scanning operation was performed by multiple Thrift servers operating in parallel to accommodate Pinterest’s substantial request volume. The outcome was dozens of threads originating from various Thrift servers simultaneously attempting to read from the same database partitions.
Databases manage concurrent access through the use of locks. When multiple threads endeavor to read identical data, the database orchestrates this access to avert data corruption. One thread acquires the lock and proceeds, while others await their turn. At Pinterest’s operational scale, the database expended more resources on managing these locks and coordinating access than on the actual retrieval of data. As Pinterest expanded the number of Thrift servers to handle growing traffic, the severity of lock contention intensified. This highlights a critical aspect of capacity planning for distributed systems.
A second significant issue was the complete absence of isolation among different job queues. Multiple queues, characterized by vastly different operational profiles, operated on the same worker machines. For instance, a queue dedicated to CPU-intensive image transformations shared computational resources with a queue responsible for transmitting simple notification emails. Should a bug in one queue cause a worker process to crash, it would consequently disrupt all other queues running on that particular machine. This lack of isolation rendered performance tuning exceptionally difficult, as disparate workloads demanded distinct hardware configurations.
The third challenge stemmed from the highly varied reliability requirements of different system operations, all of which shared the same underlying infrastructure. Enqueueing jobs constituted a critical, user-facing workflow; failures in enqueue operations would be immediately apparent to users. Dequeue operations, conversely, primarily dictated the speed at which jobs were processed. A brief delay in dequeuing typically meant jobs took a few additional seconds to complete, which was generally deemed acceptable. Nevertheless, both types of operations competed for resources on the same Thrift servers, implying that less critical operations could adversely affect critical ones.
Finally, Pinlater’s approach to data partitioning across shards proved inefficient. Even small queues with minimal traffic were allocated partitions in every database shard. System metrics indicated that over 50% of all database queries yielded empty results, as they were scanning partitions devoid of data. Furthermore, the system was unable to support FIFO (First-In, First-Out) ordering across an entire queue because jobs were processed concurrently from multiple shards, precluding the maintenance of global ordering.
Instead of attempting to optimize the existing architecture, the Pinterest engineering team opted for a complete system rebuild. Pacer introduced several novel components and fundamentally altered the flow of data within the system.
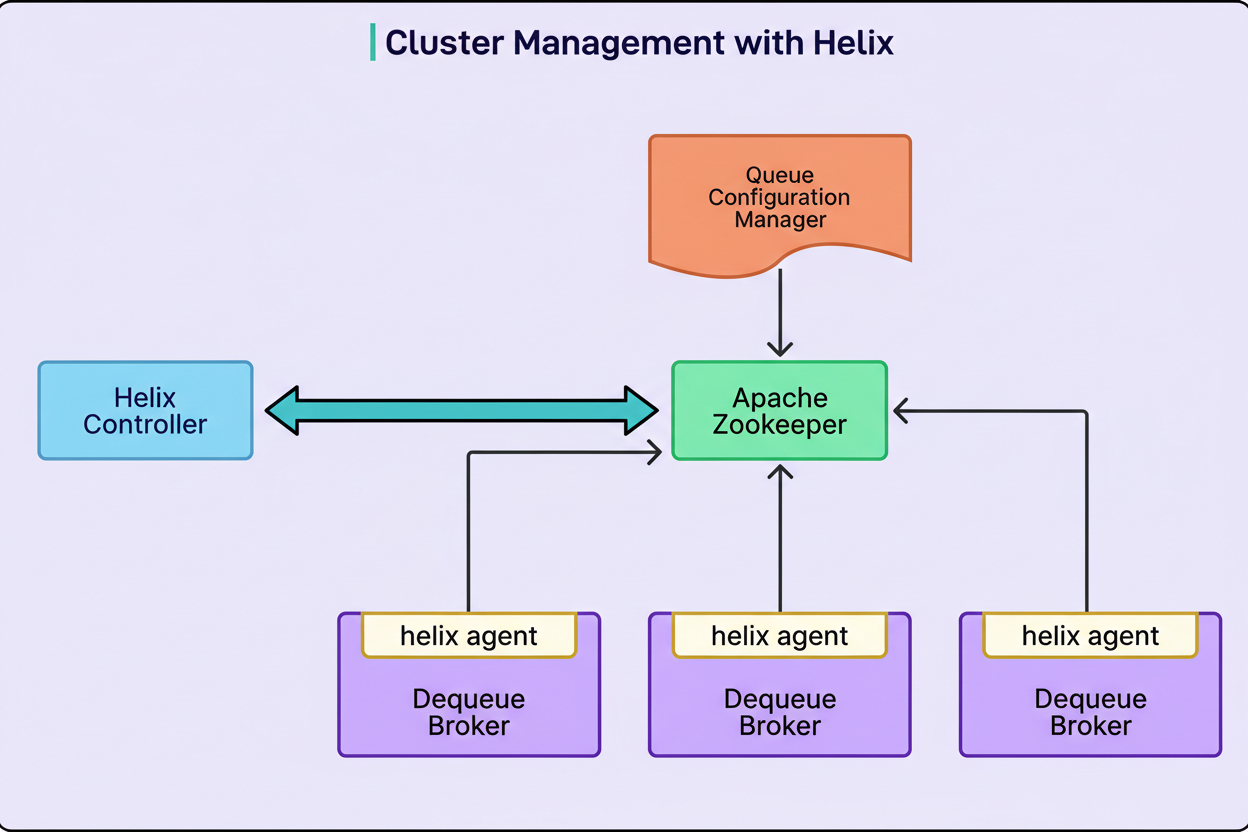
The most significant architectural modification was the integration of a dedicated dequeue broker service. This stateful service layer is positioned between the worker processes and the database, transforming the job retrieval mechanism. Rather than numerous Thrift servers concurrently competing to read from the database, each partition of every queue is exclusively assigned to a single dequeue broker instance. This assignment process is orchestrated by Helix, a cluster management framework integrated by Pinterest.
The diagram below illustrates this architectural change:
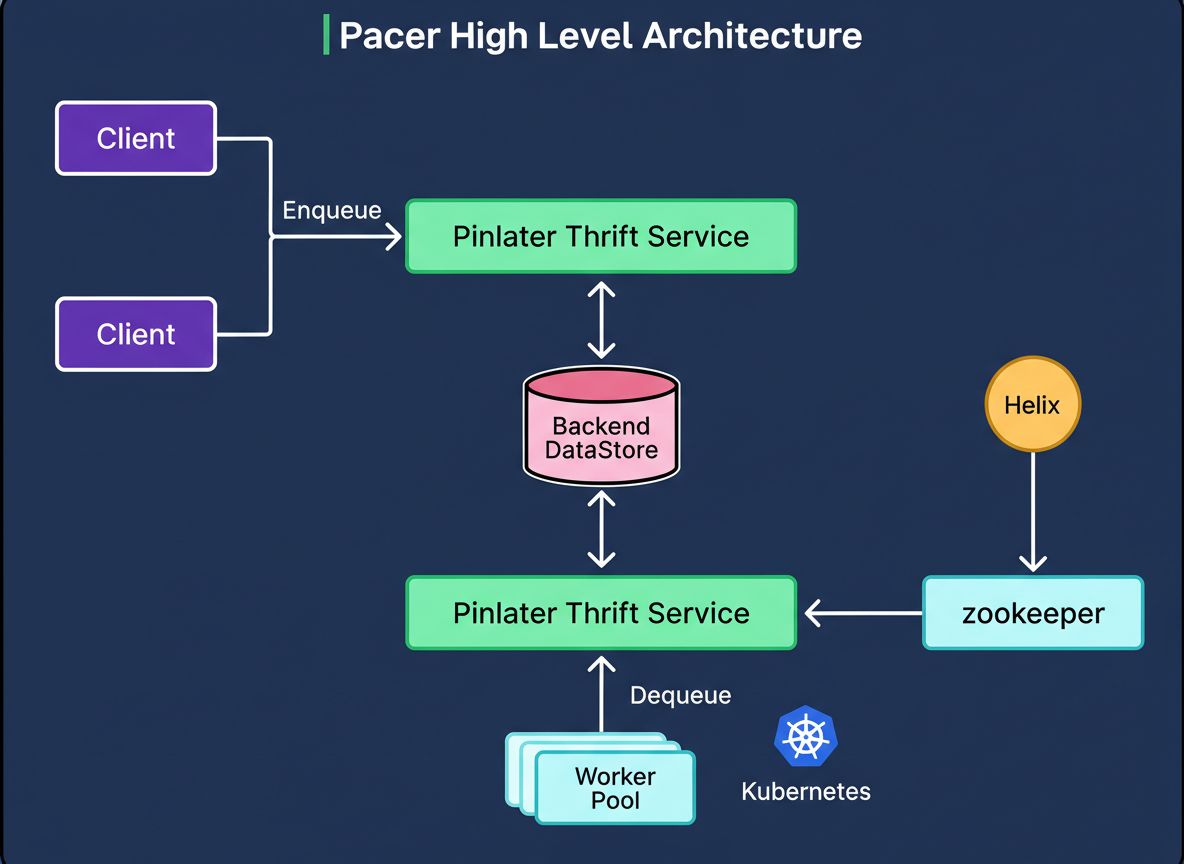
The assignment process functions as follows:
When a queue partition is created or modified, its configuration is stored within Zookeeper, a distributed coordination service.
The Helix controller continuously monitors Zookeeper to detect newly created or modified partitions.
Helix then calculates which dequeue broker should assume ownership of that specific partition, based on the current cluster state.
The determined assignment is subsequently written back to the Zookeeper instance.
The designated broker receives notification of its assignment and commences management of the associated partition.
In the event of a broker failure, Helix detects the issue and reassigns its partitions to healthy brokers, demonstrating a robust approach to chaos engineering principles in maintaining system resilience.
The diagram below further clarifies this process:
This assignment strategy effectively eliminates the problem of lock contention. Since only one broker ever accesses a particular partition, database-level competition is entirely removed.
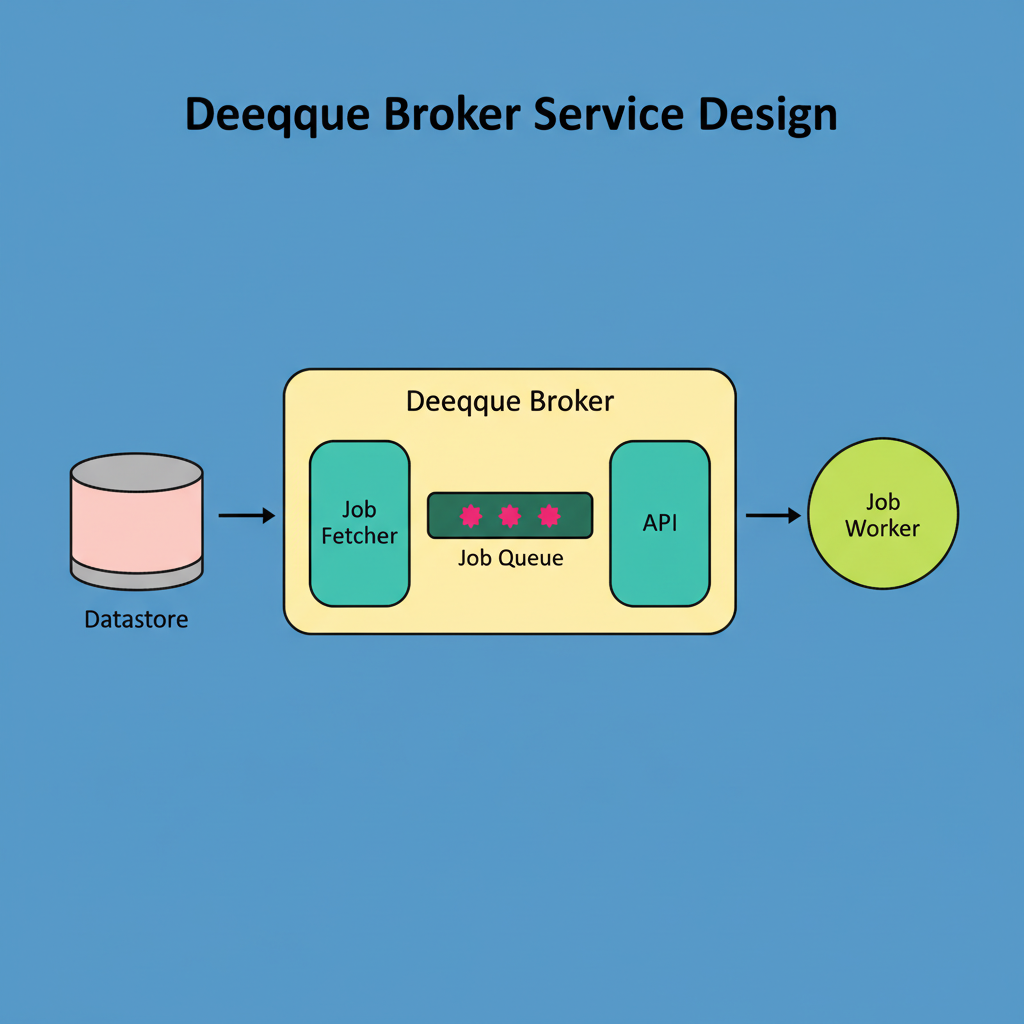
However, the dequeue broker’s functionality extends beyond merely resolving contention; it also significantly enhances performance through intelligent caching. Each broker proactively retrieves jobs from its assigned partitions and stores them within in-memory buffers. These buffers are implemented as thread-safe queues. When worker processes require jobs, they request them directly from the broker’s memory, bypassing direct database queries. Memory access is substantially faster than database queries, and Pinterest’s internal metrics confirm a reduction in dequeue latency to less than one millisecond.
The diagram below visually represents this caching mechanism:
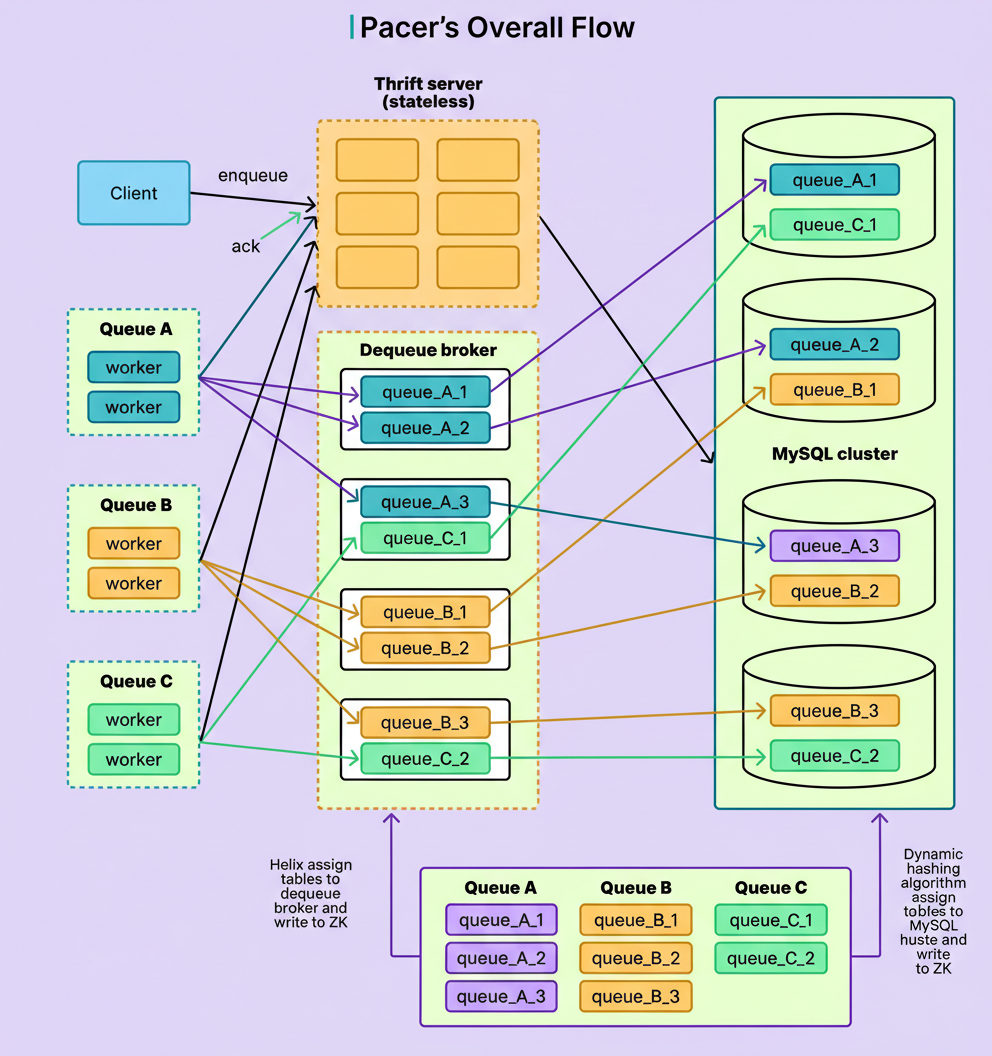
Pinterest also comprehensively redesigned the partitioning strategy for queues across database shards. While Pinlater assigned partitions in every shard to every queue, regardless of size or traffic, Pacer employs a more adaptive methodology.
Small queues with low traffic might receive only a single partition within a single shard.
Conversely, large, high-traffic queues are allocated multiple partitions distributed across shards according to their actual operational requirements.
This adaptive sharding mechanism successfully eliminated the resource wastage inherent in Pinlater, resulting in a reduction of empty query results from over 50% to nearly zero. This improved efficiency is crucial for overall system performance, especially when considering edge network requests per minute at peak times.
The diagram below illustrates this adaptive sharding approach:
 Source: Pinterest Engineering Blog
Source: Pinterest Engineering Blog
This flexible partitioning strategy also enabled the implementation of new functionalities. FIFO ordering, which was unachievable in Pinlater, became feasible with Pacer. A queue requiring strict processing order can now be configured with a single partition, thereby guaranteeing that jobs are processed precisely in the sequence they were submitted.
Furthermore, for job execution, the Pinterest engineering team transitioned from shared worker pools to dedicated pods running on Kubernetes. Each queue now operates within its own isolated worker environment, complete with customized resource allocations. For example, an image processing queue can be provisioned with high CPU and moderate memory, while a notification queue can utilize low CPU and memory but high concurrency settings. This isolation ensures that issues within one queue do not impact others, and each queue can be optimized for peak performance on hardware specifically matched to its unique demands. This level of granular control is vital for achieving high performance in a Google Cloud multi-region deployment or similar distributed environments.
The principle of separation of concerns also applies to the request path. In Pacer, the Thrift service is exclusively responsible for job submission. This critical, user-facing path is entirely isolated from dequeue operations. Consequently, even if dequeue brokers encounter problems, users can continue to submit jobs without experiencing immediate service disruptions. While job processing might be delayed, the submission process itself remains rapid and dependable.
The transition from Pinlater to Pacer yielded quantifiable enhancements across numerous operational aspects.
Database lock contention, a progressively worsening issue in the previous system, was entirely eliminated.
Hardware utilization efficiency markedly improved for both database servers and worker machines.
Job execution times were reduced, attributable to the isolated and customizable runtime environments.
The system now exhibits linear scalability, allowing for the addition of more brokers as partition counts rise, thereby overcoming the scalability limitations inherent in Pinlater.
From a system design standpoint, the Pacer architecture exemplifies several crucial principles.
Firstly, the introduction of specialized components can address multiple challenges concurrently. The dequeue broker, specifically implemented to resolve lock contention, also enhanced latency, facilitated superior caching, and enabled the isolation of the critical enqueue path.
Secondly, stateful services demonstrate their utility in distributed systems, notwithstanding the prevalent inclination towards stateless designs. The dequeue brokers are inherently stateful, as they maintain memory buffers and exhibit affinity to particular partitions. This statefulness, judiciously managed by Helix and Zookeeper, is integral to the architecture’s efficacy.
Thirdly, strategic caching at the appropriate layer can deliver substantial performance advantages. Instead of attempting caching at the database or Thrift service levels, Pinterest positioned the cache within the component directly responsible for serving jobs to workers.
Fourthly, isolation is paramount in preventing cascading failures and enabling optimization. By allocating dedicated resources to each queue, Pinterest successfully mitigated an entire category of cross-queue impact problems and rendered performance tuning a manageable endeavor.
Finally, it is evident that not all data necessitates identical partitioning schemes. Adaptive sharding, guided by actual usage patterns, proves more efficient than uniform, one-size-fits-all methodologies.
References: