
This week’s system design refresher covers various fundamental concepts including Transformers Step-by-Step Explained (Youtube video), Database Types essential for 2025, a comparison of Apache Kafka vs. RabbitMQ, an exploration of The HTTP Mindmap, and a detailed explanation of How DNS Works, alongside an inquiry into real-time updates from web servers.
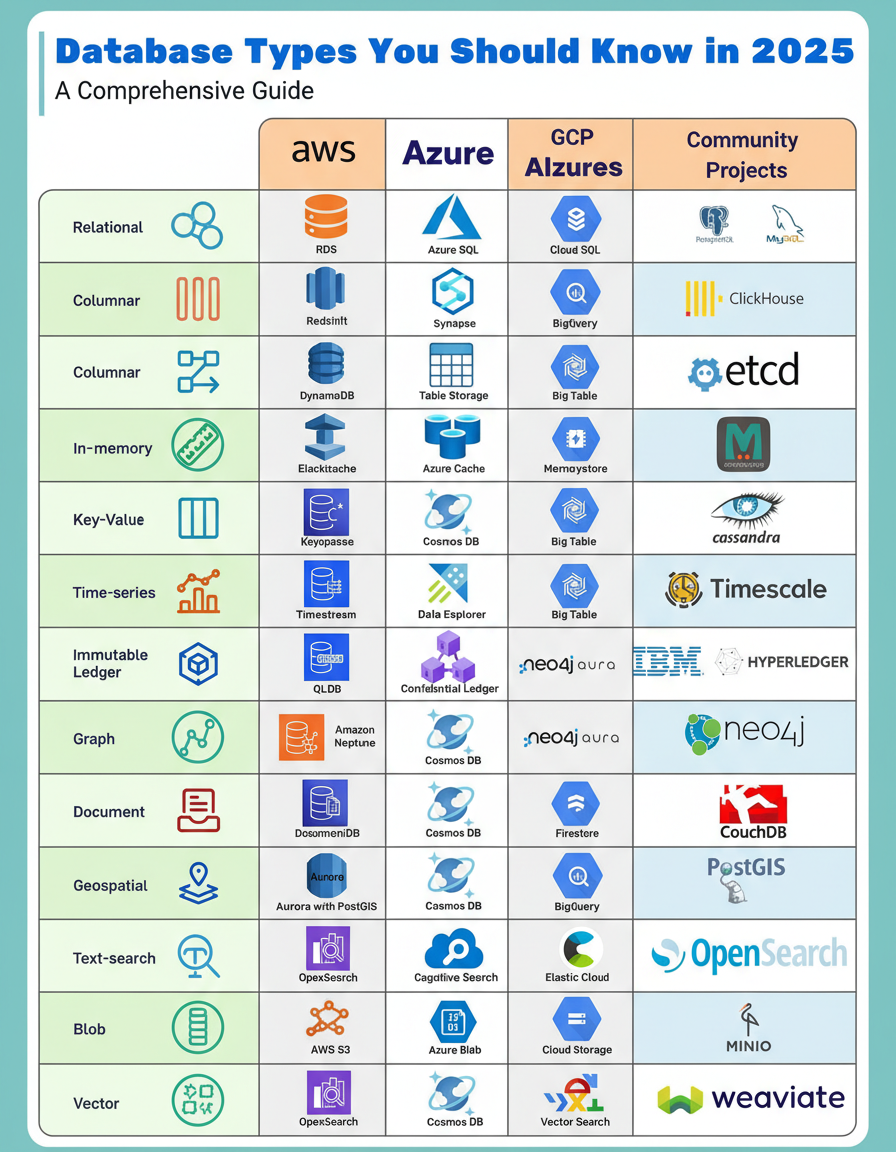
The concept of a universal database no longer applies to contemporary software development. Modern applications frequently leverage diverse database types, catering to needs ranging from real-time analytics to advanced vector search crucial for AI functionalities. A deep understanding of the appropriate database selection is paramount, as it directly influences a system’s overall performance and scalability.
Considering the evolving landscape of data storage, which database type is anticipated to experience the most significant growth over the next five years?
Both Apache Kafka and RabbitMQ are robust messaging systems; however, they address distinct challenges in distributed system architectures. A clear comprehension of their fundamental differences is crucial for effective system design.
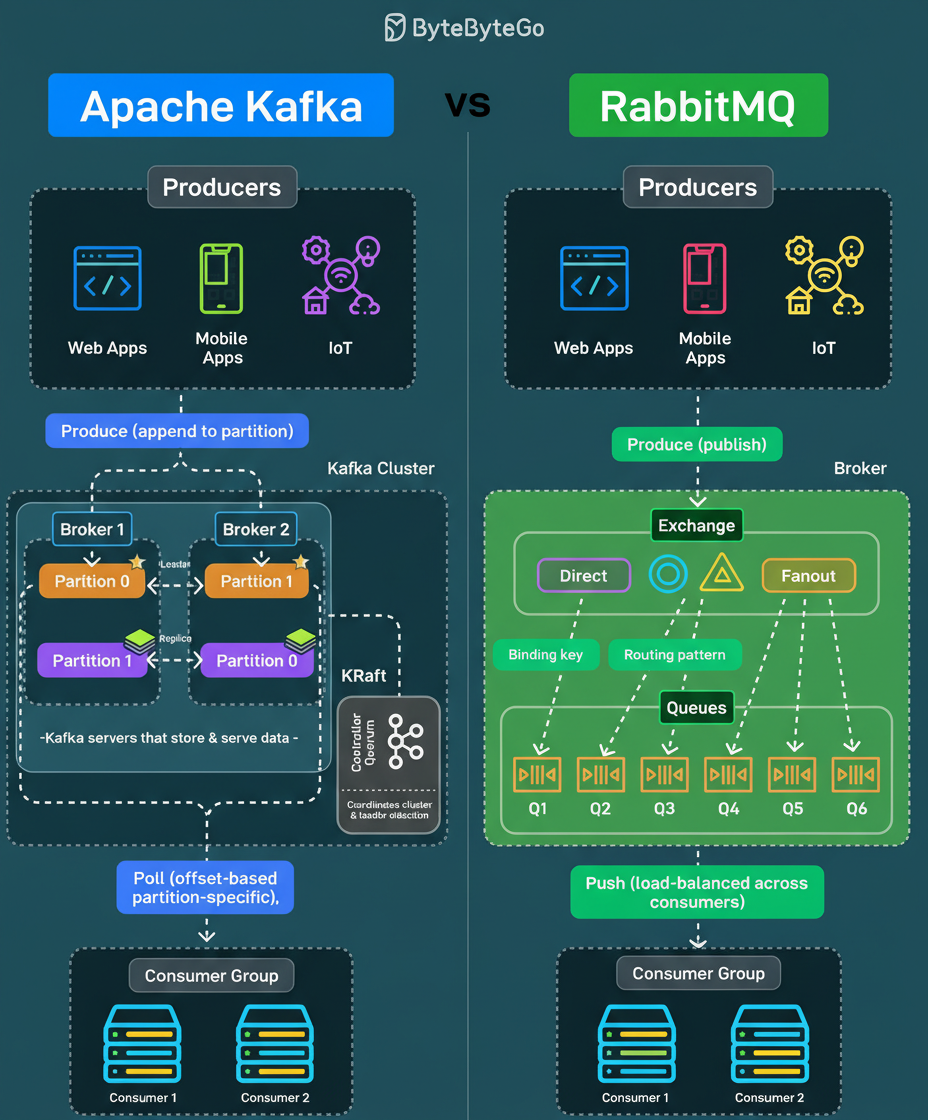
Kafka operates as a distributed commit log. Producers append messages to specific partitions, and these messages persist based on a defined retention policy, irrespective of consumer consumption status. Consumers retrieve messages at their own pace by utilizing offsets, enabling capabilities such as message rewinding, replaying, and reprocessing. It is architected for high-throughput event streaming scenarios where multiple independent consumers require access to the same data streams.
Conversely, RabbitMQ functions as a traditional message broker. Producers publish messages to exchanges, which subsequently route these messages to various queues based on predefined binding keys and patterns (e.g., direct, topic, fanout). Messages are actively pushed to consumers and are subsequently deleted upon acknowledgment. This system is primarily designed for efficient task distribution and conventional messaging workflows.
A frequent misconception involves deploying Kafka as a simple message queue or utilizing RabbitMQ as an event log. These platforms are distinct tools, each optimized for specific use cases and operational paradigms.
For those familiar with these technologies, a discussion on scenarios where Kafka might not be the optimal choice for messaging infrastructure is encouraged.
The Hypertext Transfer Protocol (HTTP) has undergone significant evolution, progressing from HTTP/1.1 to HTTP/2, and most recently to HTTP/3, which leverages the QUIC protocol over UDP for enhanced performance. Presently, HTTP serves as the foundational protocol for nearly all internet communications, encompassing web browsers, APIs, streaming services, cloud infrastructure, and AI systems.
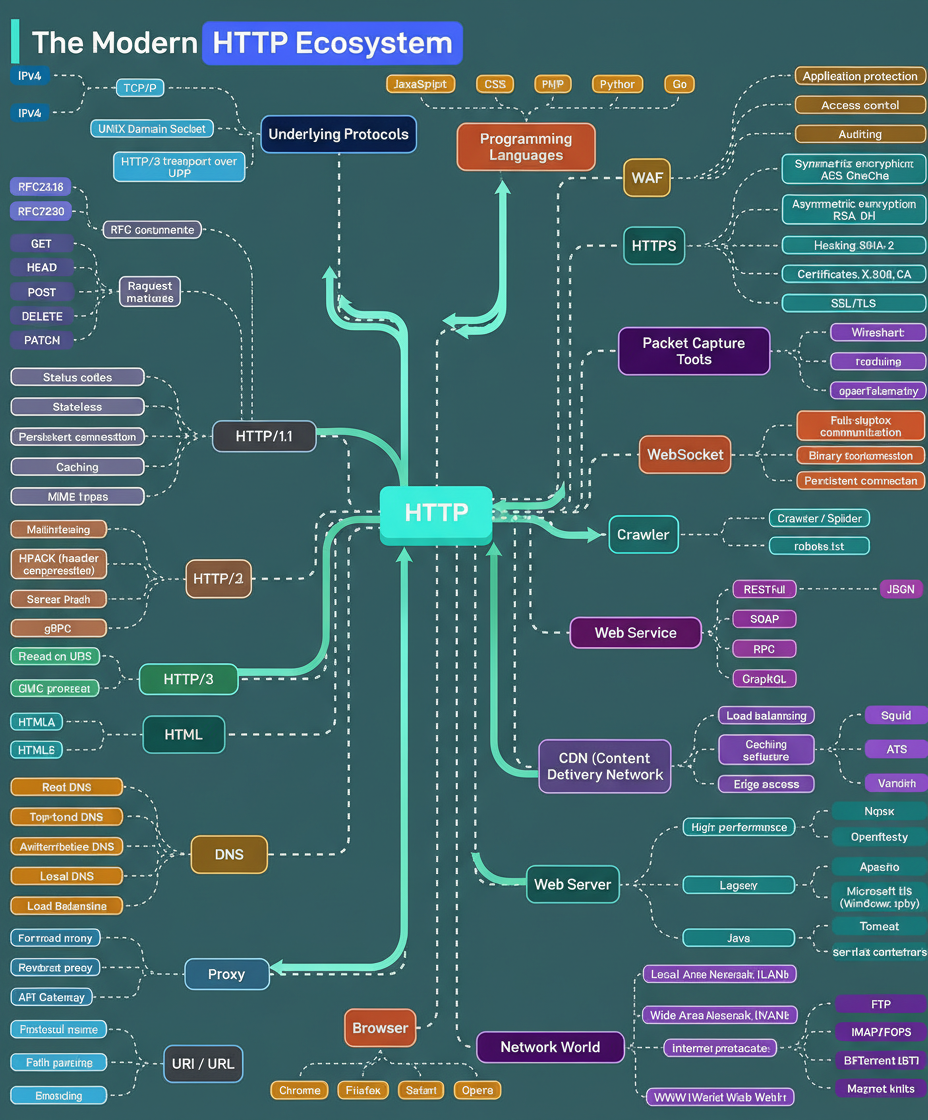
At its core, the architecture relies on underlying protocols such as TCP/IP for managing IPv4 and IPv6 traffic, and Unix domain sockets for efficient local communication. Notably, HTTP/3 operates over UDP rather than TCP, optimizing data transport prior to HTTP processing.
Security measures are integrated across the entire ecosystem. HTTPS has become an indispensable standard. WebSockets facilitate real-time connections. Web servers are responsible for managing computational workloads. Content Delivery Networks (CDNs) ensure global content distribution, while DNS resolvers translate domain names into IP addresses. Various proxies, including forward, reverse, and API gateways, are deployed to route, filter, and secure traffic flows.
Web services engage in data exchange using diverse formats, such as REST with JSON, SOAP for enterprise-grade systems, RPC for direct procedural calls, and GraphQL for flexible data querying. Web crawlers and bots index internet content, adhering to directives specified within robots.txt files that delineate access boundaries.
The broader network landscape interconnects these elements, involving Local Area Networks (LANs), Wide Area Networks (WANs), and protocols like FTP for file transfers, IMAP/POP3 for email management, and BitTorrent for peer-to-peer communication. For comprehensive observability, tools such as Wireshark, tcpdump, and OpenTelemetry enable developers to scrutinize network traffic, providing insights into performance, latency, and system behavior across the entire stack.
Considering HTTP’s continuous evolution over three decades, identifying the forthcoming major architectural shift presents an intriguing area of discussion.
When a user inputs a domain name and initiates a request, the underlying processes preceding webpage loading are more intricate than commonly perceived. The Domain Name System (DNS) functions as the internet’s directory, where each request triggers a sequence of lookups across multiple servers.
The process unfolds in a series of steps:
All these intricate operations are completed within milliseconds, even before the initial page content begins to load.
Regarding DNS troubleshooting and diagnostics, which specific tools or commands, such as dig, nslookup, or others, are most frequently utilized by technical professionals?
An HTTP server, by its fundamental nature, cannot automatically initiate a connection to a client’s web browser. Consequently, the web browser always acts as the initiator in HTTP communication. The challenge then becomes how to receive real-time updates from the HTTP server efficiently.
Both the web browser and the HTTP server can contribute to achieving real-time updates through different architectural patterns.
Client-side approaches typically involve the web browser performing the primary effort, utilizing techniques such as short polling or long polling. In short polling, the browser repeatedly sends requests at intervals until it retrieves the most current data. Conversely, with long polling, the HTTP server holds the request open and only responds once new data becomes available.
Collaborative solutions, where both the HTTP server and web browser interact more dynamically, include WebSocket or Server-Sent Events (SSE). In both scenarios, after an initial connection is established, the HTTP server can directly transmit the latest data to the browser. The key distinction lies in their directionality: SSE is uni-directional, allowing the server to push updates to the browser without the browser sending new requests, whereas WebSocket provides a fully-duplex communication channel, enabling continuous bi-directional exchange of data.
Among the four discussed solutions (long polling, short polling, SSE, and WebSocket), an analysis of their common usage patterns and specific application use cases is valuable for architectural considerations.