
When users interact with the Uber application for services like requesting a ride, checking trip history, or viewing driver details, an expectation of immediate results prevails. This smooth user experience is supported by a sophisticated caching infrastructure. Uber’s CacheFront system adeptly handles over 150 million database reads per second while rigorously maintaining strong consistency guarantees.
This article dissects the construction of this system by Uber, the challenges encountered during its development, and the innovative solutions that were engineered to overcome them.
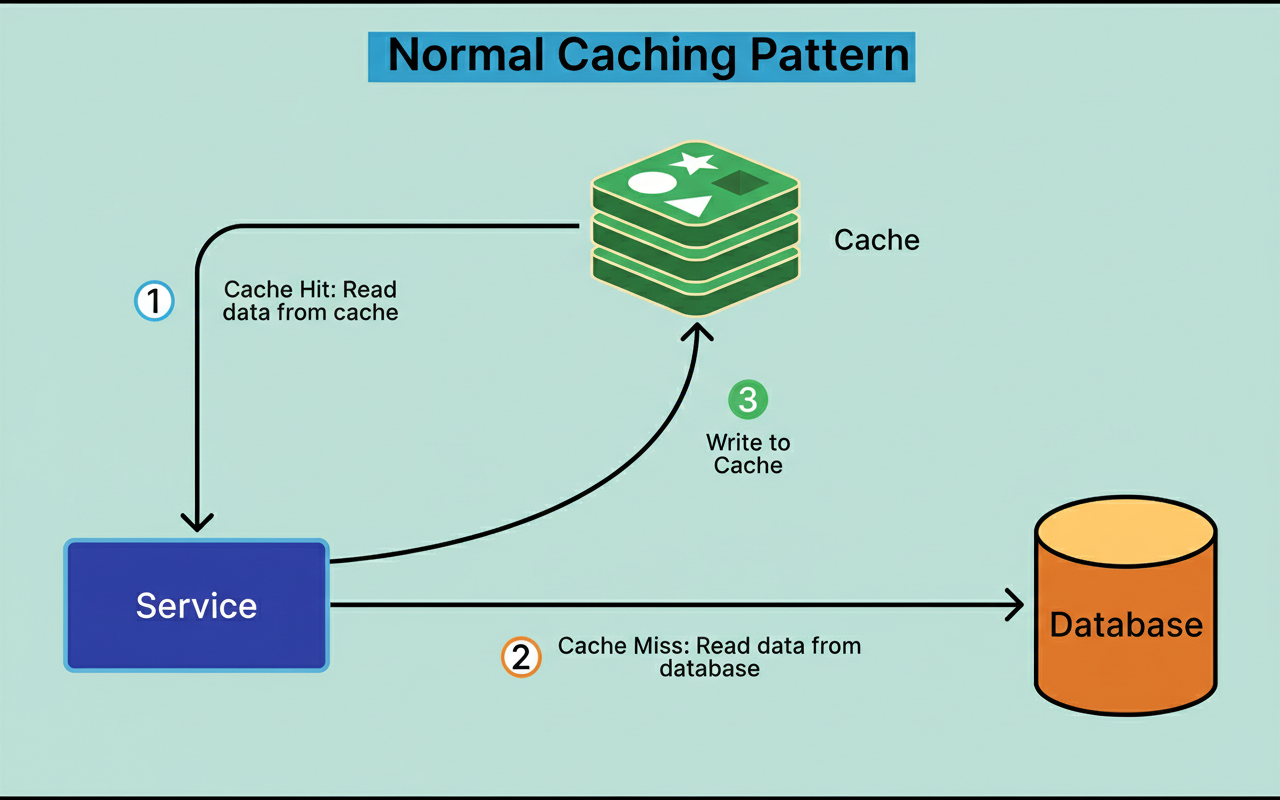
Each time a user engages with Uber’s platform, the underlying system must retrieve various data points, including user profiles, trip specifics, driver locations, and pricing information. Direct data retrieval from a database for every single request introduces significant latency and imposes an immense burden on database servers. When millions of users generate billions of requests daily, conventional database systems struggle to keep pace, highlighting the critical need for robust capacity planning.
Caching addresses this issue by storing frequently accessed data within a faster storage mechanism. Rather than querying the database for every request, applications initially consult the cache. If the required data is present (a cache hit), it is returned instantaneously. Conversely, if the data is absent (a cache miss), the system queries the database and subsequently stores the result in the cache for future access.
See the diagram below:
Uber utilizes Redis, an in-memory data store, as its primary caching solution. Redis is capable of serving data in microseconds, a stark contrast to the milliseconds typically required for direct database queries.
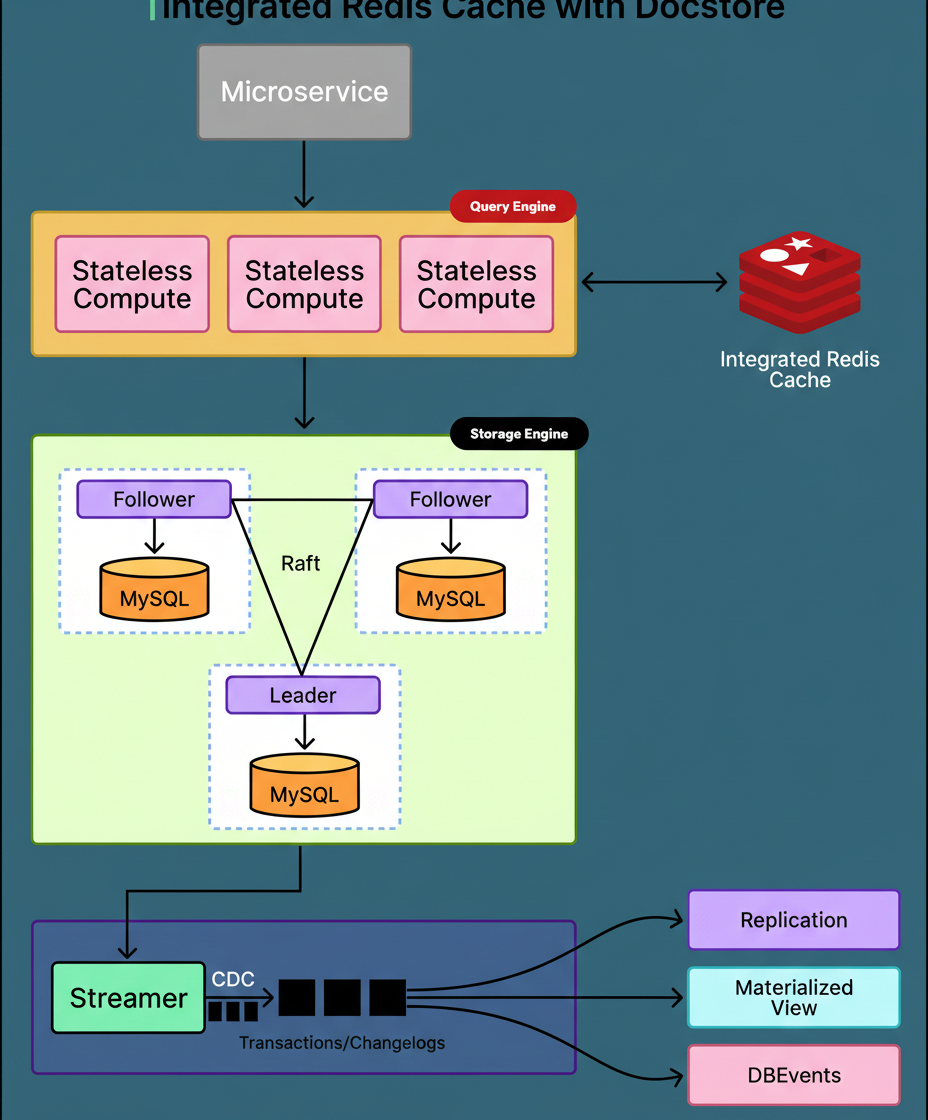
Uber’s core storage system, known as Docstore, is composed of three primary architectural components.
The Query Engine layer operates as a stateless component, responsible for processing all inbound requests originating from various Uber services.
The Storage Engine layer is where data persistently resides, leveraging MySQL databases structured across multiple nodes.
CacheFront represents the caching logic, meticulously integrated within the Query Engine layer, strategically positioned between application requests and the underlying database infrastructure.
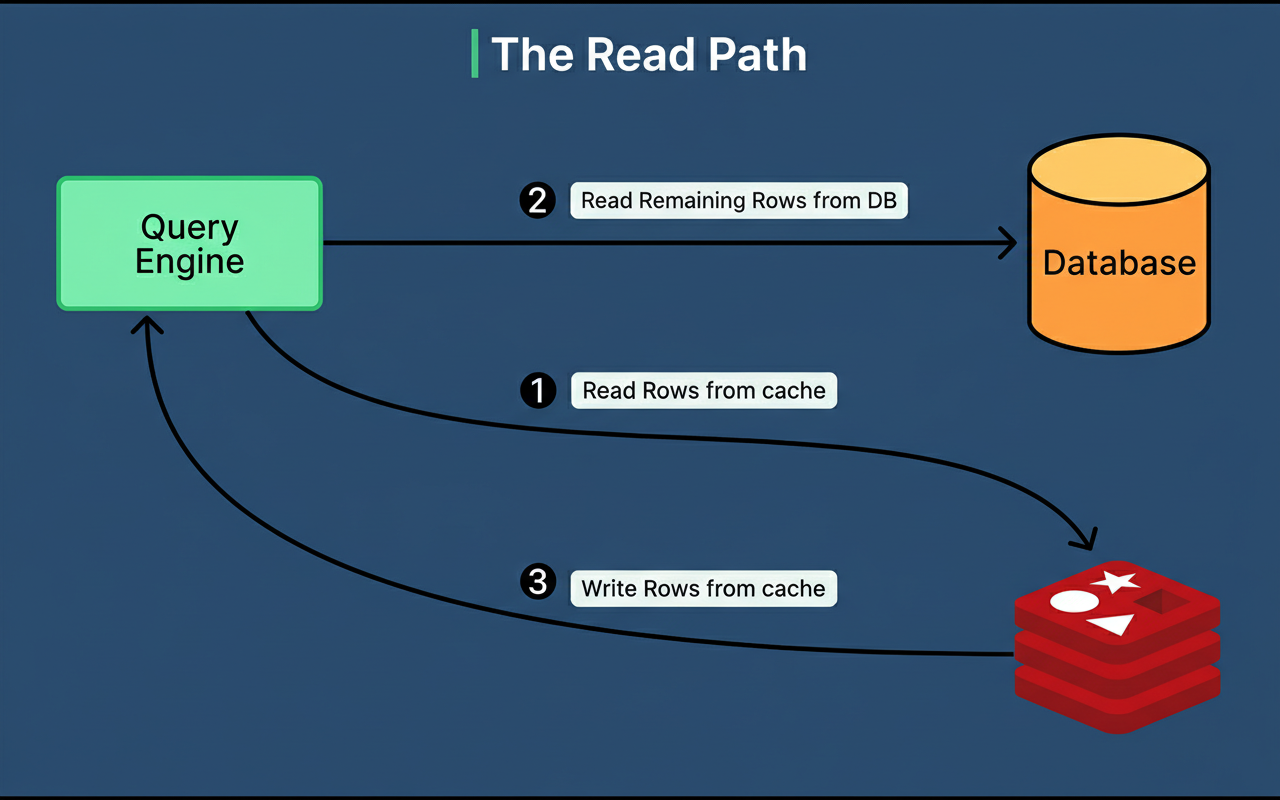
Upon the arrival of a read request, CacheFront first queries Redis. If the data is present in Redis, it is immediately returned to the client. For numerous operational scenarios, Uber achieves cache hit rates exceeding 99.9%, indicating that only a minimal fraction of edge network requests per minute necessitate database interaction.
Should the data not be found in Redis, CacheFront retrieves it from MySQL, then writes it to Redis, and finally returns the outcome to the client. The system is also equipped to manage partial cache misses effectively. For instance, if a request seeks ten rows and seven are already in the cache, only the three missing rows are fetched from the database.
Write operations inherently introduce considerable complexity to any caching system. When data undergoes modification within the database, the corresponding cached copies of that data become stale. Serving outdated data can disrupt application logic and lead to unsatisfactory user experiences. For example, if a user updates their destination in the Uber application, but the system continues to display the old destination due to reading from an obsolete cache entry, it results in a poor experience.
The primary challenge in refreshing the cache lies in accurately identifying which cache entries require invalidation following a write operation. Uber accommodates two distinct categories of write operations, each demanding a specialized approach.
Point writes are relatively straightforward. These encompass INSERT, UPDATE, or DELETE queries where the exact rows being altered are explicitly identified within the query itself. An example would be updating a specific user’s profile based on their unique user ID. With point writes, the precise cache entries for invalidation are known because the row keys are integral to the query.
Conditional updates present a significantly greater level of complexity. These involve UPDATE or DELETE queries incorporating WHERE clauses that filter based on specific conditions. An illustration would be marking all trips exceeding 60 minutes as completed. Prior to the query’s execution, the system lacks knowledge of which specific rows will satisfy the condition, thus preventing the invalidation of affected cache entries.
This inherent uncertainty initially precluded Uber from performing synchronous cache invalidation during write operations. Consequently, reliance on alternative mechanisms became necessary.
Uber’s initial strategy involved a system named Flux, which implemented Change Data Capture (CDC).
Flux continuously monitors the MySQL binary logs, which meticulously record every modification made to the database. When a write operation is committed, MySQL writes this change to its binlog. Flux then tails these logs, identifies the modified rows, and subsequently invalidates or updates the corresponding entries within Redis. See the diagram below:
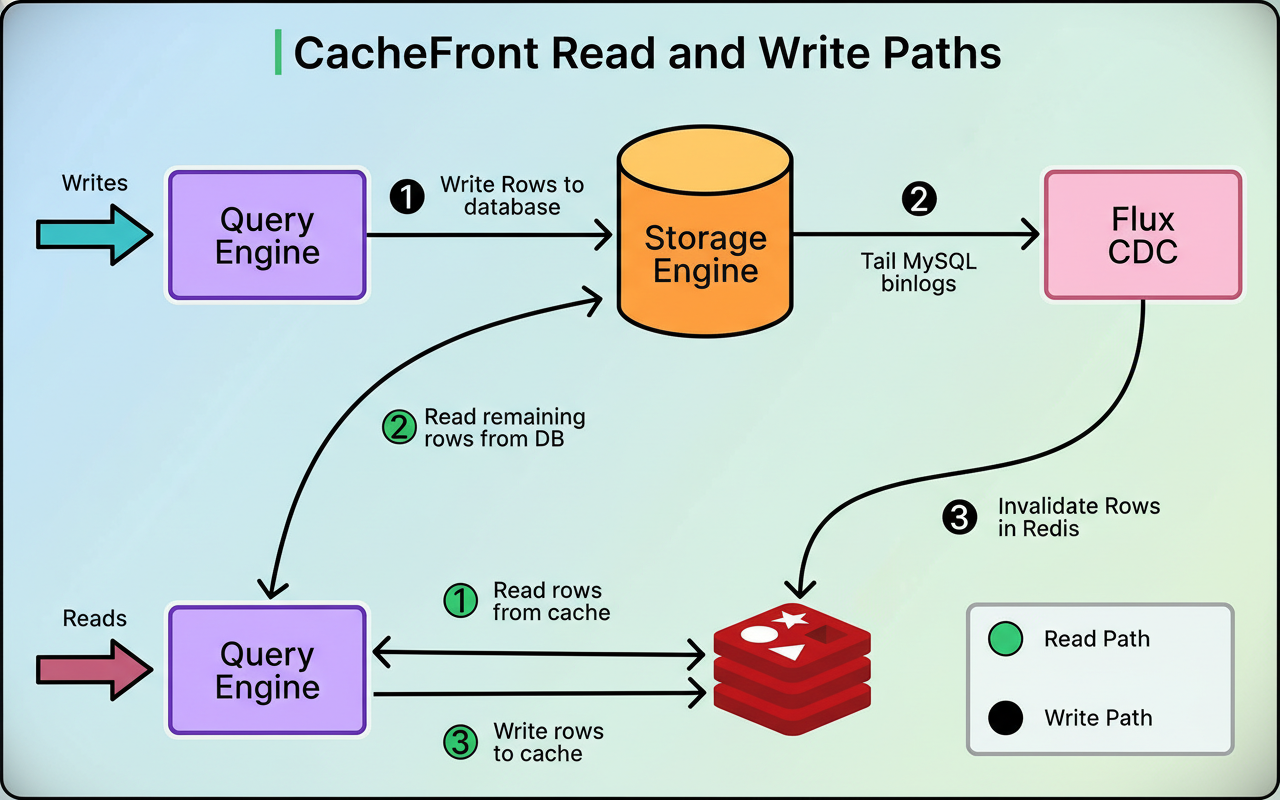
While this methodology was functional, it possessed a critical limitation. Flux operates asynchronously, meaning a delay exists between when data is altered in the database and when the cache is ultimately updated. This delay is typically sub-second but can extend during system restarts, deployments, or in scenarios involving topology changes. Such scenarios underscore the importance of strategies like chaos engineering to understand system behavior under stress.
This asynchronous characteristic introduces consistency issues. If a user performs a data write and immediately attempts to read it back, an older cached value might be returned because Flux has not yet processed the invalidation. This violates the expectation of read-your-own-writes consistency, a fundamental requirement for most applications.
The system also relied on Time-To-Live (TTL) expiration. Each cache entry is assigned a TTL, which dictates its duration in the cache before expiration. Uber’s standard recommendation is 5 minutes, although this duration can be adjusted based on specific application needs. TTL expiration serves as a crucial backstop, ensuring that even if invalidations fail, stale data will eventually be purged from the cache.
However, TTL-based expiration alone proved insufficient for many use cases. Service owners, aiming for higher cache hit rates, often sought to increase TTL values. Nevertheless, longer TTLs imply that data remains cached for extended periods, improving hit rates but simultaneously expanding the window during which stale data could potentially be served.
As CacheFront underwent significant scaling, three primary sources of inconsistency became apparent.
Cache invalidation delays, primarily attributed to Flux, led to read-your-own-writes violations where a write immediately followed by a read could retrieve outdated data.
Cache invalidation failures occurred when Redis nodes experienced temporary unresponsiveness, resulting in stale entries persisting until their TTL expiration.
Lastly, cache refills originating from lagging MySQL follower nodes had the potential to introduce outdated data if the follower had not yet replicated recent write operations from the leader, a challenge common in Google Cloud multi-region or similar distributed database setups.
A more nuanced consistency problem existed concerning the potential age of stale cached data. Most engineers typically assume that setting a TTL of 5 minutes guarantees stale data will not persist for more than 5 minutes. This assumption, however, is often incorrect.
Consider the following scenario:
A particular row was written to the database one year ago and has remained unaccessed since that time.
At a specific point in time, T, a read request is initiated. The cache does not contain this row, prompting its retrieval from the database and subsequent caching. The newly cached entry now holds data that is one year old.
Moments later, a write request updates this very row in the database. Flux attempts to invalidate the corresponding cache entry, but this invalidation fails due to a temporary issue with Redis. Consequently, the cache still retains the one-year-old value, while the database now holds the most current information.
For the subsequent hour, assuming a one-hour TTL, every read request will consistently return the one-year-old cached data.
In essence, the duration of staleness is not strictly bounded by the TTL period. Even with a TTL of only 1 hour, the application could potentially be serving data that is genuinely one year out of date. The TTL solely governs the lifespan of the cache entry itself, not the inherent age of the data contained within it.
This issue escalates in severity with longer TTL configurations. Service owners, seeking enhanced cache hit rates, would often extend TTLs to 24 hours or even longer. If an invalidation were to fail in such circumstances, extremely outdated data could be served for the entirety of that extended duration.
The fundamental obstacle preventing synchronous cache invalidation was the inability to ascertain precisely which rows were modified during conditional update operations.
Uber implemented two pivotal modifications to its storage engine to resolve this issue:
Firstly, all delete operations were re-engineered into soft deletes, which involves setting a tombstone flag rather than physically removing rows.
Secondly, strictly monotonic timestamps, accurate to microsecond precision, were introduced, ensuring that each transaction is uniquely identifiable.
With these foundational guarantees in place, the system is now capable of precisely identifying modified rows. When rows are updated, their timestamp column is assigned the unique timestamp of the transaction. Immediately prior to committing, the system executes a lightweight query to select all row keys that were modified within that transaction’s specific timestamp window. This query is exceptionally fast because the relevant data is typically already cached within MySQL’s storage engine, and the timestamp column benefits from indexing.
Armed with the capability to track all modified rows, Uber undertook a complete redesign of the write path.
When a write request arrives at the Query Engine, it registers a callback function that is executed once the storage engine responds. This response includes the success status of the operation, the set of affected row keys, and the commit timestamp of the transaction.
The callback then utilizes this comprehensive information to invalidate corresponding cache entries in Redis. This invalidation can be performed synchronously (within the request context, which introduces some latency but delivers the strongest consistency guarantees) or asynchronously (queued to execute outside the immediate request context, thereby avoiding latency but offering slightly weaker consistency assurances).
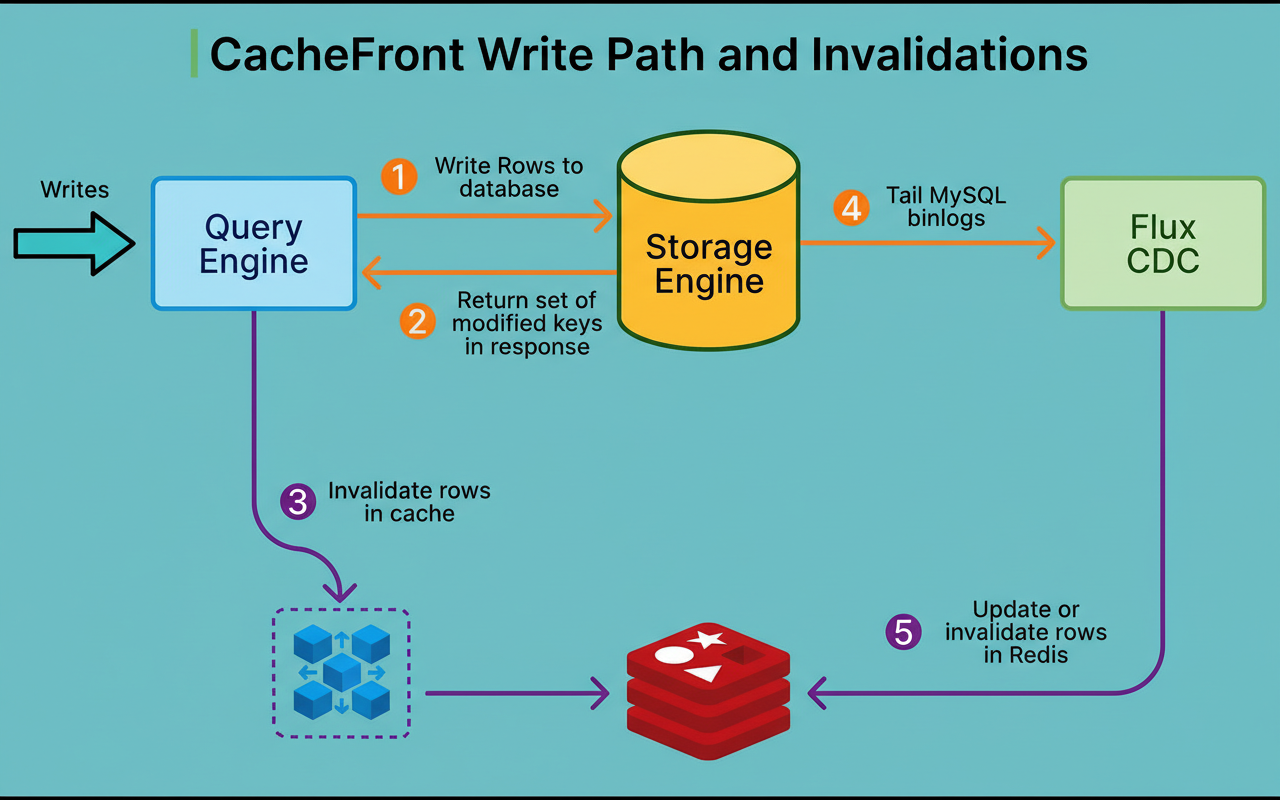
Crucially, even if the cache invalidation process encounters a failure, the write request itself proceeds successfully. The system is designed not to fail write operations due to cache-related issues, thereby upholding essential availability.
Uber now employs a comprehensive triple defense strategy for maintaining cache consistency.
TTL expiration automatically removes entries after their configured lifespan, with a default setting of 5 minutes.
Flux operates in the background, continuously monitoring MySQL binlogs and asynchronously invalidating cache entries as changes are detected.
Finally, the newly implemented write-path invalidation mechanism ensures immediate, synchronous cache updates precisely when data undergoes modification.
The synergy of these three independent systems working in concert has proven substantially more effective than relying on any single approach in isolation.
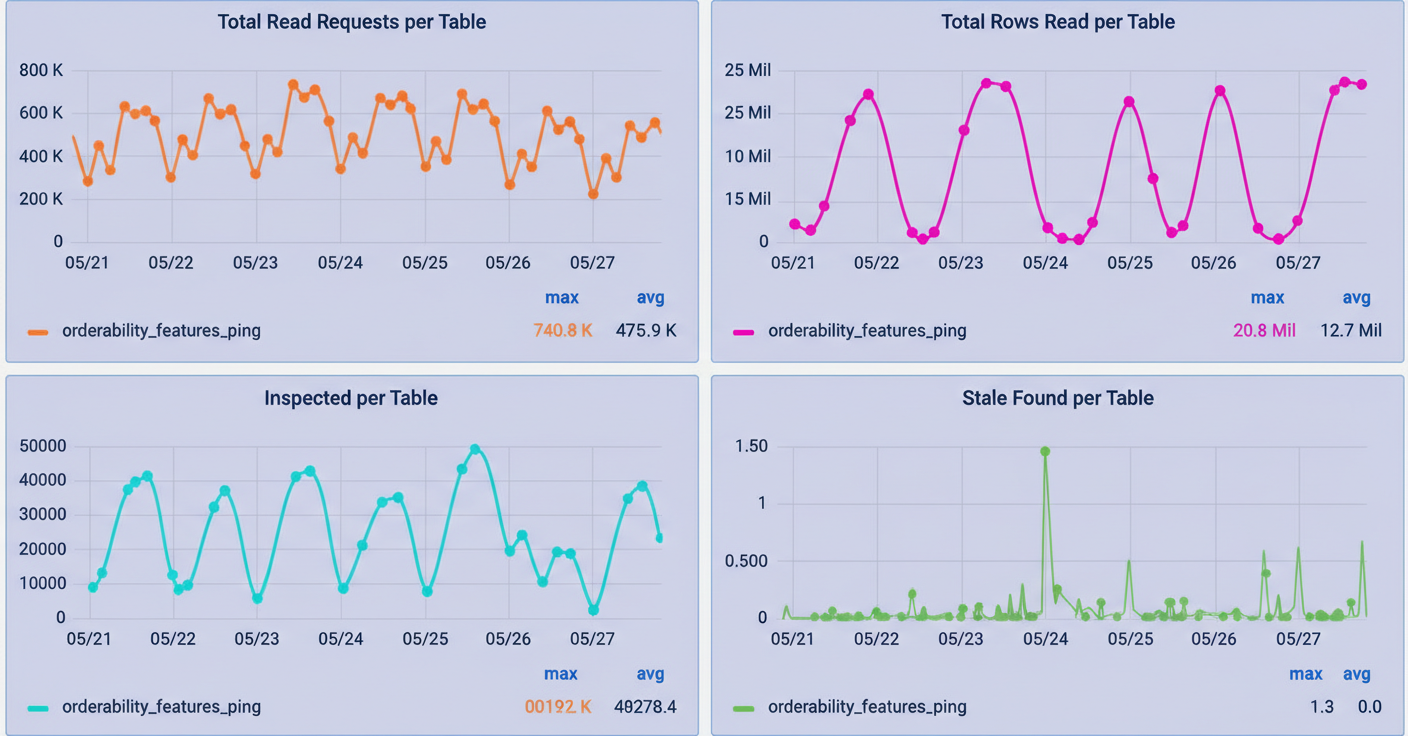
To rigorously validate improvements and accurately quantify cache consistency, Uber developed Cache Inspector. This tool leverages the same CDC pipeline as Flux, but incorporates a one-minute delay. Instead of invalidating the cache, it compares binlog events against the data stored in Redis, diligently tracking metrics such as the number of stale entries discovered and their respective durations of staleness.
The results garnered were highly encouraging. For tables configured with 24-hour TTLs, Cache Inspector recorded virtually zero stale values over periods spanning several weeks, all while maintaining cache hit rates exceeding 99.9%. This advanced measurement capability empowered Uber to confidently increase TTL values for appropriate use cases, leading to a dramatic improvement in performance without compromising consistency. This capability is paramount for Black Friday Cyber Monday scale testing and similar peak traffic events.
 Source: Uber Engineering Blog
Source: Uber Engineering Blog
Beyond the core invalidation enhancements, Uber also implemented a multitude of additional optimizations. These include adaptive timeouts that dynamically adjust based on system load, negative caching for non-existent data, pipelined reads to batch multiple requests, circuit breakers to isolate unhealthy nodes, connection rate limiters, and data compression techniques to reduce both memory footprint and bandwidth consumption.
Presently, CacheFront efficiently serves over 150 million rows per second during peak operational hours. For many critical use cases, cache hit rates consistently surpass 99.9%. The system has successfully scaled by nearly four times its original implementation capacity, while simultaneously strengthening its consistency guarantees.
By effectively resolving the complex cache invalidation problem through synchronous invalidation within the write path, complemented by asynchronous CDC and TTL-based expiration, Uber has achieved a robust combination of strong consistency and high performance at an unprecedented scale.