
When users open X (formerly Twitter) and scroll through the “For You” tab, a recommendation system determines which posts to display and in what sequence. This recommendation system operates in real-time. In the realm of social media, low latency is critical, as any performance issues can lead to user dissatisfaction. Previously, the internal mechanisms of this recommendation system remained largely undisclosed. Recently, however, the xAI engineering team open-sourced the algorithm driving this feed, releasing it on GitHub under an Apache-2.0 license. This revelation showcases a system constructed around a Grok-based transformer model, which has largely supplanted hand-crafted rules with advanced machine learning techniques. This article examines the algorithm’s functionality, the interplay of its components, and the rationale behind the xAI Engineering Team’s design decisions.
When a user requests the For You feed in X, the algorithm retrieves content from two distinct sources.
The initial source consists of in-network content, which includes posts from accounts the user already follows. For instance, if a user follows 200 individuals, the system evaluates recent posts from those accounts as potential candidates for the user’s feed.
The secondary source comprises out-of-network content, which refers to posts from accounts the user does not follow. The algorithm identifies these posts by searching a global repository using a machine learning technique known as similarity search. The underlying principle is that if a user’s past engagement indicates interest in a particular post, it becomes a candidate even if the author is unfamiliar.
These two sets of candidates are subsequently consolidated into a single list, subjected to scoring, filtering, and ranking. The highest-ranked posts are then presented to the user upon opening the application.
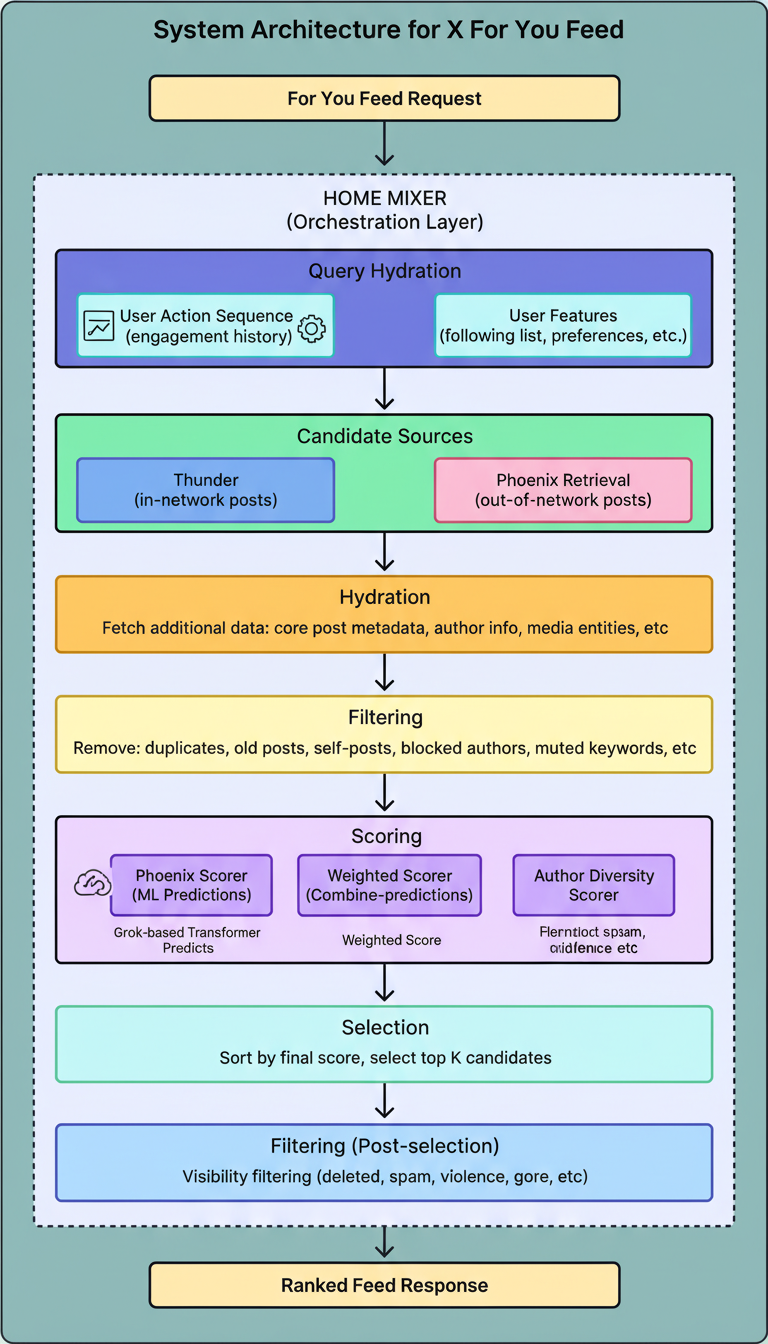
The diagram below illustrates the overall architecture of the system developed by the xAI engineering team:
(URL: https://substackcdn.com/image/fetch/$s_!14Oq!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F290026e6-5e0b-4a09-b202-45eb0b9a6f3b_2372x4150.png)
The codebase is structured into four primary directories, each corresponding to a unique segment of the system. The complete codebase is implemented in Rust (62.9%) and Python (37.1%).
Home Mixer functions as the orchestration layer, coordinating the sequential invocation of other components to assemble the final feed. Its role involves managing the pipeline rather than performing intensive machine learning computations.
Upon receiving a request, Home Mixer initiates several stages in sequence:
The server provides a gRPC endpoint, ScoredPostsService, which delivers the ranked list of posts for a specified user.
Thunder serves as an in-memory post store and a real-time ingestion pipeline. It processes post creation and deletion events from Kafka, maintaining distinct per-user stores for original posts, replies, reposts, and video posts.
When the algorithm requires in-network candidates, it queries Thunder. This component delivers results in sub-millisecond times due to its in-memory architecture, bypassing the need for an external database. Thunder also autonomously purges posts exceeding a configured retention period, ensuring the dataset remains current.
Phoenix functions as the machine learning core of the system, undertaking two primary responsibilities.
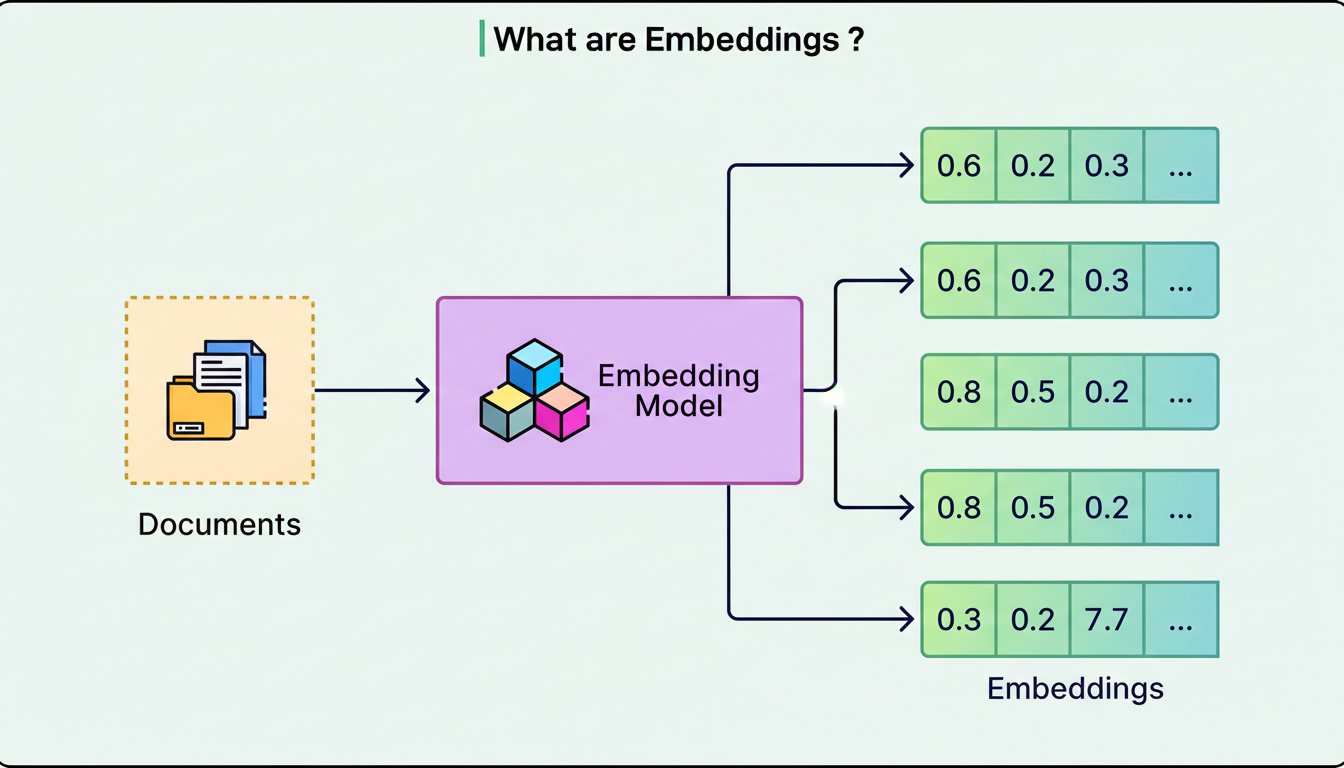
Phoenix employs a two-tower model to identify out-of-network posts. One tower, designated as the User Tower, processes a user’s features and engagement history, encoding them into a mathematical representation known as an embedding. The other tower, the Candidate Tower, encodes each post into its own embedding.
The identification of relevant posts then becomes a similarity search. The system calculates a dot product between the user’s embedding and each candidate embedding, subsequently retrieving the top-K most similar posts. For those unfamiliar with dot products, the fundamental concept is that two embeddings pointing in similar directions within a high-dimensional space yield a high score, indicating the post’s probable relevance to the user.
The diagram below illustrates the concept of embeddings:
 (URL: https://substackcdn.com/image/fetch/$s_!Y2uF!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffebf555a-fdee-42d5-96b8-67121e00d08e_3160x1786.png)
(URL: https://substackcdn.com/image/fetch/$s_!Y2uF!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffebf555a-fdee-42d5-96b8-67121e00d08e_3160x1786.png)
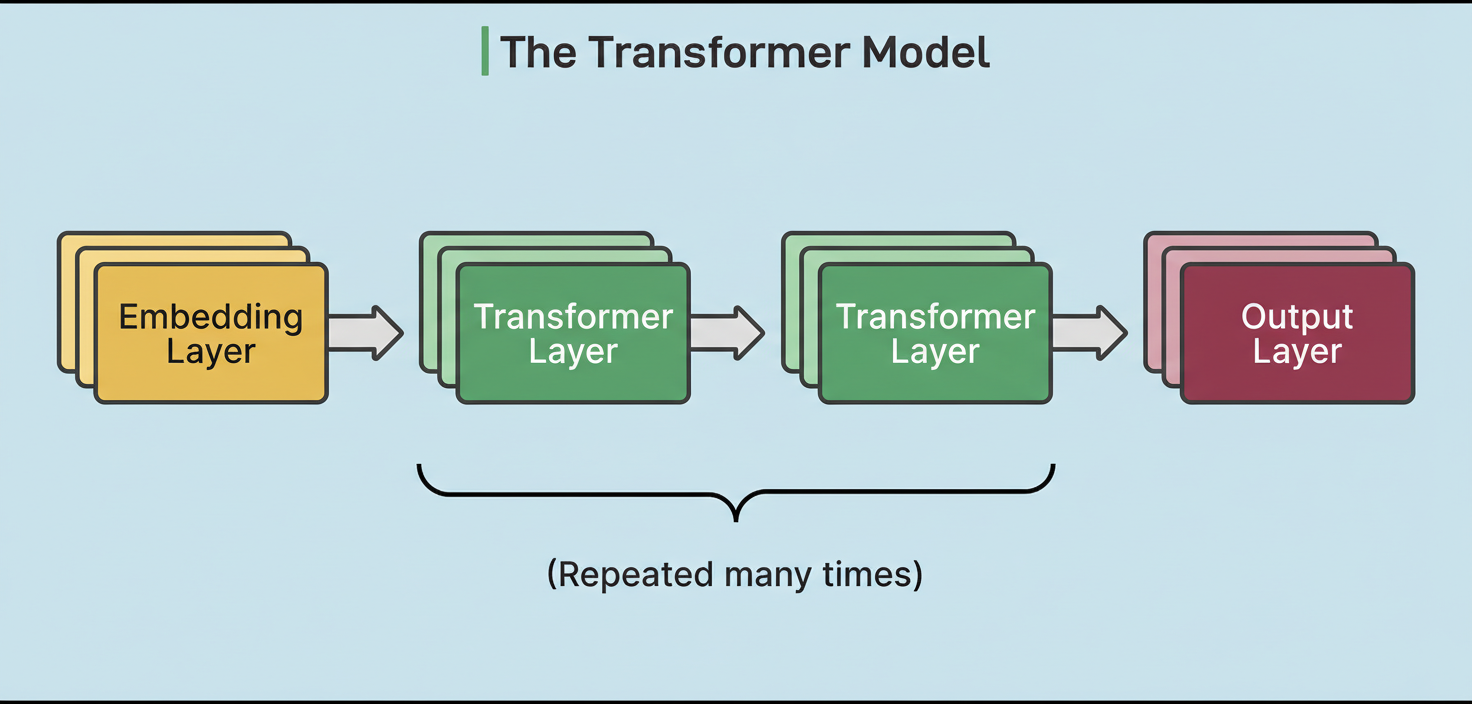
Following the retrieval of candidates from both Thunder and Phoenix’s retrieval stage, Phoenix executes a Grok-based transformer model to predict the likelihood of a user engaging with each post.
The diagram below demonstrates the concept of a transformer model:
 (URL: https://substackcdn.com/image/fetch/$s_!BnyU!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fed0a89bf-489f-4107-acd3-6f06ab73a4b4_2682x1232.png)
(URL: https://substackcdn.com/image/fetch/$s_!BnyU!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fed0a89bf-489f-4107-acd3-6f06ab73a4b4_2682x1232.png)
The transformer’s implementation is adapted from xAI’s Grok-1 open-source release, tailored for recommendation system use cases. It accepts a user’s engagement history and a batch of candidate posts as input, subsequently outputting a probability for each potential engagement action.
The Candidate Pipeline constitutes a reusable framework that outlines the architecture of the entire recommendation process.
It offers traits (equivalent to interfaces in Rust terminology) for each distinct stage within the pipeline:
The framework is engineered to run independent stages concurrently when feasible and incorporates configurable error handling. This modular architecture simplifies the process for the xAI Engineering Team to integrate new data sources or scoring models without necessitating a rewrite of the core pipeline logic.
The complete sequence executed each time a user accesses the For You feed is as follows:
The Phoenix transformer forecasts probabilities for a diverse array of user actions, including liking, replying, reposting, quoting, clicking, visiting the author’s profile, watching a video, expanding a photo, sharing, dwelling (spending time reading), following the author, marking “not interested,” blocking the author, muting the author, and reporting the post.
Each predicted probability is multiplied by a corresponding weight and then summed to yield a final score. Positive actions, such as liking, reposting, and sharing, are assigned positive weights. Conversely, negative actions like blocking, muting, and reporting carry negative weights. Consequently, if the model predicts a high likelihood of a user blocking a post’s author, that post’s score is substantially reduced. The formula is straightforward:
Final Score = sum of (weight for action * predicted probability of that action)
This multi-action prediction methodology offers greater nuance than a solitary “relevance” score, enabling the system to differentiate between content a user would find enjoyable and content they might perceive as annoying or harmful.
Five key architectural decisions are noteworthy within xAI’s recommendation system.
Firstly, instead of human determination of significant signals (such as post length, hashtag count, or time of day), the Grok-based transformer autonomously learns relevance directly from user engagement sequences. This approach streamlines data pipelines and serving infrastructure.
Secondly, during the transformer’s scoring of a batch of candidate posts, each post is designed to only “attend to” the user’s context, not to other candidates within the same batch. This design ensures that a post’s score remains independent of the other posts present in the batch, thereby promoting consistent and cacheable scores, which is crucial for operations at X’s scale.
Thirdly, both the retrieval and ranking stages incorporate multiple hash functions for efficient embedding lookup.
Fourthly, instead of consolidating all factors into a single relevance metric, the model predicts probabilities for numerous distinct actions. This empowers the Weighted Scorer with granular control over the feed’s optimization objectives.
Finally, the Candidate Pipeline framework meticulously separates the pipeline’s execution logic from the business logic inherent in individual stages. This facilitates the xAI Engineering Team in integrating new data sources, substituting different scoring models, or introducing new filters without altering the broader system.
References:
X For You Feed Algorithm
X For You Feed Algorithm (URL: https://github.com/xai-org/x-algorithm)
Transformers Architecture
Transformers Architecture (URL: https://en.wikipedia.org/wiki/Transformer_(deep_learning))
Introduction to Grok
Introduction to Grok (URL: https://en.wikipedia.org/wiki/Grok_(chatbot))